Fonctionnalités
- Recherche sur le web et récupération du contenu complet des pages
- Extraction de n’importe quelle URL en données structurées propres
- Analyse de fichiers locaux tels que des PDF, DOCX, XLSX et HTML
- Interaction avec les pages — cliquer, naviguer et effectuer des actions
- Recherche approfondie avec agent autonome
- Prise en charge du cloud et de l’auto‑hébergement
- Prise en charge de l’HTTP en streaming
Installation
Pas de clé API ? Connectez-vous à
https://mcp.firecrawl.dev/v2/mcp pour utiliser l’offre gratuite distante sans clé. Ce service est gratuit et soumis à une limite de débit par IP ; consultez Limite de débit pour connaître la liste actuelle des outils sans clé. Définissez FIRECRAWL_API_KEY pour activer tous les outils MCP ainsi que des limites plus élevées.URL hébergée à distance
Authorization pour déverrouiller tous les outils et bénéficier de limites plus élevées :
Exécution via npx
Installation manuelle
Utilisation avec Cursor
 Ou ajoutez-le manuellement à
Ou ajoutez-le manuellement à ~/.cursor/mcp.json :
Exécution locale avec une clé API
- Ouvrez les paramètres de Cursor
- Allez dans Features > MCP Servers
- Cliquez sur ”+ Add new global MCP server”
- Saisissez le code suivant :
- Ouvrez les paramètres de Cursor
- Allez dans Features > MCP Servers
- Cliquez sur ”+ Add New MCP Server”
- Renseignez les éléments suivants :
- Name: “firecrawl-mcp” (ou le nom de votre choix)
- Type: “command”
- Command:
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp
Si vous utilisez Windows et rencontrez des problèmes, essayez cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
Remplacez your-api-key par votre clé API Firecrawl. Si vous n’en avez pas encore, créez un compte et récupérez-la via https://www.firecrawl.dev/app/api-keys
Après l’ajout, actualisez la liste des serveurs MCP pour voir les nouveaux outils. Le Composer Agent utilisera automatiquement Firecrawl MCP lorsque c’est pertinent, mais vous pouvez aussi le demander explicitement en décrivant vos besoins en données web. Accédez au Composer via Command+L (Mac), sélectionnez « Agent » à côté du bouton d’envoi, puis saisissez votre requête.
Exécuter sur Windsurf
./codeium/windsurf/model_config.json :
Exécution avec le mode HTTP en streaming
stdio par défaut :
Installation via Smithery (ancienne méthode)
Utilisation avec VS Code
Ctrl + Shift + P et en tapant Preferences: Open User Settings (JSON).
.vscode/mcp.json dans votre espace de travail. Cela vous permettra de partager la configuration avec d’autres :
Utilisation avec Claude Desktop
spawn npx ENOENT, Node.js n’est pas installé ou ne figure pas dans le PATH de votre système. Installez Node.js depuis nodejs.org (version LTS), puis redémarrez complètement Claude Desktop. Sous Windows, vous pouvez également exécuter where npx dans l’Invite de commandes et utiliser le chemin complet (par ex. C:\\Program Files\\nodejs\\npx.cmd) comme valeur de command.
Utilisation avec Claude Code
Utilisation avec Google Antigravity
- Ouvrez la barre latérale Agent dans l’Editor ou la vue Agent Manager
- Cliquez sur le menu « … » (More Actions) et sélectionnez MCP Servers
- Sélectionnez View raw config pour ouvrir votre fichier local
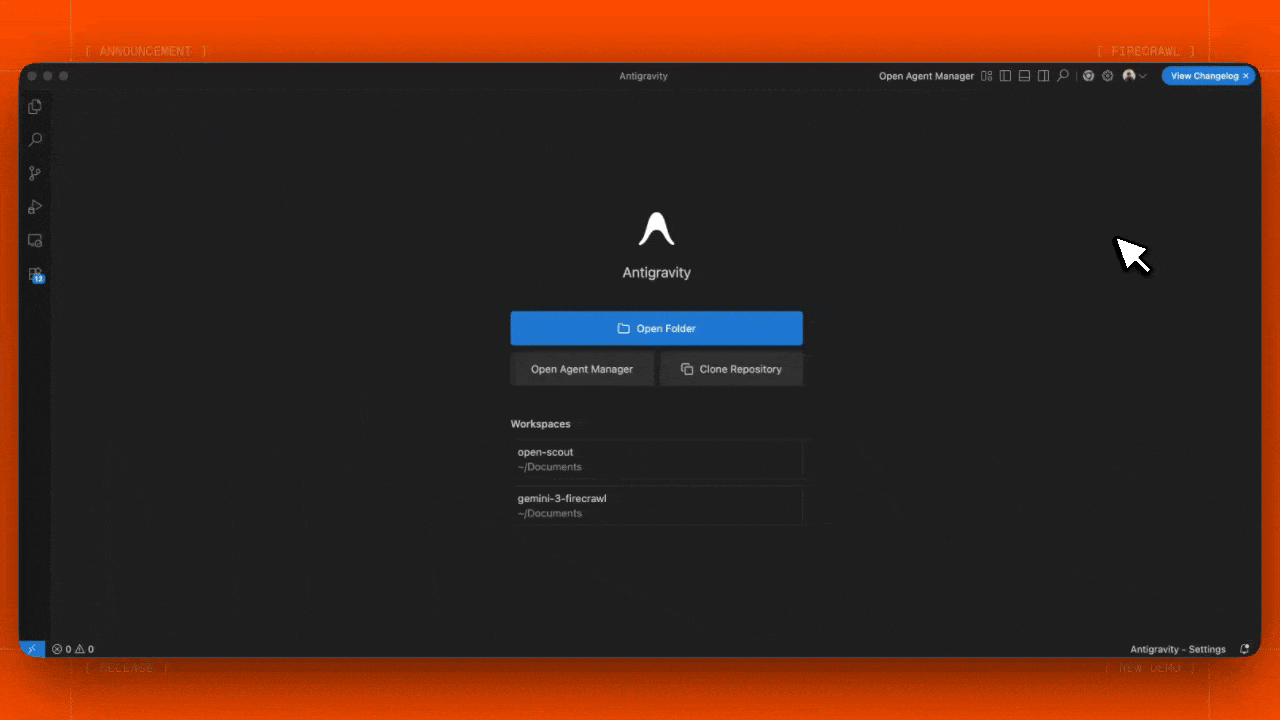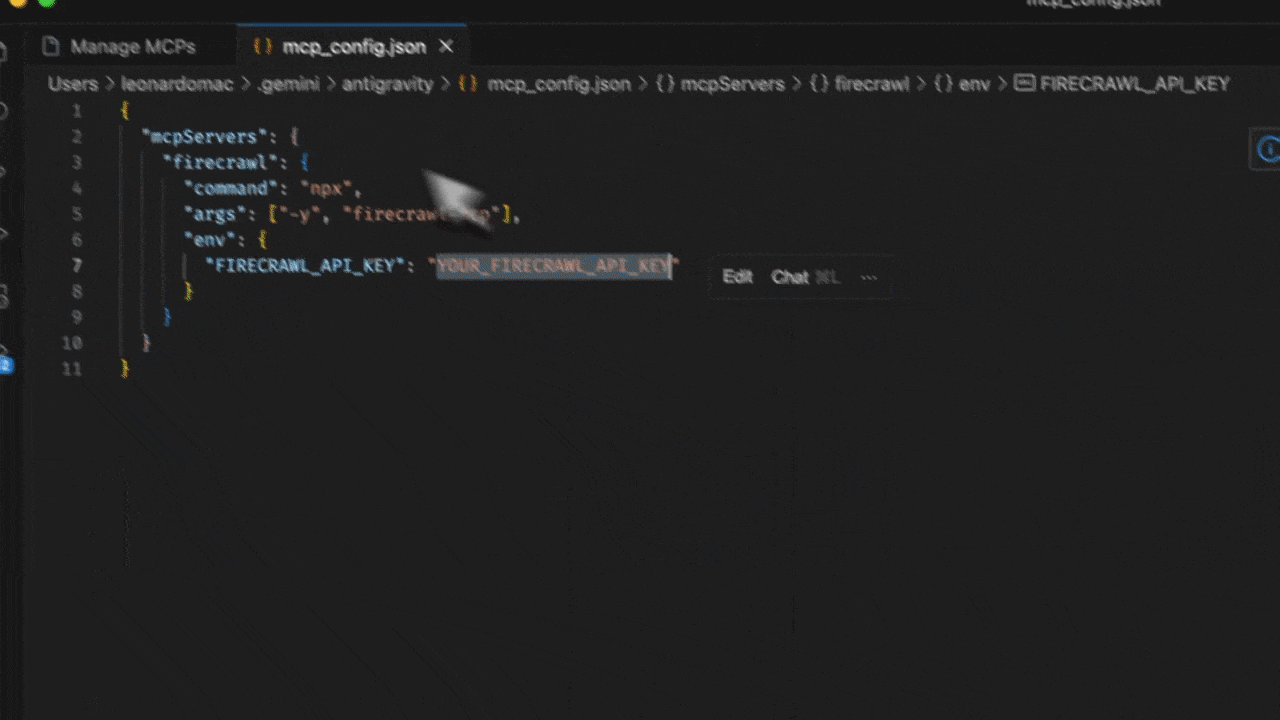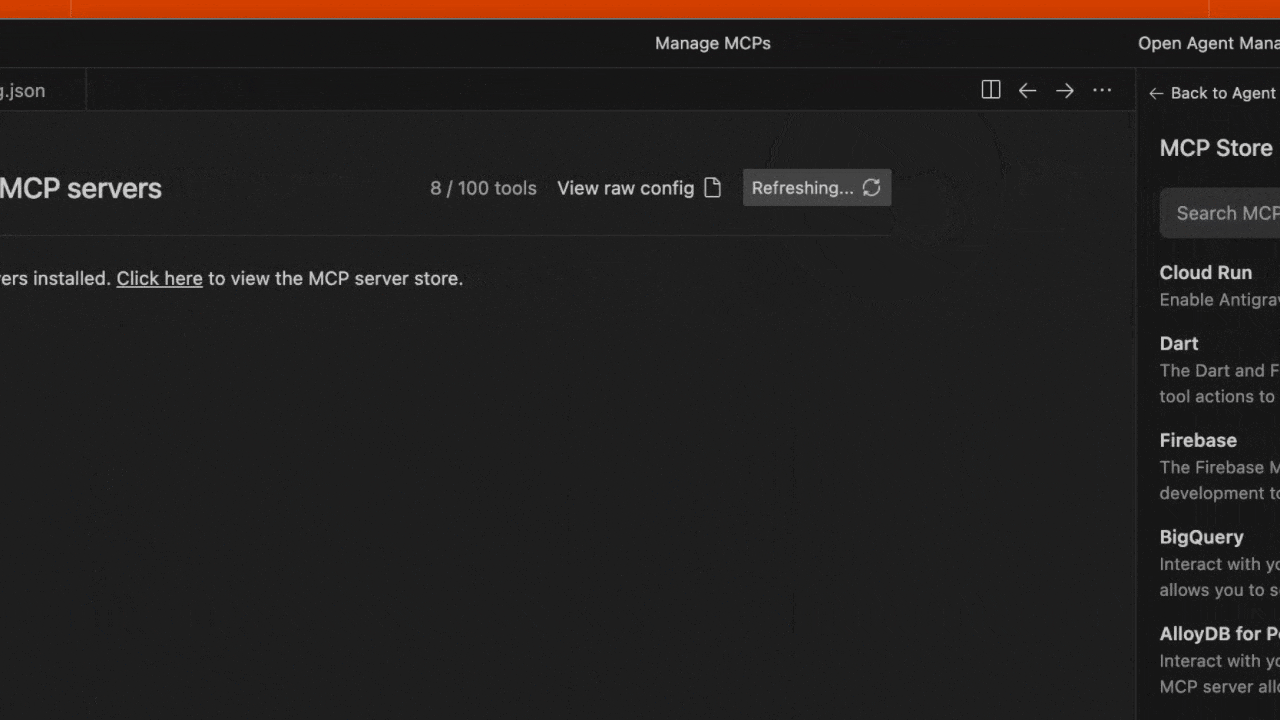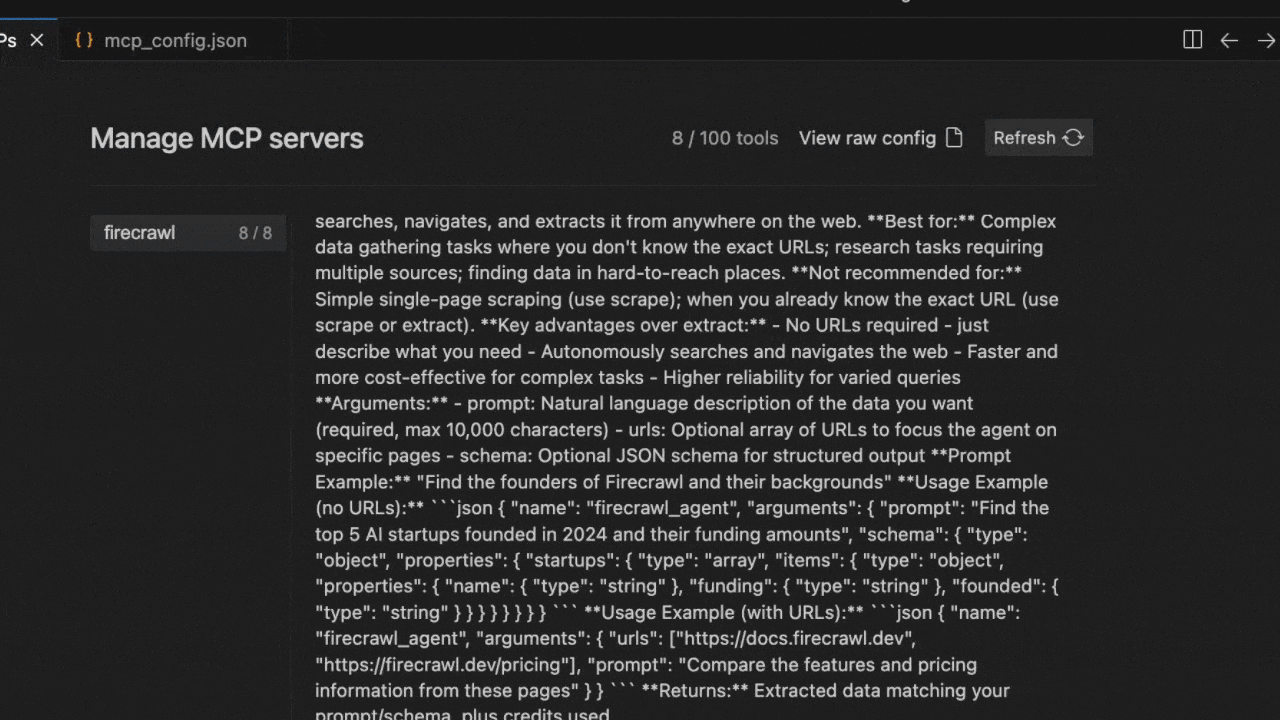
mcp_config.json - Ajoutez la configuration suivante :
- Enregistrez le fichier et cliquez sur Refresh dans l’interface MCP d’Antigravity pour voir les nouveaux outils.
YOUR_FIRECRAWL_API_KEY par votre clé API à partir de https://firecrawl.dev/app/api-keys.
Utilisation avec n8n
- Récupérez votre clé API Firecrawl à partir de https://firecrawl.dev/app/api-keys
- Dans votre workflow n8n, ajoutez un nœud AI Agent
- Dans la configuration du nœud AI Agent, ajoutez un nouveau Tool
- Sélectionnez MCP Client Tool comme type d’outil
- Saisissez l’Endpoint du serveur MCP :
- Définissez Server Transport sur HTTP Streamable
- Définissez Authentication sur Bearer et collez votre clé API Firecrawl, ou laissez None pour utiliser le palier gratuit sans clé
- Pour Tools to include, vous pouvez sélectionner All, Selected ou All Except – cela rendra disponibles les outils Firecrawl (scrape, crawl, map, search, extract, etc.)
http://localhost:3000/v2/mcp, que vous pouvez utiliser comme endpoint dans votre workflow n8n. La variable d’environnement HTTP_STREAMABLE_SERVER=true est requise, car n8n a besoin d’un transport via HTTP.
Configuration
Variables d’environnement
API cloud et auto-hébergée
FIRECRAWL_API_KEY: votre clé API Firecrawl- Requise lors de l’utilisation de l’API cloud (par défaut)
- Facultative lors de l’utilisation d’une instance auto-hébergée avec
FIRECRAWL_API_URL
FIRECRAWL_API_URL(facultatif) : point de terminaison API personnalisé pour les instances auto-hébergées- Exemple :
https://firecrawl.your-domain.com - Si elle n’est pas renseignée, l’API cloud sera utilisée (nécessite une clé API)
- Exemple :
Exemples de configuration
Configuration personnalisée avec Claude Desktop
claude_desktop_config.json :
MCP hébergé vs MCP local
- Le mode keyless hébergé n’expose que les outils pris en charge en mode keyless et est soumis à une limitation de débit par IP.
- La lecture de fichiers locaux n’est disponible que lorsque vous exécutez le serveur MCP localement.
- Les Webhooks et les chemins de fichiers locaux doivent être configurés à partir d’un serveur MCP local ou self-hosted lorsque l’agent doit accéder à des ressources locales.
Limites de débit
Outils disponibles
1. Outil de scraping (firecrawl_scrape)
redactPII dans les arguments de l’outil de scraping.
2. Outil de cartographie (firecrawl_map)
Options de l’outil Map :
url: L’URL de base du site web à cartographiersearch: Terme de recherche facultatif pour filtrer les URLsitemap: Contrôle l’utilisation du sitemap : « include », « skip » ou « only »includeSubdomains: Indique s’il faut inclure les sous-domaines dans la cartographielimit: Nombre maximal d’URL à retournerignoreQueryParameters: Indique s’il faut ignorer les paramètres de requête lors de la cartographie
3. Outil de recherche (firecrawl_search)
Options de l’outil de recherche :
query: chaîne de requête de recherche (obligatoire)limit: nombre maximal de résultats à retournerlocation: emplacement géographique pour les résultats de recherchetbs: filtre temporel de recherche (par exemple,qdr:dpour les dernières 24 heures,qdr:wpour la dernière semaine,qdr:mpour le dernier mois)filter: filtre de recherche supplémentairesources: tableau des types de sources à interroger (web,images,news)scrapeOptions: options de scraping des pages de résultats de rechercheenterprise: tableau d’options d’entreprise (default,anon,zdr)
4. Outil de parsing (firecrawl_parse)
FIRECRAWL_API_URL, le serveur MCP peut lire directement filePath et envoie les octets du fichier à /v2/parse.
Lorsque vous utilisez le serveur MCP distant hébergé, celui-ci ne peut pas lire les fichiers de votre machine. Dans ce cas, firecrawl_parse utilise un transfert en deux étapes qui fonctionne également avec l’URL distante sans clé :
- Appelez
firecrawl_parseavecfilePath. L’outil renvoie une commande d’upload préremplie et unnextToolCallcontenant unuploadRef. - Exécutez la commande d’upload sur la machine qui peut lire le fichier, puis appelez à nouveau
firecrawl_parseavec l’uploadRefrenvoyé.
Options de l’outil de parsing :
filePath: Chemin local vers le fichier que vous souhaitez analyser. À utiliser pour le premier appel.uploadRef: Référence renvoyée par le premier appel hosted-MCP. À utiliser pour le second appel une fois le téléversement terminé.formats: Formats de sortie. Valeur par défaut :markdown.parsers: Paramètres du parseur, comme les options d’analyse PDF.contentType: Remplacement facultatif du type MIME du fichier.declaredSizeBytes: Indication facultative de la taille du fichier. Les fichiers sont limités à 50 Mo.
firecrawl_scrape ; il détectera et analysera les documents à partir des URL.
5. Outil de crawl (firecrawl_crawl)
6. Vérifier l’état du crawl (firecrawl_check_crawl_status)
7. Outil d’extraction (firecrawl_extract)
Options de l’outil d’extraction :
urls: Liste d’URL à partir desquelles extraire des informationsprompt: Prompt personnalisé pour l’extraction par le LLMschema: Schéma JSON pour l’extraction de données structuréesallowExternalLinks: Autoriser l’extraction à partir de liens externesenableWebSearch: Activer la recherche sur le web pour obtenir un contexte supplémentaireincludeSubdomains: Inclure les sous-domaines dans l’extraction
8. Outil Agent (firecrawl_agent)
firecrawl_agent_status pour savoir quand il est terminé et récupérer les résultats.
Options de l’Agent Tool :
prompt: Description en langage naturel des données dont vous avez besoin (obligatoire, 10 000 caractères maximum)urls: Tableau optionnel d’URL pour concentrer l’agent sur des pages spécifiquesschema: Schéma JSON optionnel pour une sortie structurée
firecrawl_agent_status pour interroger les résultats.
9. Vérifier le statut de l’agent (firecrawl_agent_status)
Options de statut de l’agent :
id: L’ID de tâche d’agent renvoyé parfirecrawl_agent(obligatoire)
processing: L’agent est encore en cours de recherche — continuer à interrogercompleted: Recherche terminée — la réponse inclut les données extraitesfailed: Une erreur s’est produite
10. Interagir avec une page (firecrawl_interact)
- Passez
urlpour ouvrir une nouvelle page et interagir avec elle en un seul appel MCP. - Passez
scrapeIddepuis un appelfirecrawl_scrapeprécédent pour réutiliser la page déjà chargée.
url et scrapeId. Fournissez soit prompt, soit code. scrapeOptions ne peut être utilisé qu’en mode url.
Exemple en mode URL :
Options de l’outil Interact :
url: Page avec laquelle interagir ; ouvre la session pour vous. Utilisez ceci ouscrapeId.scrapeId: L’ID de tâche d’une tâche de scraping issue d’un appel précédent àfirecrawl_scrape. Utilisez ceci ouurl.prompt: Instruction en langage naturel décrivant l’action à effectuer. Fournissezpromptoucode.code: Code à exécuter dans la session de navigateur. Fournissezcodeouprompt.language:bash,pythonounode(facultatif, valeur par défaut :node, utilisé uniquement aveccode).timeout: Délai d’exécution maximal, en secondes, de 1 à 300 (facultatif, valeur par défaut : 30).scrapeOptions: Options de scraping facultatives, utilisées uniquement avec le modeurl.
11. Arrêter une session Interact (firecrawl_interact_stop)
Options d’arrêt d’Interact :
scrapeId: l’ID du scrape de la session à arrêter (obligatoire)
Système de journalisation
- État et progression des opérations
- Indicateurs de performance
- Suivi de l’utilisation des crédits
- Suivi des limites de débit
- Conditions d’erreur
Gestion des erreurs
- Nouveaux essais automatiques en cas d’erreurs transitoires
- Gestion des limites de débit avec backoff
- Messages d’erreur détaillés
- Alertes sur l’utilisation des crédits
- Résilience du réseau
Développement
Contribution
- Créez un fork du dépôt
- Créez une branche pour votre fonctionnalité
- Exécutez les tests :
npm test - Ouvrez une pull request