功能
- 进行网页搜索并获取完整页面内容
- 从任意 URL 抓取干净、结构化的数据
- 解析 PDF、DOCX、XLSX 和 HTML 等本地文件
- 与页面交互 — 点击、导航和操作
- 借助自主代理进行深度研究
- 支持云端与自托管
- 支持 HTTP 流式传输
安装
没有 API 密钥? 连接到
https://mcp.firecrawl.dev/v2/mcp 即可使用远程免密钥免费档位。它是免费的,并且会按 IP 限流;当前免密钥工具列表请参见 Rate Limits。设置 FIRECRAWL_API_KEY 即可解锁所有 MCP 工具和更高的限额。远程托管 URL
Authorization 请求头发送,以解锁所有工具并享有更高限额:
使用 npx 运行
手动安装
在 Cursor 上运行
 或手动将其添加到
或手动将其添加到 ~/.cursor/mcp.json:
使用 API 密钥在本地运行
- Open Cursor Settings
- Go to Features > MCP Servers
- Click ”+ Add new global MCP server”
- Enter the following code:
- Open Cursor Settings
- Go to Features > MCP Servers
- Click ”+ Add New MCP Server”
- Enter the following:
- Name: “firecrawl-mcp” (或你偏好的名称)
- Type: “command”
- Command:
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp
If you are using Windows and are running into issues, try cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
将 your-api-key 替换为你的 Firecrawl API 密钥。如果你还没有,可以创建账号并从 https://www.firecrawl.dev/app/api-keys 获取。
添加后,刷新 MCP 服务器列表以查看新工具。Composer 代理会在合适的情况下自动使用 Firecrawl MCP,但你也可以通过描述你的网页数据需求来显式请求。通过 Command+L (Mac) 打开 Composer,在提交按钮旁选择 “Agent”,然后输入你的查询。
在 Windsurf 上运行
./codeium/windsurf/model_config.json:
以流式 HTTP 模式运行
通过 Smithery 安装 (旧版)
在 VS Code 中运行
Ctrl + Shift + P,然后输入 Preferences: Open User Settings (JSON) 来完成此操作。
.vscode/mcp.json 文件中。这样你就可以与他人共享该配置:
在 Claude Desktop 上运行
npx 方案 (需要 Node.js) :
spawn npx ENOENT 错误,说明 Node.js 未安装或未加入系统 PATH。请从 nodejs.org 安装 Node.js (LTS 版本) ,然后彻底重启 Claude Desktop。在 Windows 上,你也可以在命令提示符中运行 where npx,并将完整路径 (例如 C:\\Program Files\\nodejs\\npx.cmd) 作为 command 的值。
在 Claude Code 上运行
在 Google Antigravity 上运行
- 在 Editor 或 Agent Manager 视图中打开 Agent 侧边栏
- 点击 ”…” (More Actions 更多操作) 菜单并选择 MCP Servers
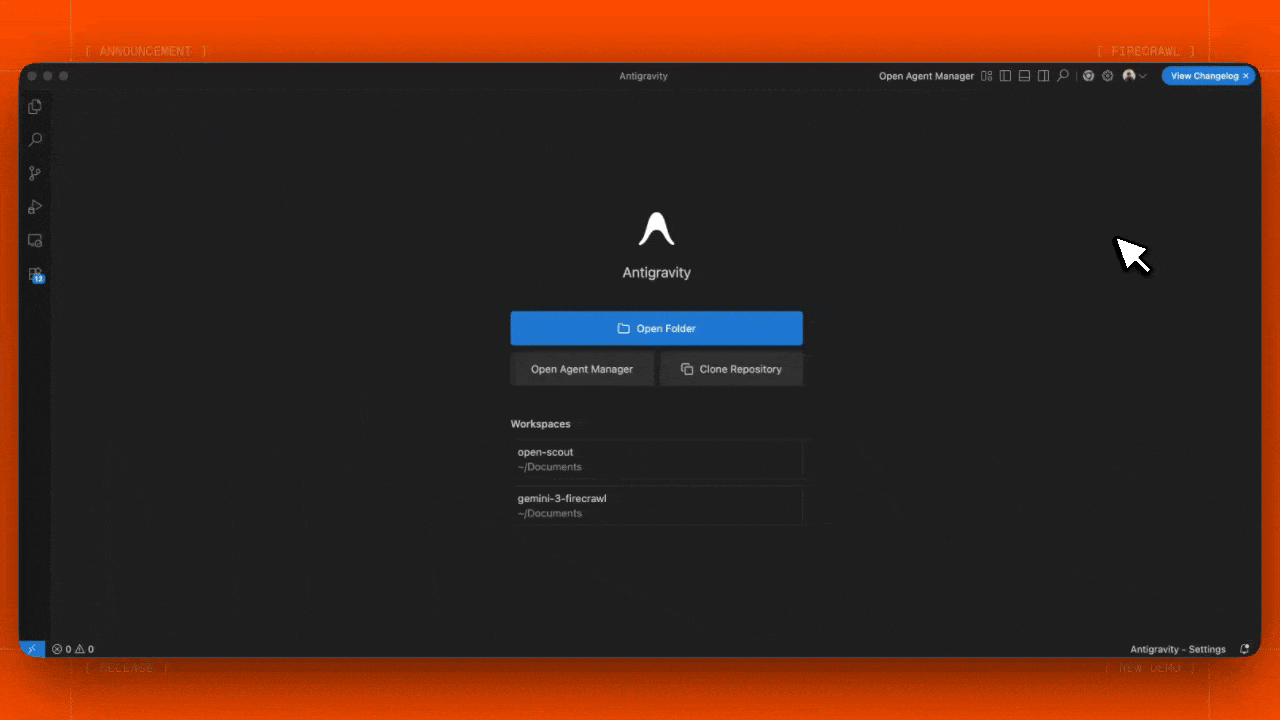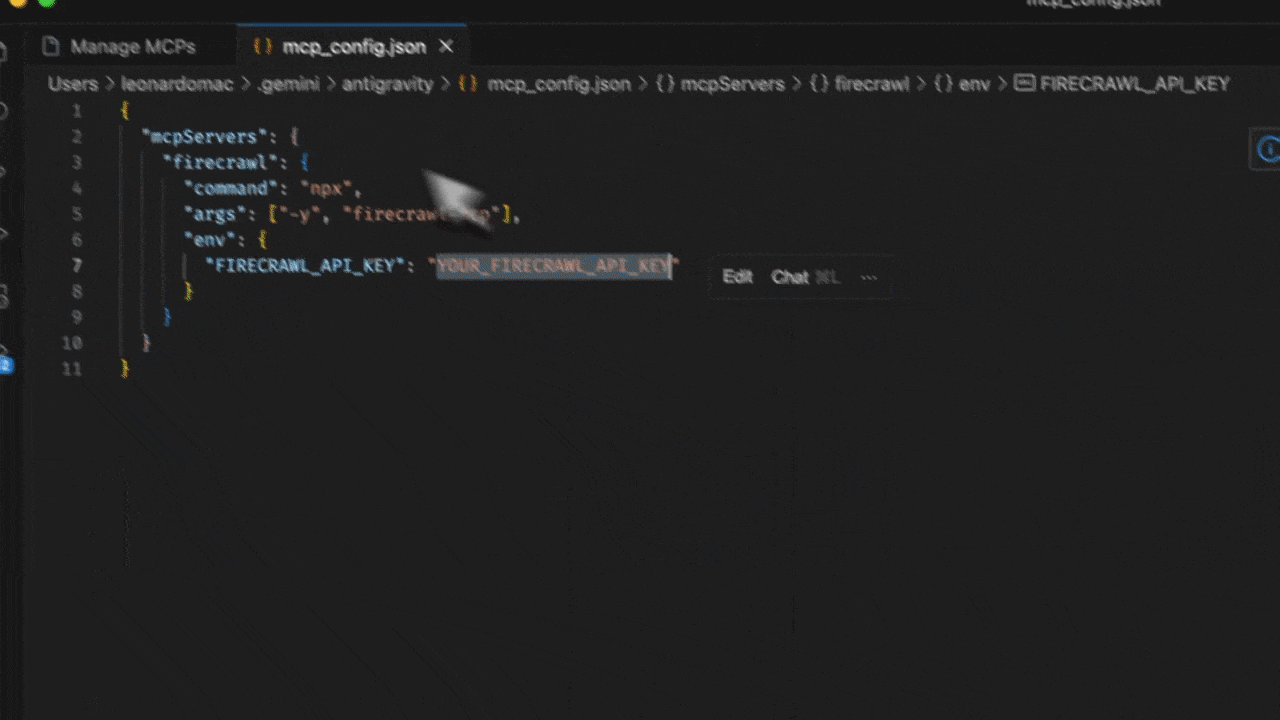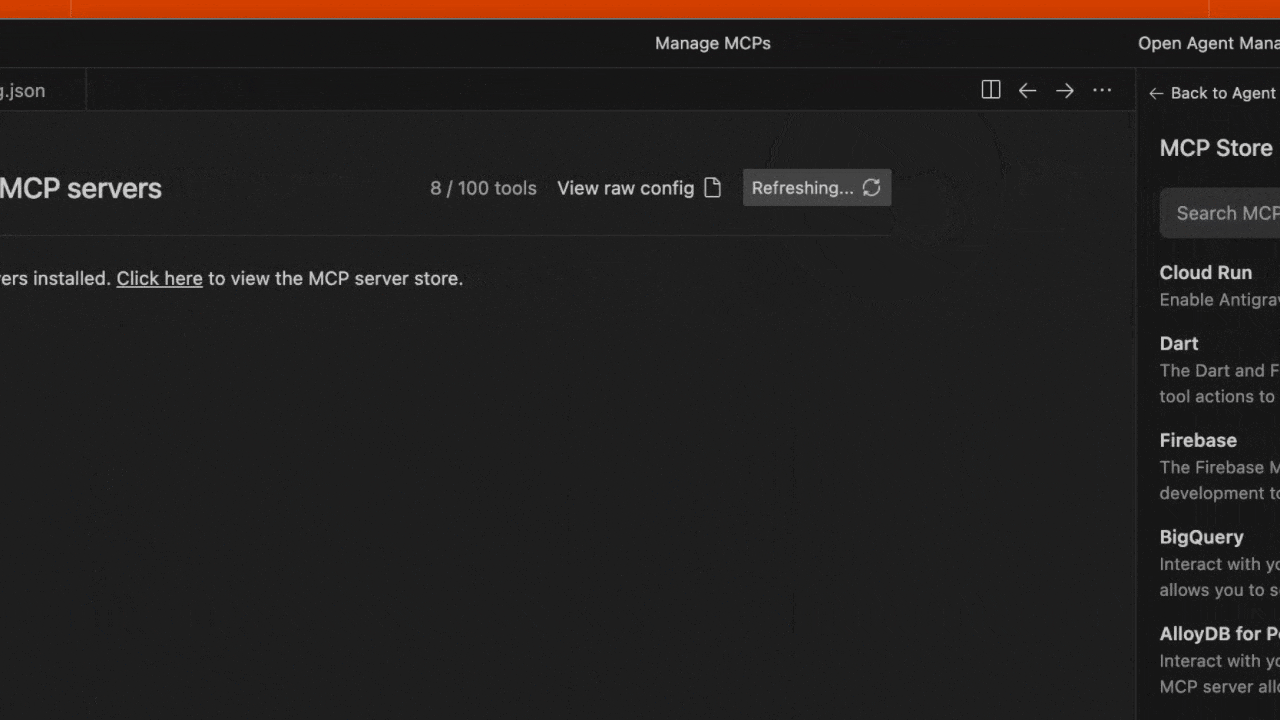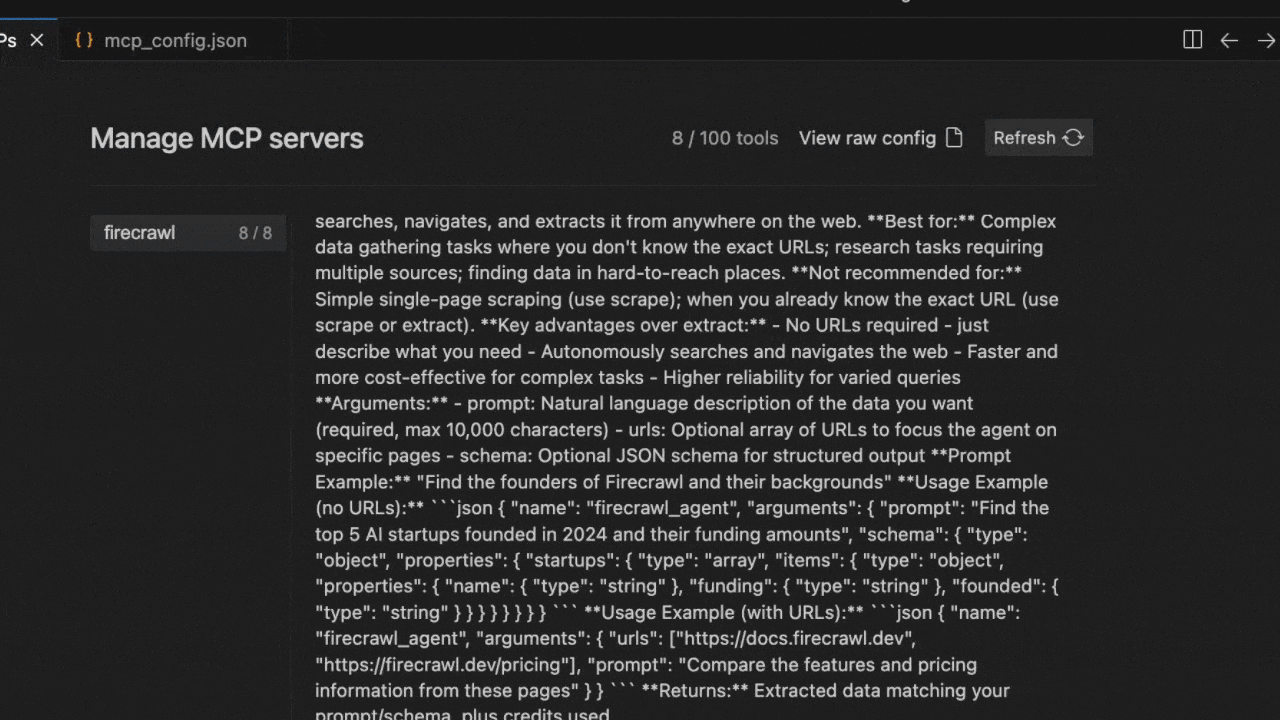
- 选择 View raw config 以打开本地的
mcp_config.json文件 - 添加以下配置:
- 保存文件,然后在 Antigravity MCP 界面中点击 Refresh 以查看新工具。
YOUR_FIRECRAWL_API_KEY 替换为你在 https://firecrawl.dev/app/api-keys 获取的 API key。
在 n8n 中运行
- 在 https://firecrawl.dev/app/api-keys 获取你的 Firecrawl API 密钥
- 在你的 n8n 工作流中,添加一个 AI 代理 节点
- 在 AI 代理 配置中,添加一个新的 Tool
- 将工具类型选择为 MCP Client Tool
- 输入 MCP 服务器端点:
- 将 Server Transport 设置为 HTTP Streamable
- 将 Authentication 设置为 Bearer,然后粘贴你的 Firecrawl API 密钥;或者保留为 None 以使用免密钥免费档位
- 在 Tools to include 中,你可以选择 All、Selected 或 All Except —— 这会提供对 Firecrawl 工具 (scrape、crawl、map、search、extract 等) 的访问
http://localhost:3000/v2/mcp 上启动服务器,你可以在 n8n 工作流中将其用作端点。需要设置环境变量 HTTP_STREAMABLE_SERVER=true,因为 n8n 需要使用 HTTP 传输。
配置
环境变量
云端和自托管 API
FIRECRAWL_API_KEY:你的 Firecrawl API 密钥- 使用云端 API (默认) 时必需
- 在使用并配置了
FIRECRAWL_API_URL的自托管实例时可选
FIRECRAWL_API_URL(可选) :自托管实例的自定义 API 端点- 示例:
https://firecrawl.your-domain.com - 如未提供,将使用云端 API (需要提供 API 密钥)
- 示例:
配置示例
在 Claude Desktop 中进行自定义配置
claude_desktop_config.json 中:
托管式 MCP 与本地 MCP
- 托管式免密钥模式仅开放免密钥支持的工具,并按 IP 实施速率限制。
- 仅限本地的文件读取功能只有在你本地运行 MCP 服务器时才可用。
- 当代理需要访问本地资源时,应通过本地或自托管 MCP 服务器配置 Webhook 和本地文件路径。
限流
可用的工具
1. Scrape 工具 (firecrawl_scrape)
redactPII。
2. Map Tool (firecrawl_map)
Map 工具选项:
url: 要映射的网站基础 URLsearch: 可选搜索词,用于过滤 URLsitemap: 控制 sitemap 的使用方式 —— “include”、“skip” 或 “only”includeSubdomains: 映射时是否包含子域名limit: 要返回的 URL 最大数量ignoreQueryParameters: 映射时是否忽略查询参数
3. 搜索工具 (firecrawl_search)
搜索工具选项:
query:搜索查询字符串 (必需)limit:返回结果的最大数量location:搜索结果的地理位置tbs:按时间过滤的搜索参数 (例如,qdr:d表示过去一天,qdr:w表示过去一周,qdr:m表示过去一个月)filter:额外的搜索过滤条件sources:要搜索的来源类型数组 (web、images、news)scrapeOptions:抓取搜索结果页面时的配置选项enterprise:企业相关选项数组 (default、anon、zdr)
4. 解析工具 (firecrawl_parse)
FIRECRAWL_API_URL 在本地运行 Firecrawl MCP 并连接到 Firecrawl API 实例时,MCP 服务器 可以直接读取 filePath,并将文件字节发送到 /v2/parse。
当你使用远程托管的 MCP 服务器 时,托管服务器无法读取你本机上的文件。在这种情况下,firecrawl_parse 会使用一个同样适用于远程免密钥 URL 的两步交接流程:
- 使用
filePath调用firecrawl_parse。该工具会返回一条预先填好的上传命令,以及一个包含uploadRef的nextToolCall。 - 在能够读取该文件的机器上运行上传命令,然后使用返回的
uploadRef再次调用firecrawl_parse。
解析工具选项:
filePath:要解析文件的本地路径。首次调用时使用此项。uploadRef:首次托管 MCP 调用返回的引用。上传成功后,第二次调用时使用此项。formats:输出格式。默认值为markdown。parsers:解析器控制选项,例如 PDF 解析选项。contentType:可选的文件 MIME 类型覆盖设置。declaredSizeBytes:可选的文件大小提示。文件大小上限为 50 MB。
firecrawl_scrape;它会自动检测并解析 URL 对应的文档。
5. Crawl Tool (firecrawl_crawl)
6. 检查爬取状态 (firecrawl_check_crawl_status)
7. 提取工具 (firecrawl_extract)
Extract 工具选项:
urls: 要从中提取信息的 URL 数组prompt: 用于 LLM 提取的自定义提示词schema: 用于结构化数据提取的 JSON schemaallowExternalLinks: 是否允许从外部链接提取enableWebSearch: 是否启用 Web 搜索以获取额外上下文includeSubdomains: 提取时是否包含子域名
8. Agent Tool (firecrawl_agent)
firecrawl_agent_status 以检查任务何时完成并获取结果。
Agent 工具选项:
prompt: 对所需数据的自然语言描述 (必填,最多 10,000 个字符)urls: 可选的 URL 数组,用于让 agent 聚焦在特定页面schema: 可选的 JSON schema,用于结构化输出
firecrawl_agent_status 轮询获取结果。
9. 检查 Agent 状态 (firecrawl_agent_status)
Agent 状态选项:
id:firecrawl_agent返回的 Agent 任务 ID (必需)
processing: Agent 仍在执行任务 —— 继续轮询completed: 任务已完成 —— 响应中包含提取的数据failed: 发生错误
10. 与页面交互 (firecrawl_interact)
- 传入
url,即可在一次 MCP 调用中打开一个新页面并与之交互。 - 传入之前
firecrawl_scrape调用返回的scrapeId,即可复用已加载的页面。
url 和 scrapeId。请提供 prompt 或 code 二者之一。scrapeOptions 只能在 url 模式下使用。
URL 模式示例:
交互工具选项:
url:要交互的页面;会为你打开会话。使用此项或scrapeId。
scrapeId:先前firecrawl_scrape调用返回的抓取任务 ID。使用此项或url。prompt:用于描述要执行操作的自然语言指令 (提供prompt或code)code:在浏览器会话中执行的代码 (提供code或prompt)language:bash、python或node(可选,默认值为node,仅在使用code时生效)timeout:执行超时时间 (秒) ,1–300 (可选,默认值为 30)
scrapeOptions:仅在url模式下使用的可选抓取控制选项。
11. 停止交互会话 (firecrawl_interact_stop)
交互停止选项:
scrapeId:要停止的会话的 scrape ID (必填)
日志系统
- 操作状态与进度
- 性能指标
- 额度使用监控
- 速率限制跟踪
- 错误情况
错误处理
- 对临时性错误进行自动重试
- 带退避策略的限流处理
- 详细的错误信息
- 额度使用预警
- 网络健壮性
开发
参与贡献
- Fork 本仓库
- 创建你的功能分支
- 运行测试:
npm test - 提交一个 Pull Request