Recursos
- Fazer uma busca na web e obter o conteúdo completo da página
- Fazer scraping de qualquer URL para obter dados estruturados limpos
- Processar arquivos locais, como PDFs, DOCX, XLSX e HTML
- Interagir com páginas — clicar, navegar e executar ações
- Pesquisa avançada com agente autônomo
- Suporte em nuvem e auto-hospedado
- Suporte a HTTP com streaming
Instalação
Sem chave de API? Conecte-se a
https://mcp.firecrawl.dev/v2/mcp para usar o plano gratuito remoto sem chave. É gratuito e tem limite de taxa por IP; veja limite de taxa para a lista atual de ferramentas sem chave. Defina FIRECRAWL_API_KEY para desbloquear todas as ferramentas do MCP e limites mais altos.URL hospedada remotamente
Authorization para desbloquear todas as ferramentas, além de limites maiores:
Executando com npx
Instalação manual
Executando no Cursor
 Ou adicione-o manualmente ao
Ou adicione-o manualmente ao ~/.cursor/mcp.json:
Executando localmente com uma chave de API
- Abra as Configurações do Cursor
- Vá em Features > MCP Servers
- Clique ”+ Add new global MCP server”
- Enter the following code:
- Abra as Configurações do Cursor
- Vá em Features > MCP Servers
- Clique ”+ Add New MCP Server”
- Insira o seguinte:
- Name: “firecrawl-mcp” (ou o nome de sua preferência)
- Type: “command”
- Command:
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp
Se você estiver no Windows e tiver problemas, tente cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
Substitua your-api-key pela sua chave de API do Firecrawl. Se você ainda não tiver uma, crie uma conta e obtenha-a em https://www.firecrawl.dev/app/api-keys
Após adicionar, atualize a lista de servidores MCP para ver as novas ferramentas. O Composer Agent usará automaticamente o Firecrawl MCP quando apropriado, mas você pode solicitá-lo explicitamente descrevendo suas necessidades de dados da web. Acesse o Composer com Command+L (Mac), selecione “Agent” ao lado do botão de envio e insira sua consulta.
Executando no Windsurf
./codeium/windsurf/model_config.json:
Executando no modo HTTP com streaming
stdio padrão:
Instalação via Smithery (legado)
Executando no VS Code
Ctrl + Shift + P e digitando Preferences: Open User Settings (JSON).
.vscode/mcp.json no seu espaço de trabalho. Isso permitirá que você compartilhe essa configuração com outras pessoas:
Executando no Claude Desktop
spawn npx ENOENT, o Node.js não está instalado ou não está no PATH do sistema. Instale o Node.js em nodejs.org (versão LTS) e, em seguida, reinicie completamente o Claude Desktop. No Windows, você também pode executar where npx no Prompt de Comando e usar o caminho completo (por exemplo, C:\\Program Files\\nodejs\\npx.cmd) como valor de command.
Executando no Claude Code
Executando no Google Antigravity
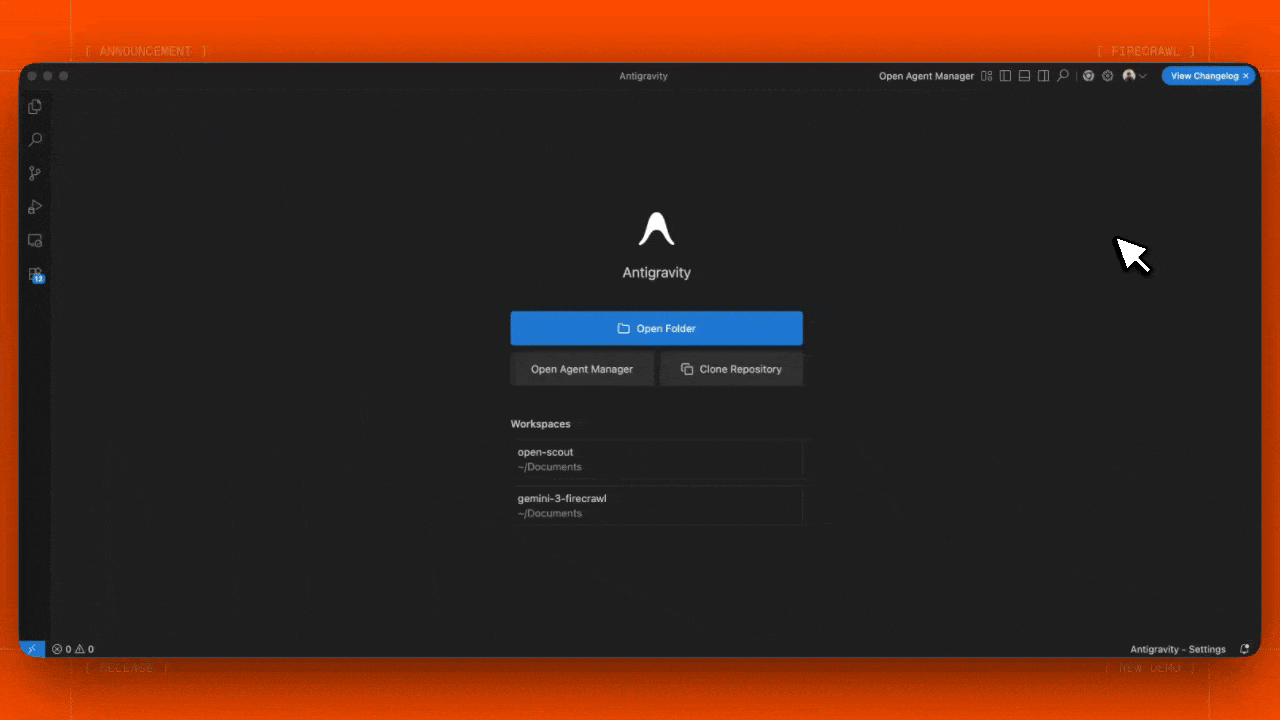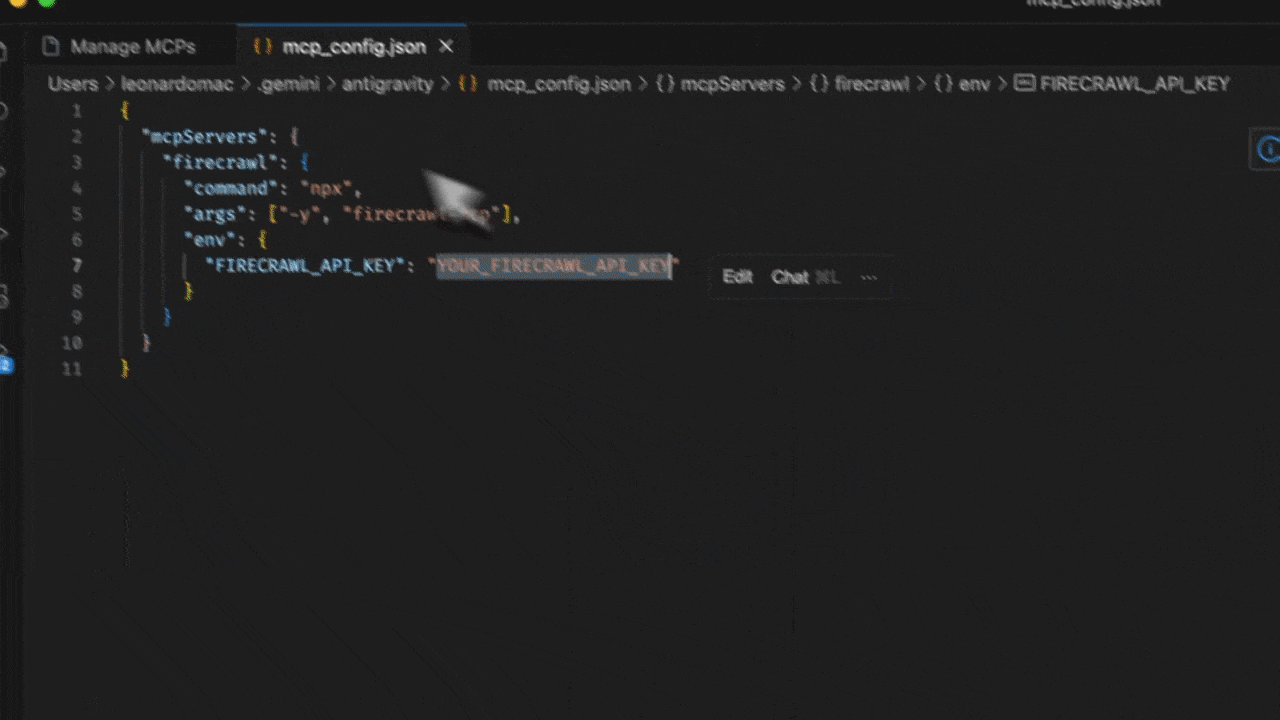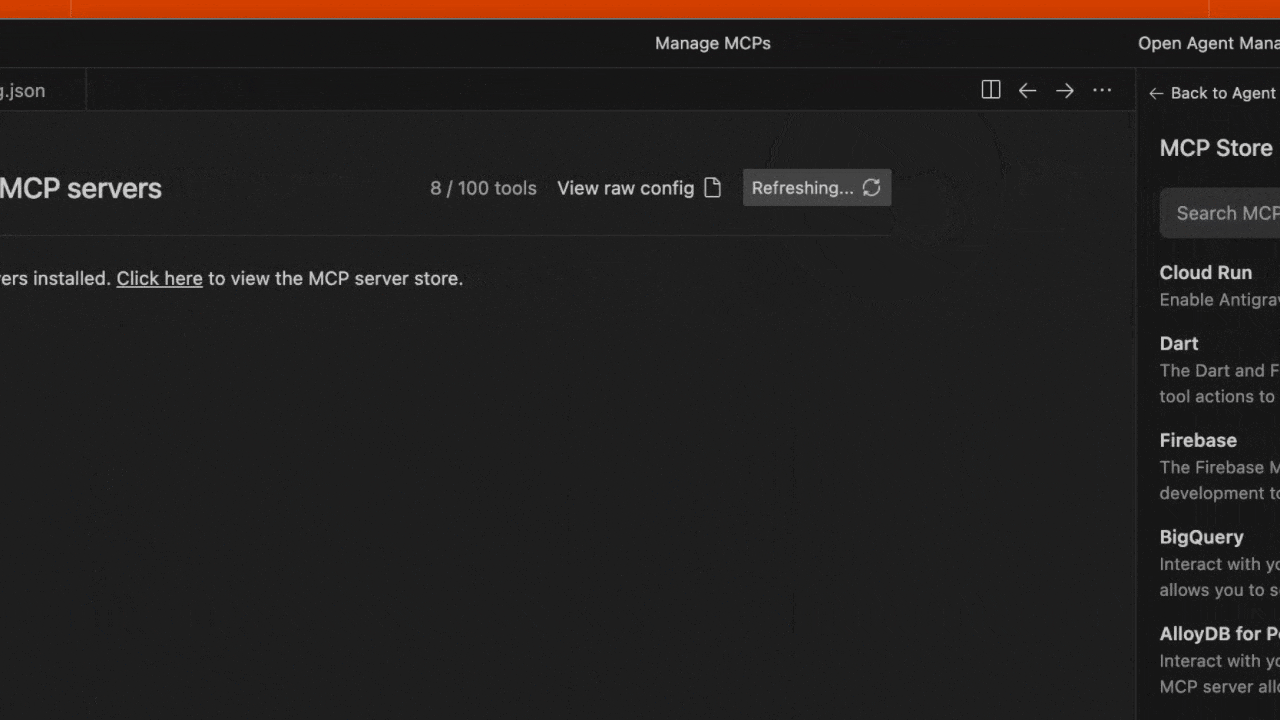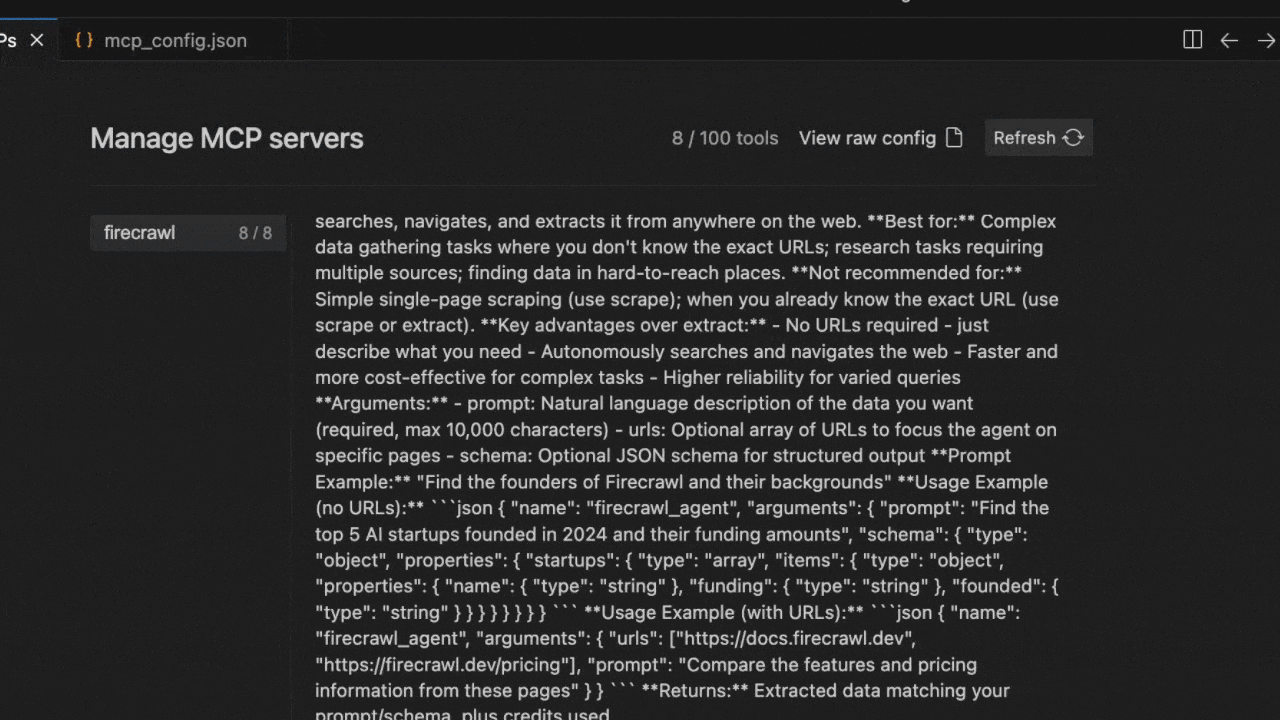
- Abra a barra lateral do Agent no Editor ou na visualização Agent Manager
- Clique no menu ”…” (More Actions) e selecione MCP Servers
- Selecione View raw config para abrir o arquivo local
mcp_config.json - Adicione a seguinte configuração:
- Salve o arquivo e clique em Refresh na interface Antigravity MCP para ver as novas ferramentas
YOUR_FIRECRAWL_API_KEY pela sua chave de API de https://firecrawl.dev/app/api-keys.
Executando no n8n
- Obtenha sua chave de API do Firecrawl em https://firecrawl.dev/app/api-keys
- No seu fluxo de trabalho do n8n, adicione um nó AI Agent
- Na configuração do nó AI Agent, adicione uma nova Tool
- Selecione MCP Client Tool como o tipo de ferramenta
- Insira o endpoint do servidor MCP:
- Defina Server Transport como HTTP Streamable
- Defina Authentication como Bearer e cole sua chave de API do Firecrawl, ou deixe como None para usar o plano gratuito sem chave
- Em Tools to include, você pode selecionar All, Selected ou All Except – isso expõe as ferramentas do Firecrawl (scrape, crawl, map, search, extract, etc.)
http://localhost:3000/v2/mcp, que você pode usar no seu workflow do n8n como endpoint. A variável de ambiente HTTP_STREAMABLE_SERVER=true é obrigatória, já que o n8n precisa de transporte HTTP.
Configuração
Variáveis de Ambiente
API em nuvem e auto-hospedada
FIRECRAWL_API_KEY: Sua chave de API do Firecrawl- Obrigatória ao usar a API em nuvem (padrão)
- Opcional ao usar uma instância auto-hospedada com
FIRECRAWL_API_URL
FIRECRAWL_API_URL(opcional): Endpoint de API personalizado para instâncias auto-hospedadas- Exemplo:
https://firecrawl.seu-dominio.com - Se não for fornecido, a API em nuvem será usada (requer chave de API)
- Exemplo:
Exemplos de configuração
Configuração personalizada com o Claude Desktop
claude_desktop_config.json:
MCP hospedado vs MCP local
- O modo keyless hospedado expõe apenas as ferramentas compatíveis com keyless e está sujeito a limite de taxa por IP.
- A leitura de arquivos locais só está disponível quando você executa o servidor MCP localmente.
- Webhooks e caminhos de arquivos locais devem ser configurados a partir de um servidor MCP local ou auto-hospedado quando o agente precisar de acesso a recursos locais.
Limites de taxa
Ferramentas disponíveis
1. Ferramenta de scraping (firecrawl_scrape)
redactPII nos argumentos da ferramenta de scraping.
2. Ferramenta de Mapeamento (firecrawl_map)
Opções da ferramenta Map:
url: A URL base do site a ser mapeadosearch: Termo de pesquisa opcional para filtrar URLssitemap: Controla o uso do sitemap — “include”, “skip” ou “only”includeSubdomains: Se deve incluir subdomínios no mapeamentolimit: Número máximo de URLs a serem retornadasignoreQueryParameters: Se deve ignorar parâmetros de consulta ao mapear
3. Search Tool (firecrawl_search)
Opções da Search Tool:
query: A string da consulta de busca (obrigatório)limit: Número máximo de resultados a serem retornadoslocation: Localização geográfica para os resultados de buscatbs: Filtro de busca baseado em tempo (por exemplo,qdr:dpara o último dia,qdr:wpara a última semana,qdr:mpara o último mês)filter: Filtro adicional de buscasources: Array de tipos de fonte a serem pesquisados (web,images,news)scrapeOptions: Opções para scraping das páginas de resultados de buscaenterprise: Array de opções de enterprise (default,anon,zdr)
4. Ferramenta Parse (firecrawl_parse)
FIRECRAWL_API_URL, o servidor MCP pode ler filePath diretamente e envia os bytes do arquivo para /v2/parse.
Quando você usa o servidor MCP remoto hospedado, o servidor hospedado não consegue ler arquivos da sua máquina. Nesse caso, firecrawl_parse usa um fluxo em duas etapas que também funciona na URL remota sem chave:
- Chame
firecrawl_parsecomfilePath. A ferramenta retorna um comando de upload pré-preenchido e umnextToolCallcontendo umuploadRef. - Execute o comando de upload na máquina que consegue ler o arquivo e, em seguida, chame
firecrawl_parsenovamente com ouploadRefretornado.
Opções da ferramenta Parse:
filePath: Caminho local para o arquivo que você quer analisar. Use isto na primeira chamada.uploadRef: Referência retornada pela primeira chamada ao hosted-MCP. Use isto na segunda chamada, depois que o upload for concluído com sucesso.formats: Formatos de resultado. O padrão émarkdown.parsers: Controles do parser, como opções de análise de PDF.contentType: Substituição opcional do tipo MIME do arquivo.declaredSizeBytes: Indicação opcional do tamanho do arquivo. Os arquivos têm limite de 50 MB.
firecrawl_scrape em vez disso; ele detectará e analisará documentos a partir de URLs.
5. Ferramenta de Rastreamento (firecrawl_crawl)
6. Verificar status do rastreamento (firecrawl_check_crawl_status)
7. Ferramenta de extração (firecrawl_extract)
Opções da ferramenta de extração:
urls: Array de URLs das quais extrair informaçõesprompt: Prompt personalizado para a extração pelo LLMschema: Esquema JSON para extração de dados estruturadosallowExternalLinks: Permite extração a partir de links externosenableWebSearch: Habilita busca na web para contexto adicionalincludeSubdomains: Inclui subdomínios na extração
8. Agent Tool (firecrawl_agent)
firecrawl_agent_status para verificar quando for concluído e recuperar os resultados.
Opções da ferramenta de agente:
prompt: Descrição em linguagem natural dos dados que você quer (obrigatório, máx. 10.000 caracteres)urls: Array opcional de URLs para focar o agente em páginas específicasschema: Esquema JSON opcional para saída estruturada
firecrawl_agent_status para consultar os resultados periodicamente.
9. Verificar status do agente (firecrawl_agent_status)
Opções de status do agente:
id: O ID da tarefa do agente retornado porfirecrawl_agent(obrigatório)
processing: O agente ainda está pesquisando — continue consultando periodicamentecompleted: Pesquisa concluída — a resposta inclui os dados extraídosfailed: Ocorreu um erro
10. Interagir com uma página (firecrawl_interact)
- Passe
urlpara abrir e interagir com uma nova página em uma única chamada MCP. - Passe
scrapeIdde uma chamada anterior defirecrawl_scrapepara reutilizar a página já carregada.
url e scrapeId ao mesmo tempo. Forneça prompt ou code. scrapeOptions só pode ser usado no modo url.
Exemplo de modo URL:
Opções da ferramenta Interact:
url: Página com a qual interagir; abre a sessão para você. Use isto ouscrapeId.scrapeId: O ID do job de scraping de uma chamada anterior afirecrawl_scrape. Use isto ouurl.prompt: Instrução em linguagem natural que descreve a ação a ser executada. Forneçapromptoucode.code: Código a ser executado na sessão do navegador. Forneçacodeouprompt.language:bash,pythonounode(opcional, o padrão énode, usado apenas comcode).timeout: Tempo limite de execução em segundos, de 1 a 300 (opcional, o padrão é 30).scrapeOptions: Controles opcionais de scraping usados apenas no modourl.
11. Encerrar sessão de interação (firecrawl_interact_stop)
Opções para interromper a interação:
scrapeId: O ID do scraping da sessão a ser interrompida (obrigatório)
Sistema de Log
- Status e progresso da operação
- Métricas de desempenho
- Monitoramento do uso de créditos
- Acompanhamento de limites de taxa
- Condições de erro
Tratamento de Erros
- Novas tentativas automáticas para erros transitórios
- Tratamento de rate limit com backoff
- Mensagens de erro detalhadas
- Alertas de uso de créditos
- Resiliência de rede
Desenvolvimento
Contribuindo
- Faça um fork do repositório
- Crie uma branch para sua feature
- Execute os testes:
npm test - Envie um pull request