Qué vas a construir
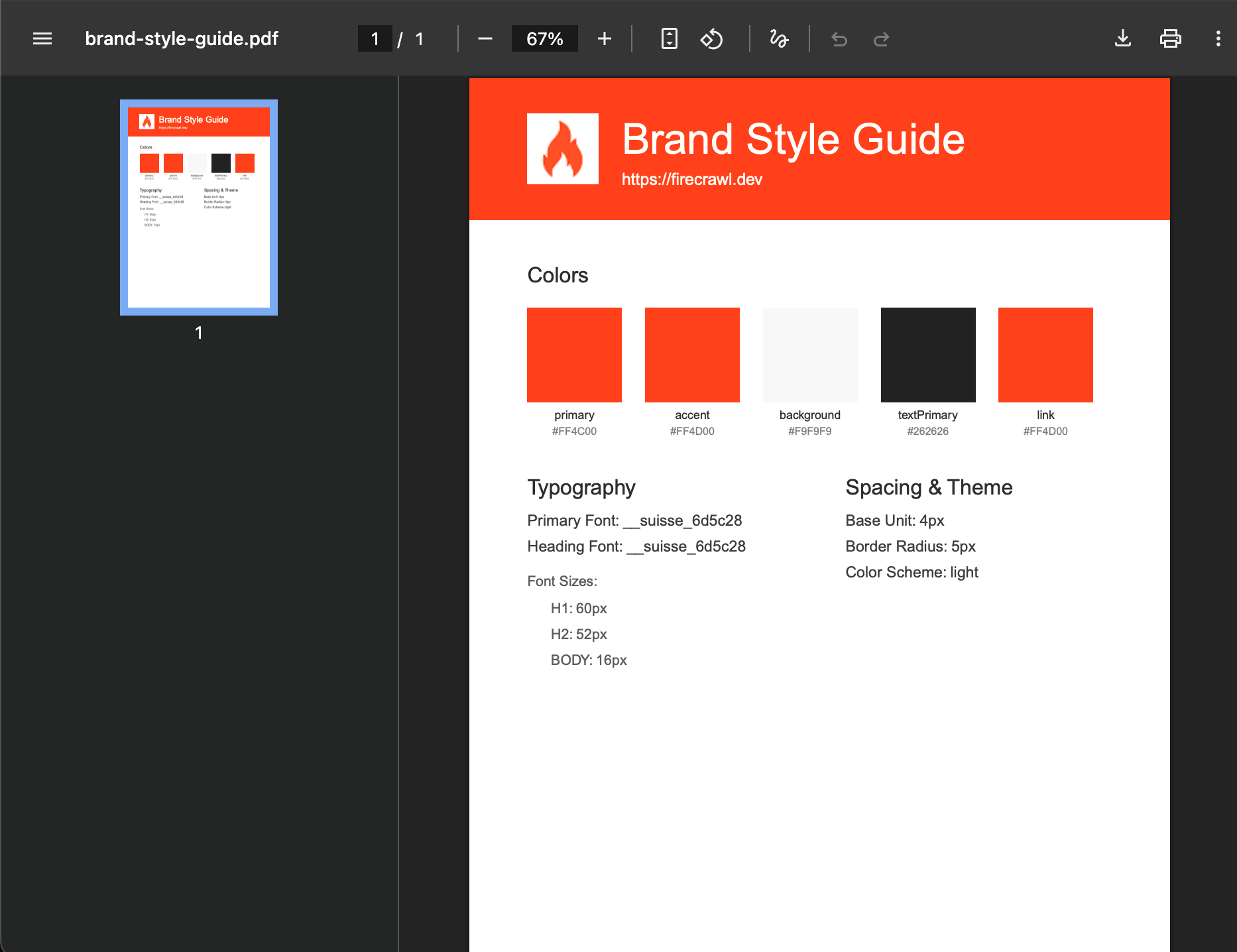
- Paleta de colores con valores hex
- Sistema de tipografía (fuentes, tamaños, pesos)
- Especificaciones de espaciado y diseño
- Logotipo e imágenes de la marca
- Información del tema (modo claro/oscuro)
Requisitos previos
- Node.js 18 o superior instalado
- Una clave de API de Firecrawl de firecrawl.dev
- Conocimientos básicos de TypeScript y Node.js
1
Crear un nuevo proyecto Node.js
Empieza por crear un nuevo directorio para tu proyecto e inicializarlo:Actualiza tu
package.json para utilizar módulos ES:package.json
2
Instalar las dependencias
Instala los paquetes necesarios para el scraping web y la generación de PDFs:Estos paquetes proporcionan:
firecrawl: SDK de Firecrawl para extraer la identidad de marca de sitios webpdfkit: librería para la generación de documentos PDFtsx: ejecución de TypeScript para Node.js
3
Crea el generador de guías de estilo de la marca
Crea el archivo principal de la aplicación en Reemplaza
index.ts. Este script extrae la identidad de marca a partir de una URL y genera una guía de estilo profesional en PDF.index.ts
Para este proyecto sencillo, la clave de la API se coloca directamente en el código. Si piensas subir esto a GitHub o compartirlo con otras personas, mueve la clave a un archivo
.env y usa process.env.FIRECRAWL_API_KEY en su lugar.fc-YOUR-API-KEY con tu clave de la API de Firecrawl de firecrawl.dev.Comprender el código
Componentes clave:- Formato de branding de Firecrawl: El formato
brandingextrae una identidad de marca completa, incluida la paleta de colores, la tipografía, el espaciado y las imágenes - Documento PDFKit: Crea un PDF A4 profesional con márgenes y secciones adecuados
- Muestras de color: Muestra bloques de color con valores hexadecimales y nombres semánticos
- Visualización de tipografía: Muestra familias tipográficas y tamaños en un diseño organizado
- Espaciado y tema: Documenta las unidades de espaciado y la paleta de colores del sistema de diseño
4
Ejecutar el generador
Ejecuta el script para generar una guía de estilo de la marca:El script hará lo siguiente:
- Extraer la identidad de marca de la URL de destino usando el formato de marca de Firecrawl
- Generar un PDF llamado
brand-style-guide.pdf - Guardarlo en el directorio de tu proyecto
URL en index.ts.Cómo funciona
Proceso de extracción
- Entrada de URL: El generador recibe la URL de un sitio web de destino
- Firecrawl Scrape: Llama al endpoint
/scrapecon el formatobranding - Análisis de marca: Firecrawl analiza el CSS, las fuentes y los elementos visuales de la página
- Retorno de datos: Devuelve un objeto
BrandingProfileestructurado con todos los tokens de diseño
Proceso de generación de PDF
- Creación del encabezado: Genera un encabezado de color usando el color principal de la marca
- Obtención del logotipo: Descarga e inserta el logotipo o favicon si está disponible
- Paleta de colores: Muestra cada color como una muestra visual con metadatos
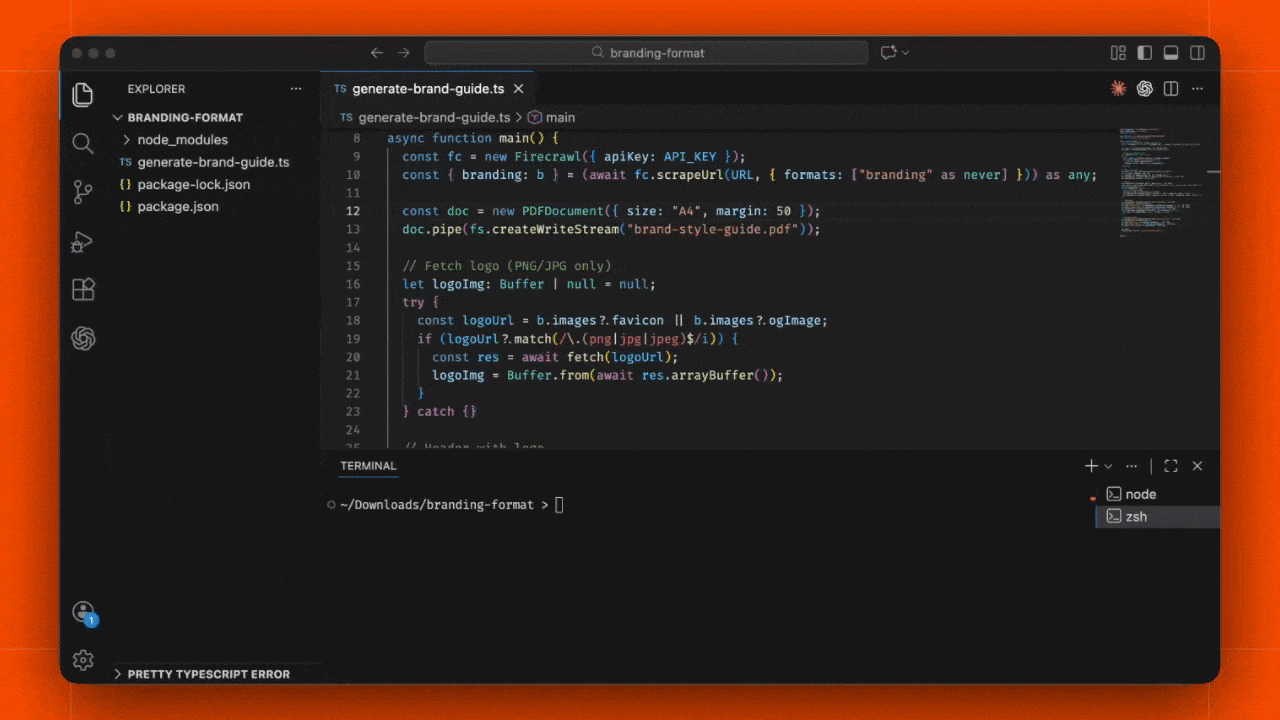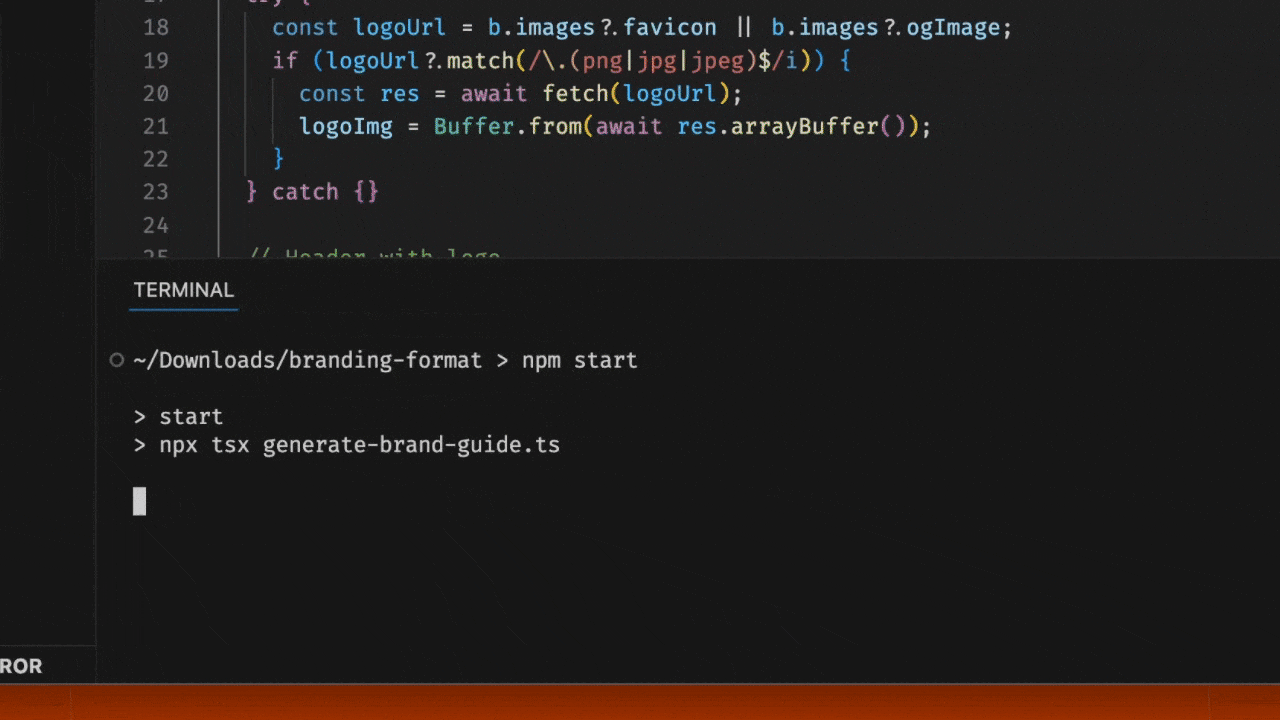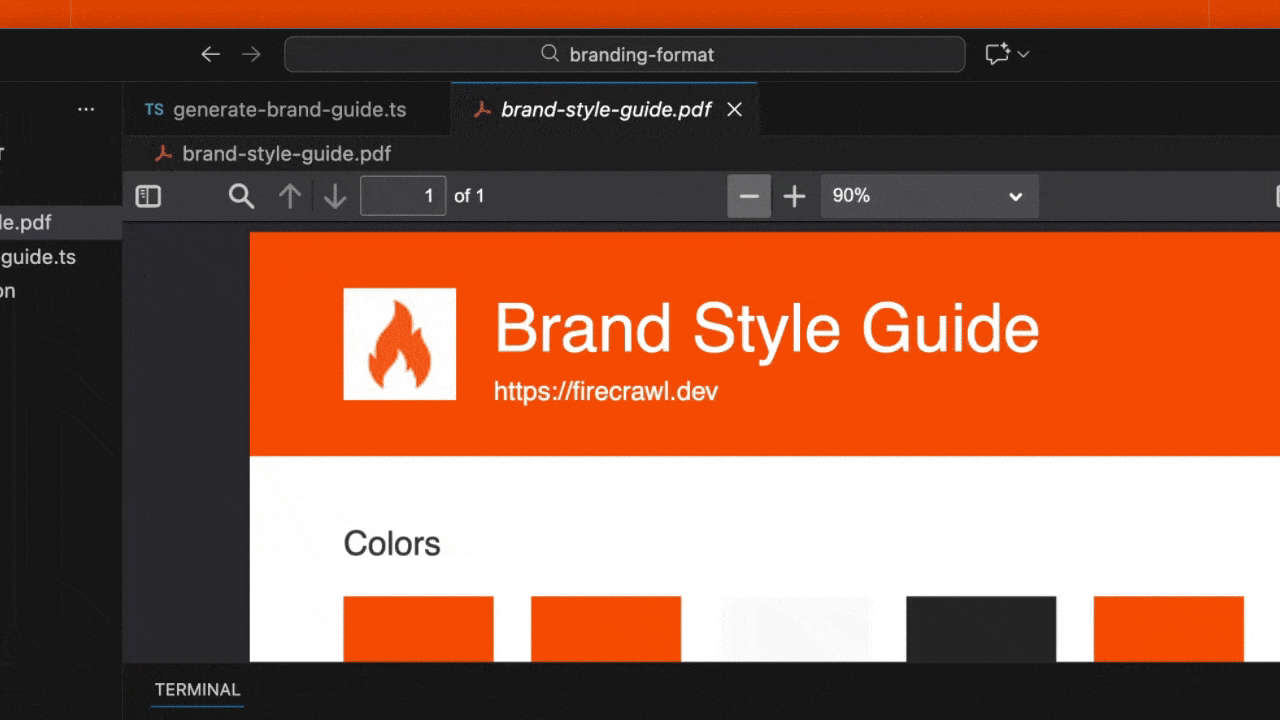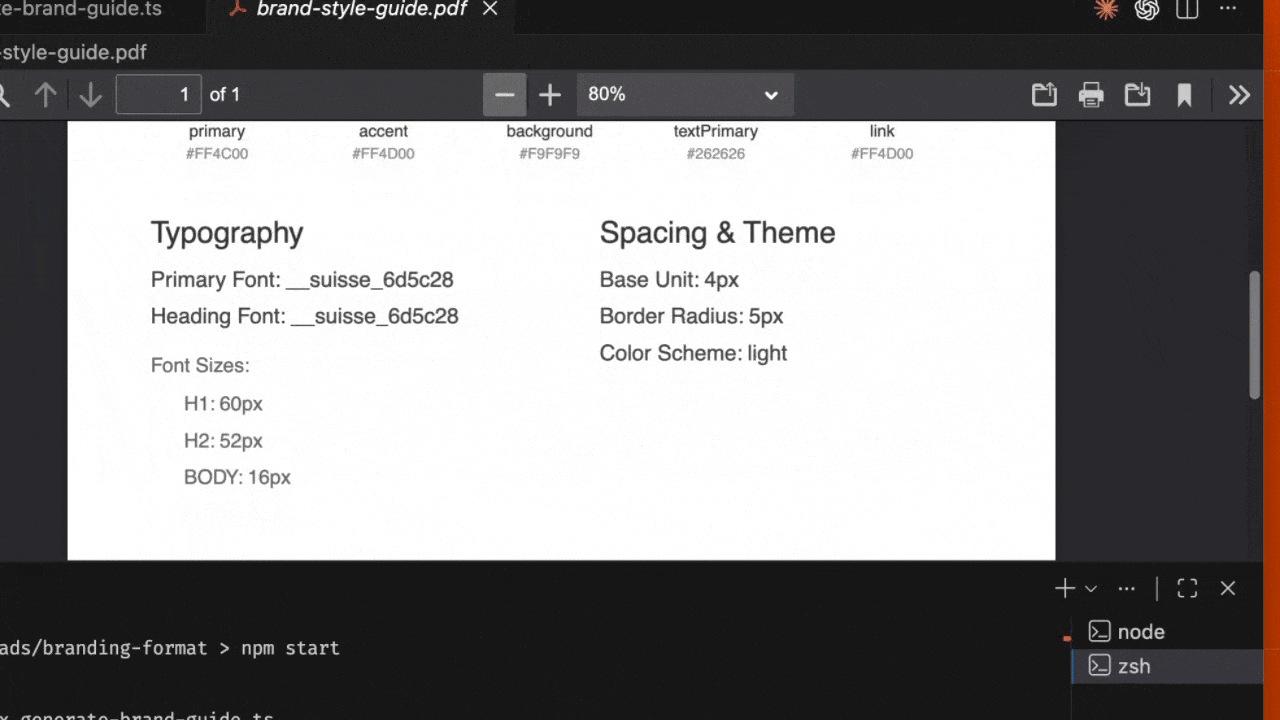
- Sección de tipografía: Documenta familias tipográficas, tamaños y grosores
- Información de espaciado: Incluye unidades base, radio de los bordes y modo del tema
Estructura del perfil de branding
Características clave
Extracción Automática de Colores
- Primarios y Secundarios: Colores principales de la marca
- Acento: Colores de énfasis y de llamado a la acción (CTA)
- Fondo y Texto: Colores base de la interfaz
- Colores Semánticos: Estados de éxito, advertencia y error
Documentación sobre tipografía
- Familias tipográficas: Fuentes primarias, para encabezados y monoespaciadas
- Escala de tamaños: Todos los tamaños de texto de encabezado y cuerpo
- Pesos tipográficos: Variaciones de grosor disponibles
Salida visual
- Encabezado con colores de la marca
- Logotipo integrado cuando esté disponible
- Diseño profesional con jerarquía clara
- Pie de página con metadatos y fecha de generación
Ideas de personalización
Agregar documentación de componentes
Exportar en varios formatos
Procesamiento por lotes
Temas personalizados de PDF
Mejores prácticas
- Gestionar datos faltantes: No todos los sitios web exponen información de marca completa. Proporciona siempre valores de reserva para las propiedades faltantes.
- Respetar los límites de tasa: Al procesar por lotes varios sitios, añade pausas entre solicitudes para respetar los límites de tasa de Firecrawl.
- Almacenar resultados en caché: Guarda los datos de marca extraídos para evitar llamadas repetidas a la API para el mismo sitio.
- Gestión del formato de imagen: Algunos logotipos pueden estar en formatos que PDFKit no admite (como SVG). Considera añadir conversión de formato o alternativas de reserva adecuadas.
- Gestión de errores: Envuelve el proceso de generación en bloques try-catch y proporciona mensajes de error descriptivos.
Documentación del formato de branding
Más información sobre el formato de branding y todas las propiedades que puedes extraer.
API de scraping de Firecrawl
Referencia completa de la API para el endpoint de scraping con todas las opciones de formato.
Documentación de PDFKit
Más información sobre PDFKit y sus opciones avanzadas de personalización de PDF.
Guía de scraping por lotes
Procesa varias URL de forma eficiente con scraping por lotes.