機能
- Webを検索してページ全体のコンテンツを取得
- 任意のURLをスクレイピングして、クリーンな構造化データを取得
- PDF、DOCX、XLSX、HTML などのローカルファイルを解析
- ページ上でInteract — クリック、移動、操作
- 自律エージェントによる深層リサーチ
- クラウドおよびセルフホストに対応
- Streamable HTTPサポート
インストール
APIキーがありませんか? リモートのキー不要のFreeティアを利用するには
https://mcp.firecrawl.dev/v2/mcp に接続してください。これは無料で、IPごとにレート制限があります。現在利用可能なキー不要ツールの一覧については Rate Limits を参照してください。FIRECRAWL_API_KEY を設定すると、すべてのMCPツールが使えるようになり、より高い上限も利用できます。リモートホストのURL
Authorization ヘッダーとして送信すると、すべてのツールと、より高い上限を利用できるようになります:
npx での実行
手動インストール
Cursor 上での実行
 または、
または、~/.cursor/mcp.json に手動で追加します:
API キーを使用してローカルで実行
- Cursor Settings を開く
- Features > MCP Servers に移動
- 「+ Add new global MCP server」をクリック
- 次のコードを入力:
- Cursor Settings を開く
- Features > MCP Servers に移動
- 「+ Add New MCP Server」をクリック
- 次を入力:
- Name: “firecrawl-mcp” (任意の名称でも可)
- Type: “command”
- Command:
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp
Windows を使用していて問題が発生する場合は、cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp" を試してください
your-api-key をお持ちの Firecrawl API キーに置き換えてください。まだお持ちでない場合はアカウントを作成し、https://www.firecrawl.dev/app/api-keys から取得できます。
追加後、MCP サーバー一覧を更新して新しいツールを確認してください。Composer Agent は適宜 Firecrawl MCP を自動的に使用しますが、ウェブデータの要件を記述することで明示的にリクエストすることも可能です。Command+L (Mac) で Composer を開き、送信ボタン横の「Agent」を選択してクエリを入力します。
Windsurf での実行
./codeium/windsurf/model_config.json に追加します:
Streamable HTTP モードでの実行
Smithery 経由でのインストール (レガシー)
VS Code での実行
Ctrl + Shift + P を押し、Preferences: Open User Settings (JSON) と入力して開きます。
.vscode/mcp.json ファイルにこれを追加できます。そうすると、この設定を他の人と共有できるようになります。
Claude Desktop での実行
spawn npx ENOENT エラーが表示される場合、Node.js がインストールされていないか、システムの PATH に登録されていません。nodejs.org から Node.js (LTS バージョン) をインストールし、その後 Claude Desktop を完全に再起動してください。Windows では、コマンド プロンプトで where npx を実行し、フル パス (例:C:\\Program Files\\nodejs\\npx.cmd) を command の値として使用することもできます。
Claude Code での実行
Google Antigravity 上での実行
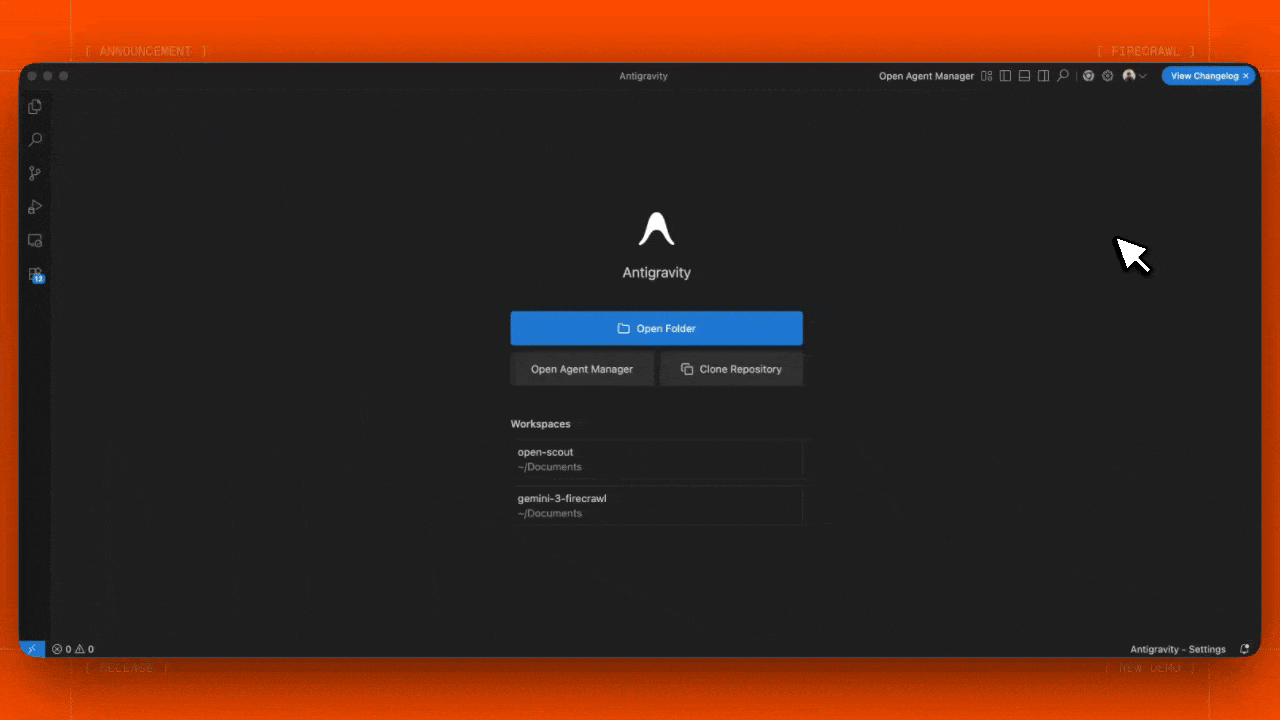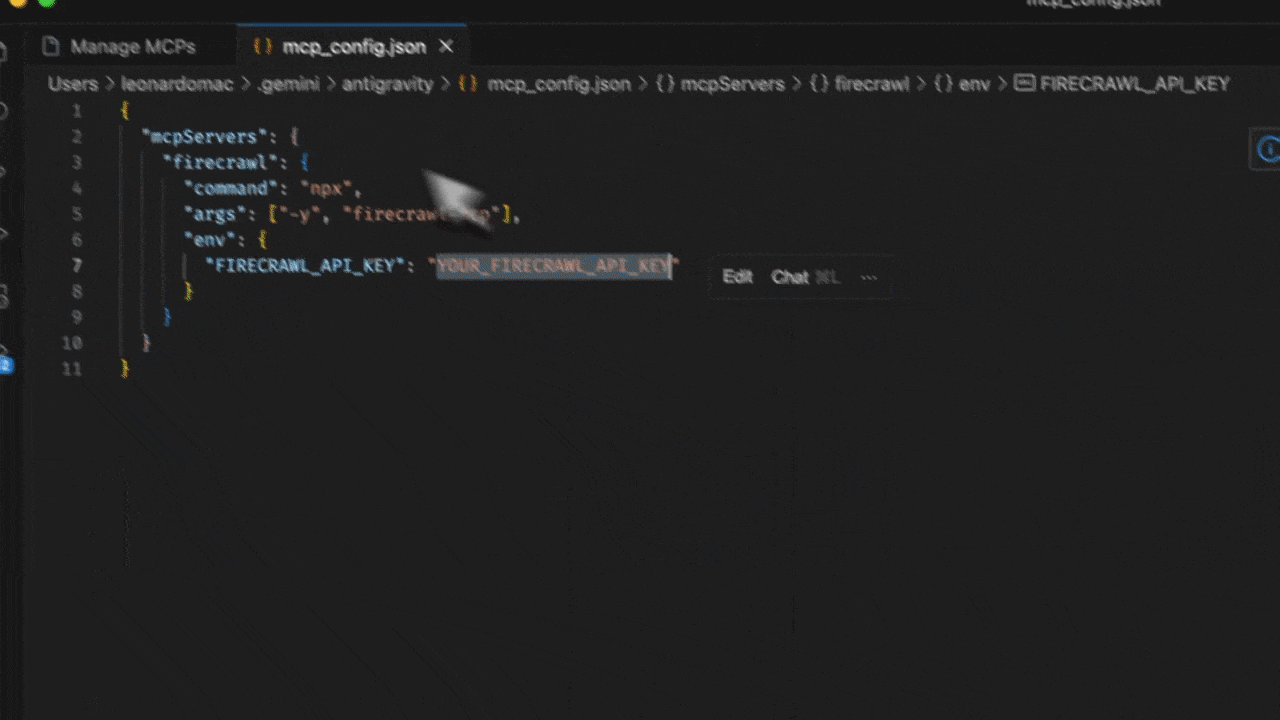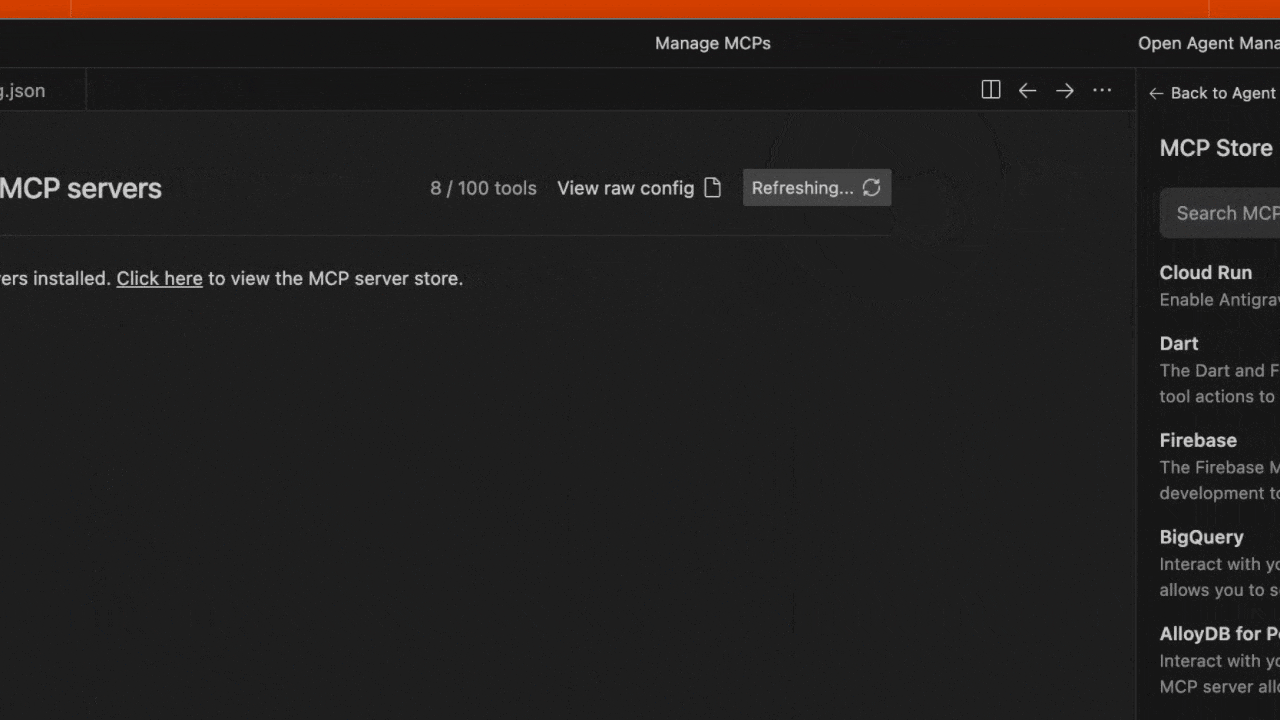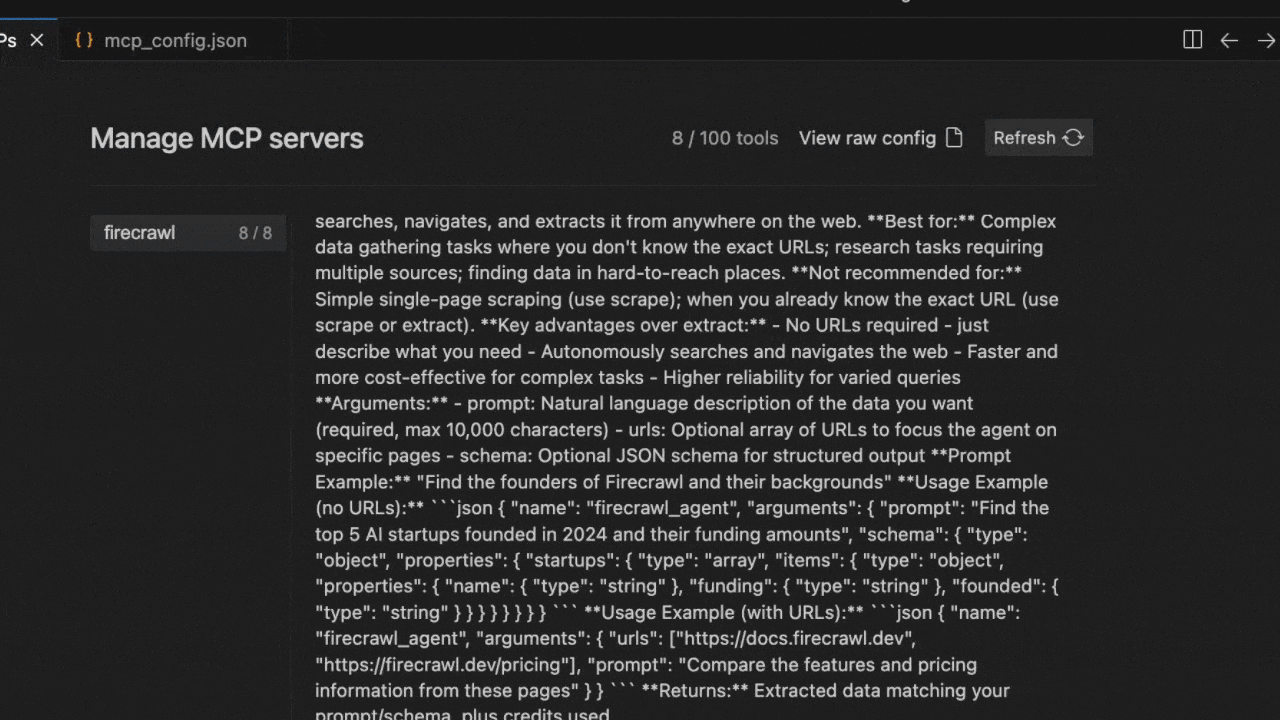
- Editor または Agent Manager ビューで Agent サイドバーを開きます
- ”…” (More Actions) メニューをクリックし、MCP Servers を選択します
- View raw config を選択して、ローカルの
mcp_config.jsonファイルを開きます - 以下の設定を追加します:
- ファイルを保存し、Antigravity MCP インターフェースで Refresh をクリックして、新しいツールが表示されることを確認します。
YOUR_FIRECRAWL_API_KEY を、https://firecrawl.dev/app/api-keys から取得した API キーに置き換えてください。
n8n 上での実行
- https://firecrawl.dev/app/api-keys から Firecrawl APIキーを取得する
- n8n のワークフローで AI Agent ノードを追加する
- AI Agent の設定で、新しい Tool を追加する
- ツールタイプとして MCP Client Tool を選択する
- MCP サーバーのエンドポイントを入力する:
- Server Transport を HTTP Streamable に設定します
- Authentication を Bearer に設定して Firecrawl APIキーを貼り付けるか、None のままにして keyless free tier を使用します
- Tools to include では All、Selected、または All Except を選択できます。これにより Firecrawl のツール (scrape、crawl、map、search、extract など) が利用可能になります。
http://localhost:3000/v2/mcp で起動し、n8n のワークフロー内でエンドポイントとして利用できます。n8n では HTTP トランスポートが必要なため、環境変数 HTTP_STREAMABLE_SERVER=true を設定する必要があります。
設定
環境変数
Cloud API とセルフホスト API
FIRECRAWL_API_KEY: Firecrawl のAPIキー- Cloud API (デフォルト) を使用する場合に必須
FIRECRAWL_API_URLを指定したセルフホスト環境では任意
FIRECRAWL_API_URL(任意) : セルフホスト環境向けのカスタムAPIエンドポイント- 例:
https://firecrawl.your-domain.com - 指定しない場合は Cloud API が使用されます (APIキーが必要)
- 例:
設定例
Claude Desktop でのカスタム設定
claude_desktop_config.json に追加します:
Hosted MCP とローカル MCP
- Hosted キー不要 mode では、キー不要対応の tools のみが公開され、IP ごとにレート制限が適用されます。
- ローカル専用の file read は、MCP サーバー をローカルで実行している場合にのみ利用できます。
- agent がローカルリソースへのアクセスを必要とする場合、webhook とローカルの file path は、ローカルまたは セルフホスト の MCP サーバー から設定する必要があります。
レート制限
利用可能なツール
1. スクレイプツール (firecrawl_scrape)
redactPIIを含めます。
2. Map Tool (firecrawl_map)
Map Tool オプション:
url: マッピング対象となるウェブサイトのベース URLsearch: URL をフィルタリングするための任意の検索語句sitemap: サイトマップの利用方法を制御 - “include”、“skip”、“only” のいずれかincludeSubdomains: マッピング時にサブドメインを含めるかどうかlimit: 返す URL の最大件数ignoreQueryParameters: マッピング時にクエリパラメータを無視するかどうか
3. Search Tool (firecrawl_search)
Search ツールのオプション:
query: 検索クエリ文字列 (必須)limit: 返す結果の最大件数location: 検索結果の地理的な場所tbs: 時間ベースの検索フィルター (例:qdr:d過去1日、qdr:w過去1週間、qdr:m過去1か月)filter: 追加の検索フィルターsources: 検索対象とするソース種別の配列 (web、images、news)scrapeOptions: 検索結果ページをスクレイピングする際のオプションenterprise: enterprise オプションの配列 (default、anon、zdr)
4. 解析ツール (firecrawl_parse)
FIRECRAWL_API_URL を使って Firecrawl MCP をローカルで Firecrawl API インスタンスに対して実行すると、MCP サーバーは filePath を直接読み取り、ファイルのバイト列を /v2/parse に送信できます。
リモートでホストされている MCP サーバーを使用する場合、そのホストサーバーは手元のマシン上のファイルを読み取れません。そのため、firecrawl_parse はリモートの keyless URL でも動作する 2 段階の受け渡し方式を使用します。
filePathを指定してfirecrawl_parseを呼び出します。ツールは、入力済みのアップロードコマンドと、uploadRefを含むnextToolCallを返します。- ファイルを読み取れるマシンでアップロードコマンドを実行し、返された
uploadRefを使ってもう一度firecrawl_parseを呼び出します。
解析ツールのオプション:
filePath: 解析するファイルのローカルパスです。最初の呼び出しではこれを使用します。uploadRef: 最初の hosted-MCP 呼び出しで返される参照です。アップロード成功後の2回目の呼び出しで使用します。formats: 出力フォーマットです。デフォルトはmarkdownです。parsers: PDF の解析オプションなどのパーサー設定です。contentType: 任意のファイル MIME タイプの上書きです。declaredSizeBytes: 任意のファイルサイズの目安です。ファイルサイズの上限は 50 MB です。
firecrawl_scrape を使用してください。URL からドキュメントを検出して解析します。
5. Crawl Tool (firecrawl_crawl)
6. クロールのステータスを確認 (firecrawl_check_crawl_status)
7. Extract Tool (firecrawl_extract)
Extract Tool オプション:
urls: 情報を抽出する対象の URL 配列prompt: LLM による抽出に使用するカスタムプロンプトschema: 構造化データ抽出用の JSON スキーマallowExternalLinks: 外部リンクからの抽出を許可するかどうかenableWebSearch: 追加のコンテキストのためにウェブ検索を有効にするかどうかincludeSubdomains: 抽出対象にサブドメインを含めるかどうか
8. Agent Tool (firecrawl_agent)
firecrawl_agent_status をポーリングして完了を確認し、結果を取得します。
Agent Tool Options:
prompt: 取得したいデータの内容を自然言語で記述したもの (必須、最大 10,000 文字)urls: エージェントを特定のページにフォーカスさせるためのオプションの URL 配列schema: 構造化出力のためのオプションの JSON スキーマ
firecrawl_agent_status を使って結果をポーリングします。
9. エージェントのステータスを確認 (firecrawl_agent_status)
エージェントステータスのオプション:
id:firecrawl_agentから返されるエージェントジョブ ID (必須)
processing: エージェントがまだ調査中 — ポーリングを継続completed: 調査完了 — レスポンスに抽出データが含まれるfailed: エラーが発生
10. Interact (firecrawl_interact)
urlを渡すと、1 回の MCP 呼び出しで新しいページを開いて操作できます。- 以前の
firecrawl_scrape呼び出しで取得したscrapeIdを渡すと、すでに読み込まれているページを再利用できます。
url と scrapeId の両方を渡さないでください。prompt または code のいずれかを指定してください。scrapeOptions は url モードでのみ使用できます。
URL モードの例:
Interact ツールのオプション:
url: 操作対象のページ。セッションを自動的に開きます。これまたはscrapeIdを使用します。scrapeId: 前回のfirecrawl_scrape呼び出しで取得した scrape job ID。これまたはurlを使用します。prompt: 実行するアクションを自然言語で指示するプロンプト。promptまたはcodeを指定します。code: ブラウザセッションで実行するコード。codeまたはpromptを指定します。language:bash、python、またはnode(任意、デフォルトはnode、code使用時のみ使用)。timeout: 実行タイムアウト (秒)、1~300 (任意、デフォルトは 30)。scrapeOptions:urlモードでのみ使用する任意のスクレイピング設定。
11. Interact セッションの停止 (firecrawl_interact_stop)
Interact 停止オプション:
scrapeId: 停止するセッションのscrapeId(必須)
ログシステム
- 操作のステータスと進捗
- パフォーマンス指標
- クレジット使用状況の監視
- レート制限のトラッキング
- エラー状況
エラーハンドリング
- 一時的なエラーに対する自動リトライ
- バックオフを伴うレート制限への対応
- 詳細なエラーメッセージ
- クレジット使用量に関する警告
- ネットワーク障害への耐性
開発
コントリビュート方法
- リポジトリをフォークする
- 機能ブランチを作成する
- テストを実行する:
npm test - プルリクエストを作成して送信する