> ## Documentation Index
> Fetch the complete documentation index at: https://docs.firecrawl.dev/llms.txt
> Use this file to discover all available pages before exploring further.
# Firecrawl + n8n
> 了解如何将 Firecrawl 与 n8n 配合使用,实现网页抓取自动化的完整分步指南。
## Firecrawl 与 n8n 入门
网页采集自动化已成为现代企业的刚需。无论你要监控竞品价格、汇聚内容、获取潜在客户,还是用实时数据驱动 AI 应用,Firecrawl 搭配 n8n 都能在无需编程知识的前提下提供强大的解决方案。
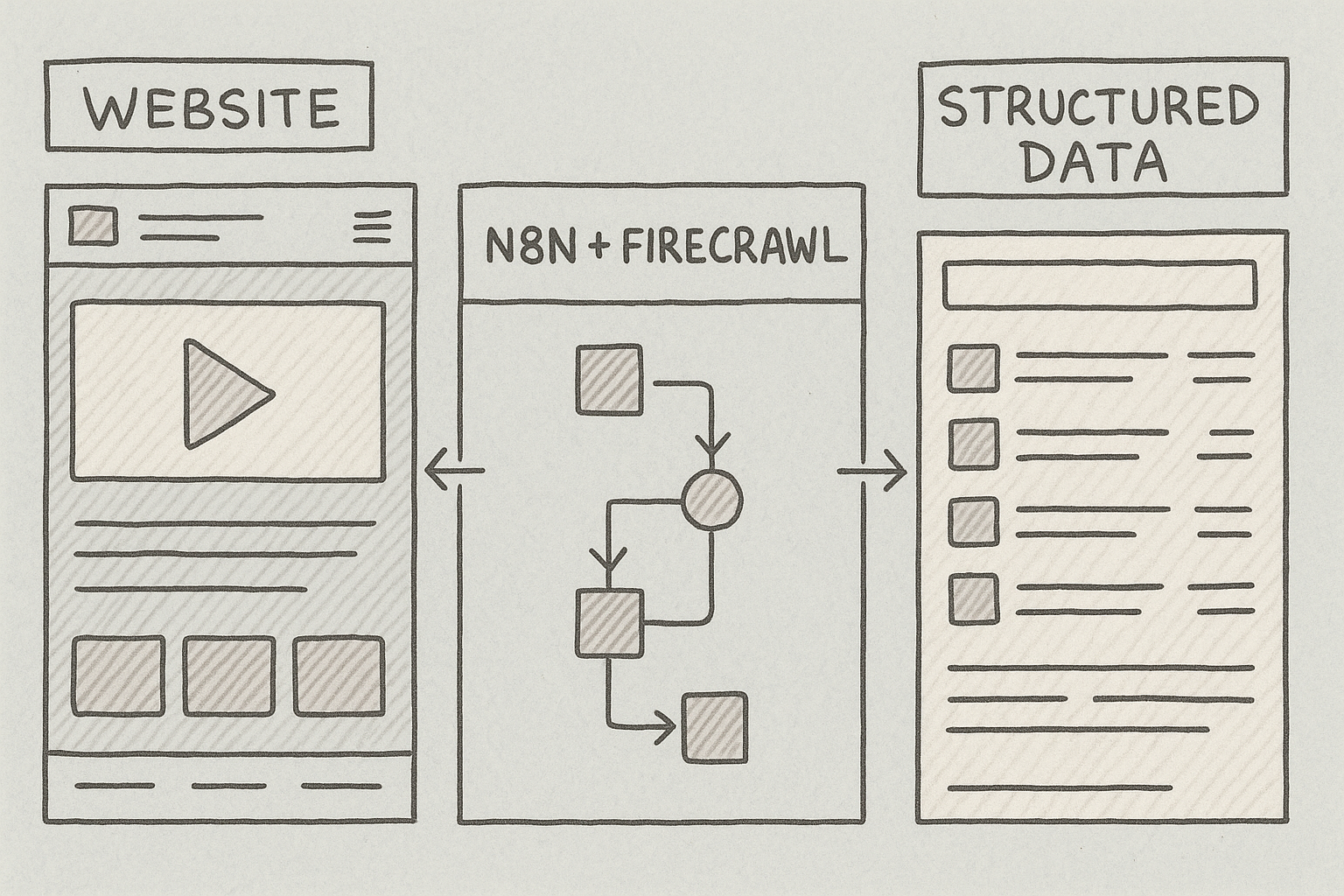 **什么是 n8n?**
n8n 是一个开源的工作流自动化平台,可将不同的工具和服务连接起来。你可以把它看作一个可视化编程环境:将节点拖拽到画布上,连接它们,创建自动化流程。借助 400+ 集成,n8n 让你无需编写代码即可构建复杂的自动化。
**什么是 n8n?**
n8n 是一个开源的工作流自动化平台,可将不同的工具和服务连接起来。你可以把它看作一个可视化编程环境:将节点拖拽到画布上,连接它们,创建自动化流程。借助 400+ 集成,n8n 让你无需编写代码即可构建复杂的自动化。
## 为什么将 Firecrawl 与 n8n 搭配使用?
传统的网页抓取面临诸多挑战:网站结构一变更,自定义脚本就会失效;反爬系统会拦截自动化请求;重度依赖 JavaScript 的网站无法正确渲染;基础设施还需要持续运维。
Firecrawl 负责处理抓取端的技术复杂性,n8n 则提供自动化框架。二者结合,让你构建可直接用于生产的工作流,能够:
* 可靠地从任意网站提取数据
* 将抓取的数据对接到其他业务工具
* 按计划运行或由事件触发
* 从简单任务无缝扩展到复杂的数据管道
本指南将带你完成两个平台的设置,并从零开始搭建你的第一个抓取工作流。
## 步骤 1:创建你的 Firecrawl 账户
Firecrawl 为你的工作流提供网页抓取功能。现在设置你的账户并获取 API 凭据。
### 注册 Firecrawl
1. 在浏览器中访问 [firecrawl.dev](https://firecrawl.dev)
2. 点击“Get Started”或“Sign Up”按钮
3. 使用邮箱地址或 GitHub 账号创建账户
4. 按提示完成邮箱验证
### 获取 API Key
登录后,你需要一个 API key 将 Firecrawl 连接到 n8n:
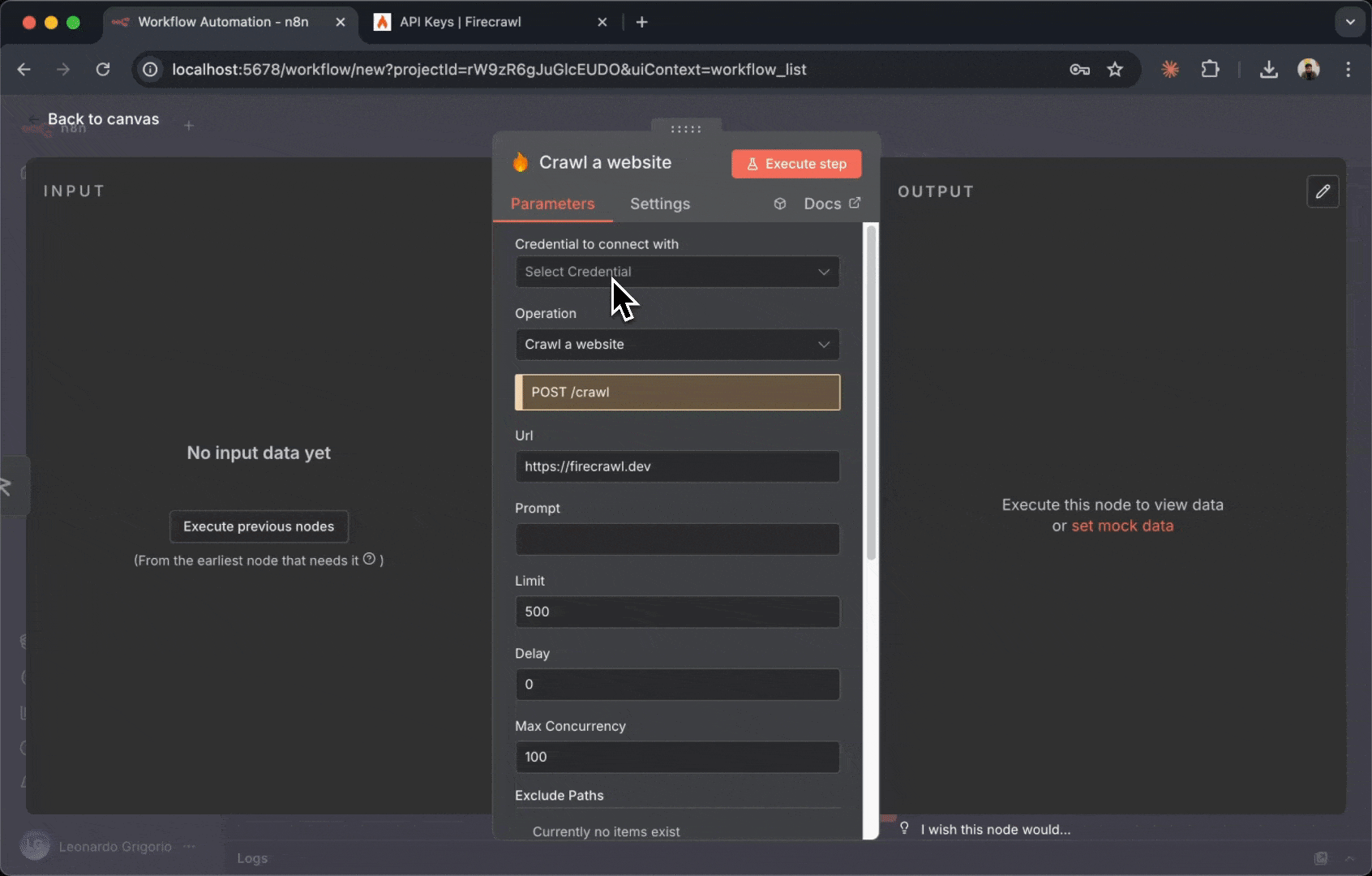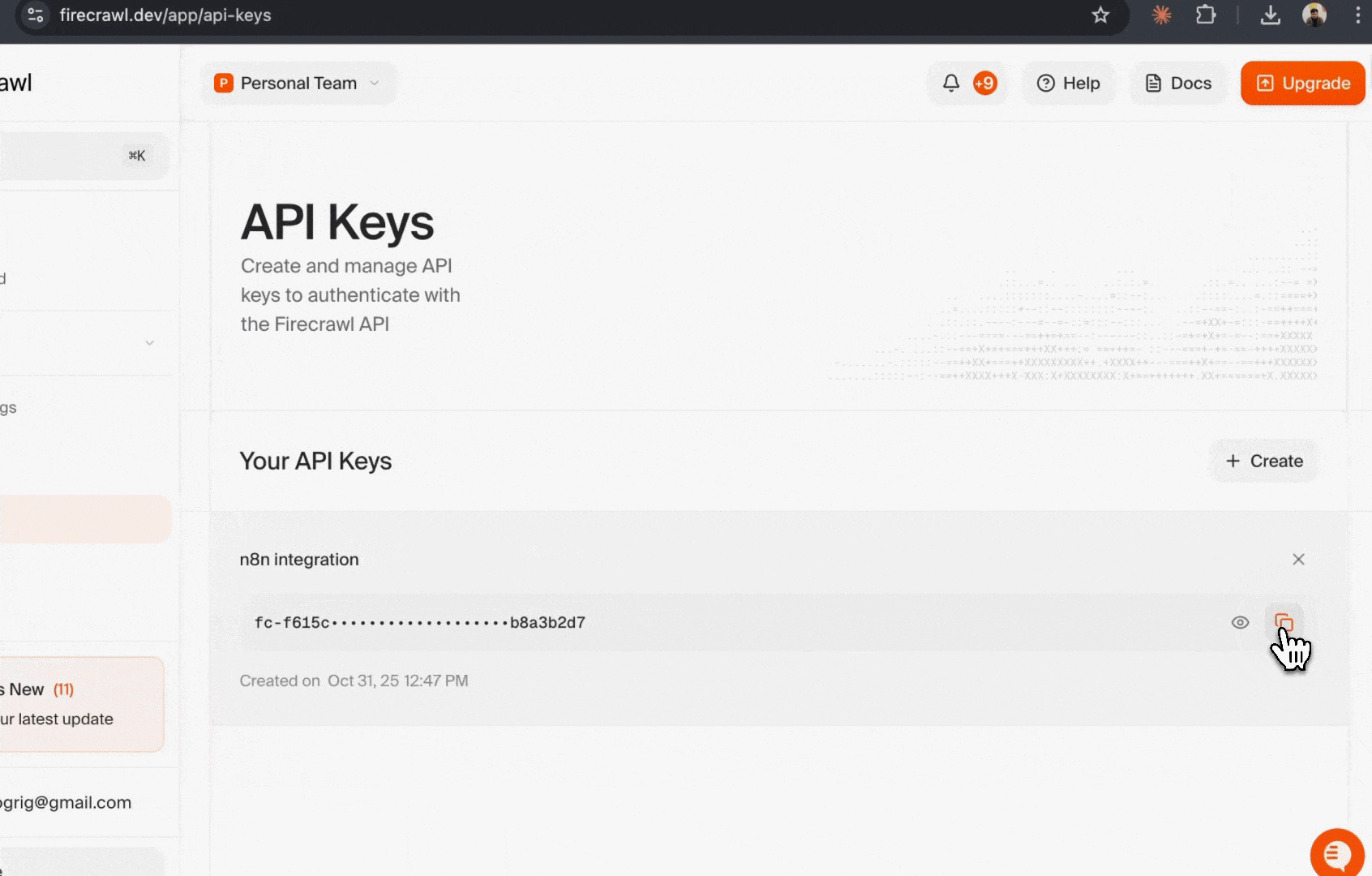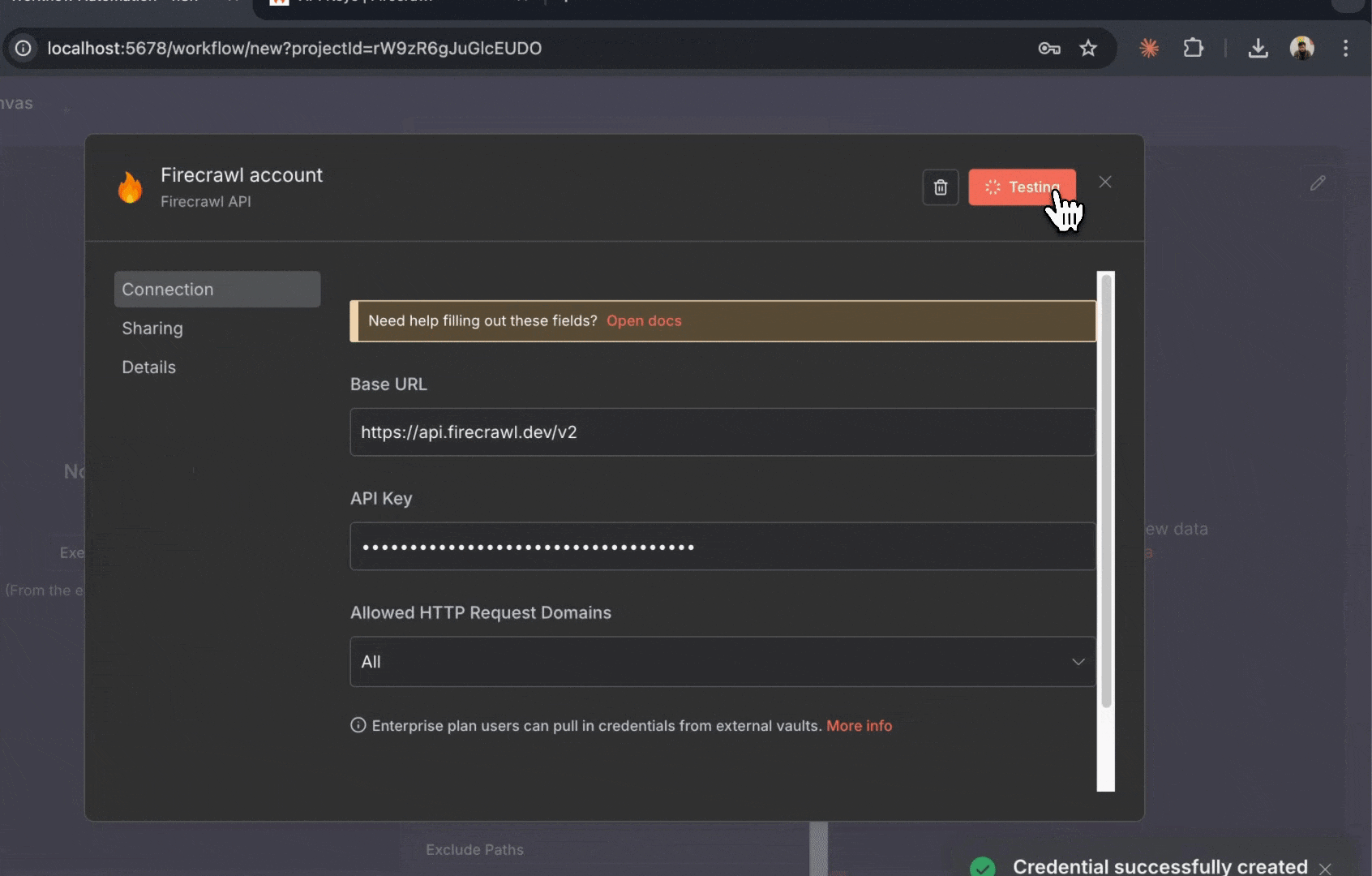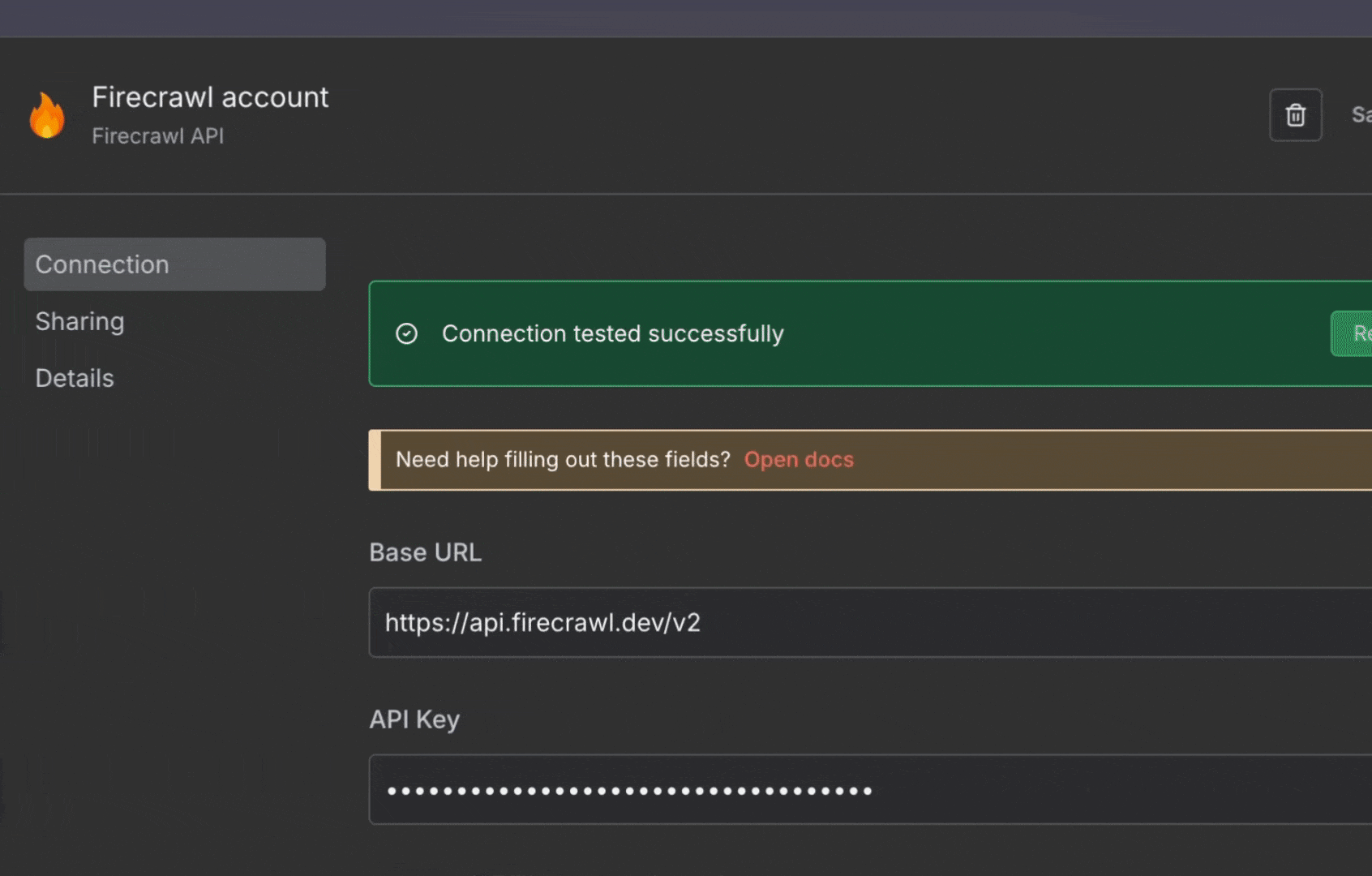
1. 前往你的 Firecrawl 控制台
2. 进入 [API Keys 页面](https://www.firecrawl.dev/app/api-keys)
3. 点击“Create New API Key”
4. 为密钥起一个具有描述性的名称 (例如:“n8n Integration”)
5. 复制生成的 API key 并妥善保存
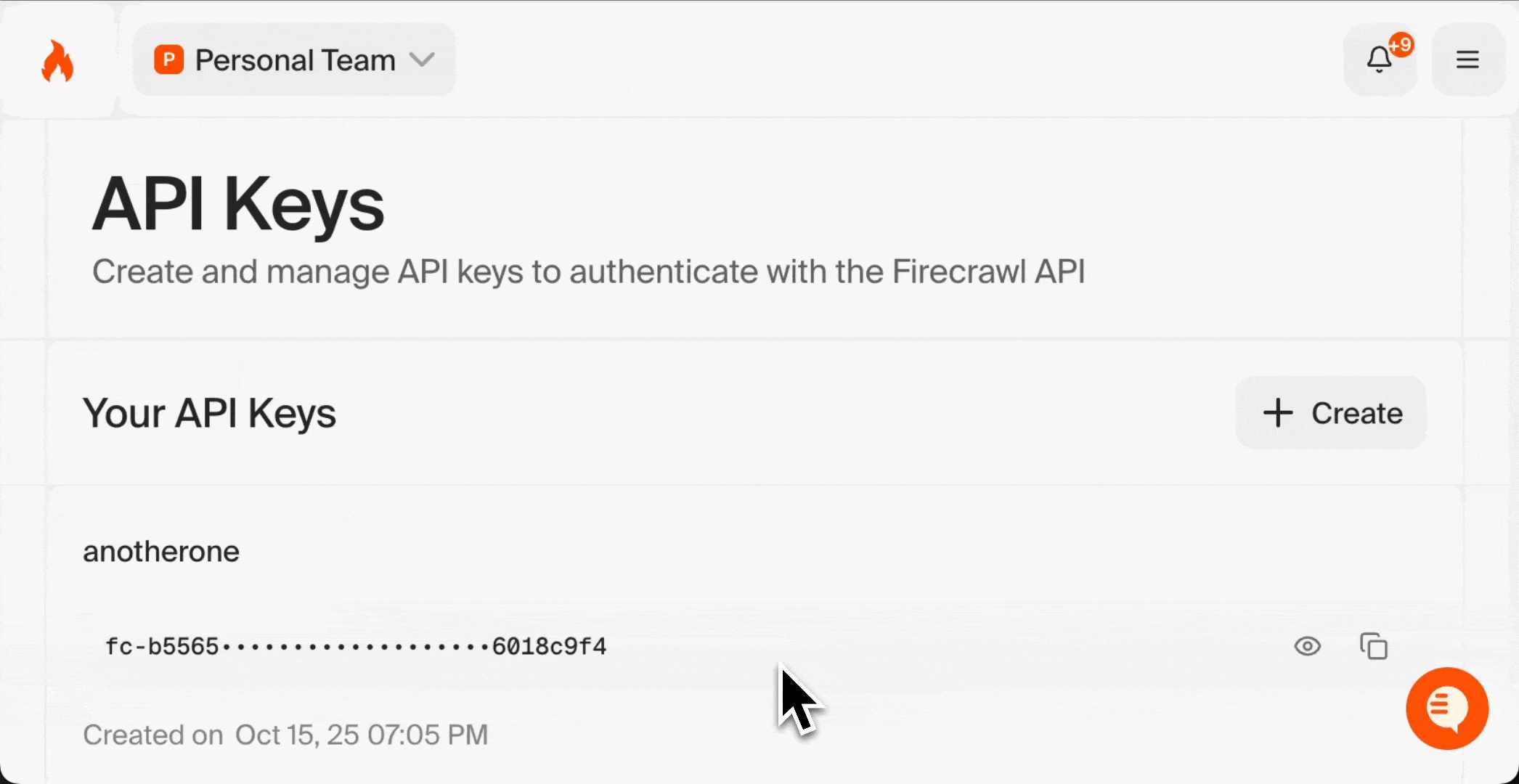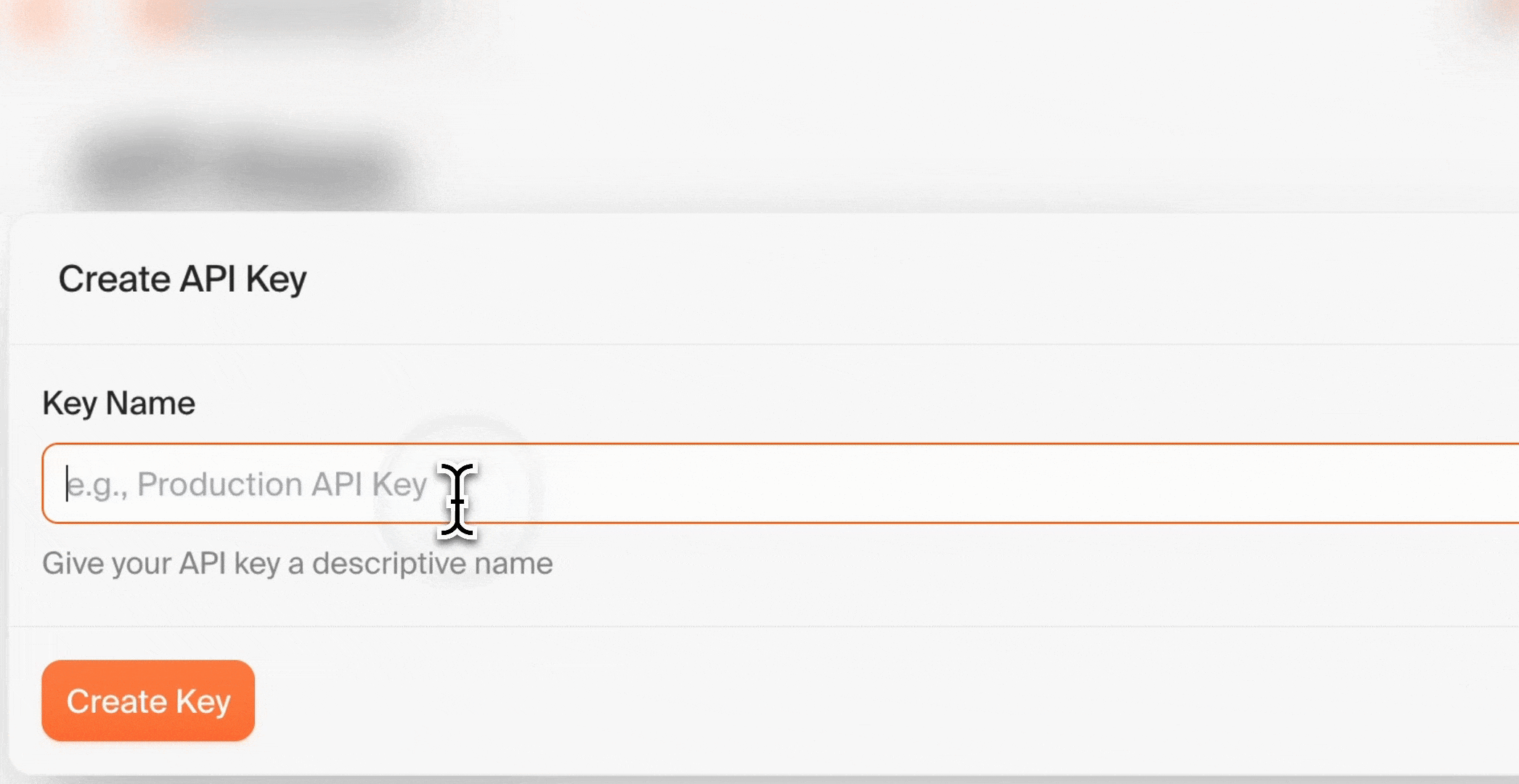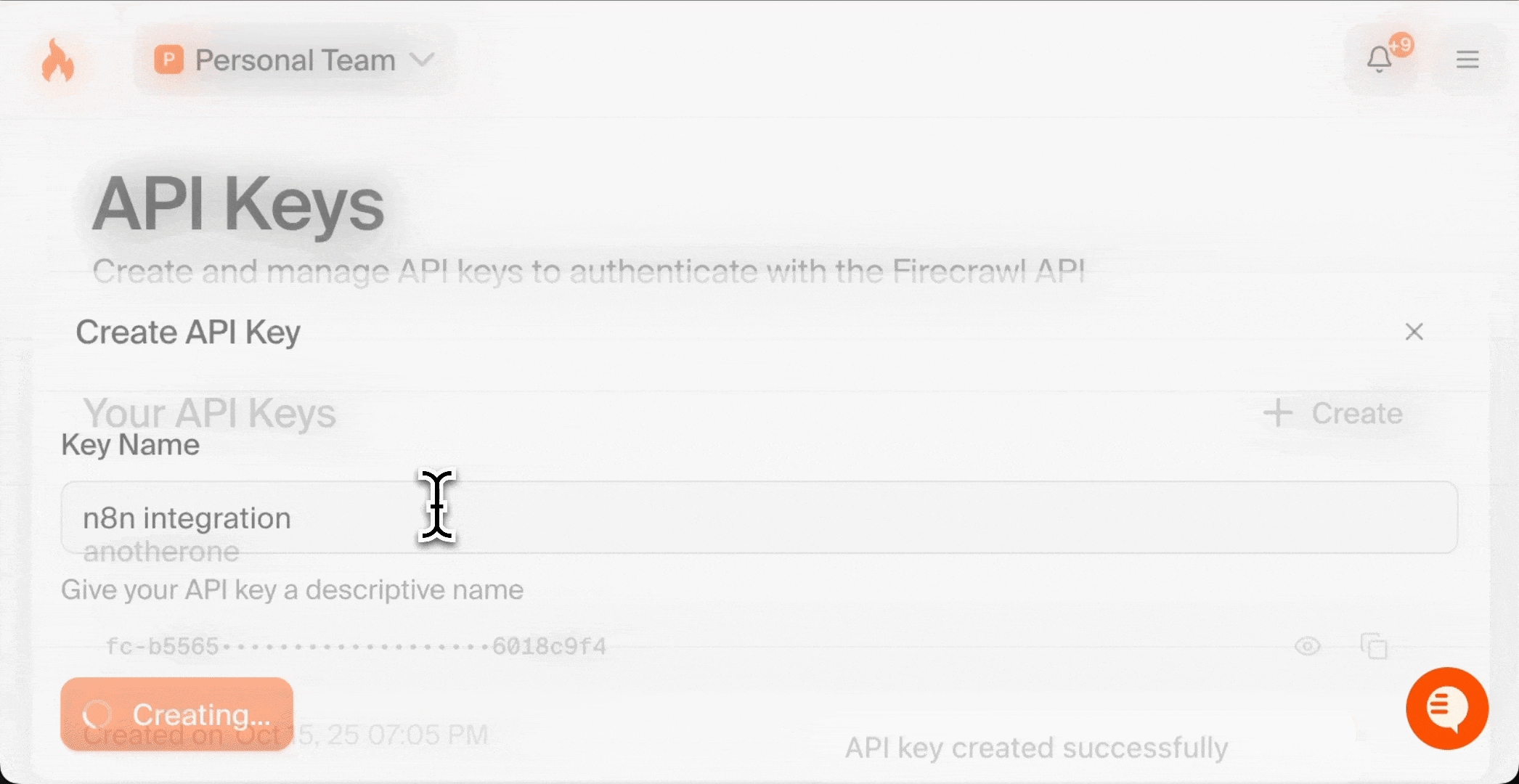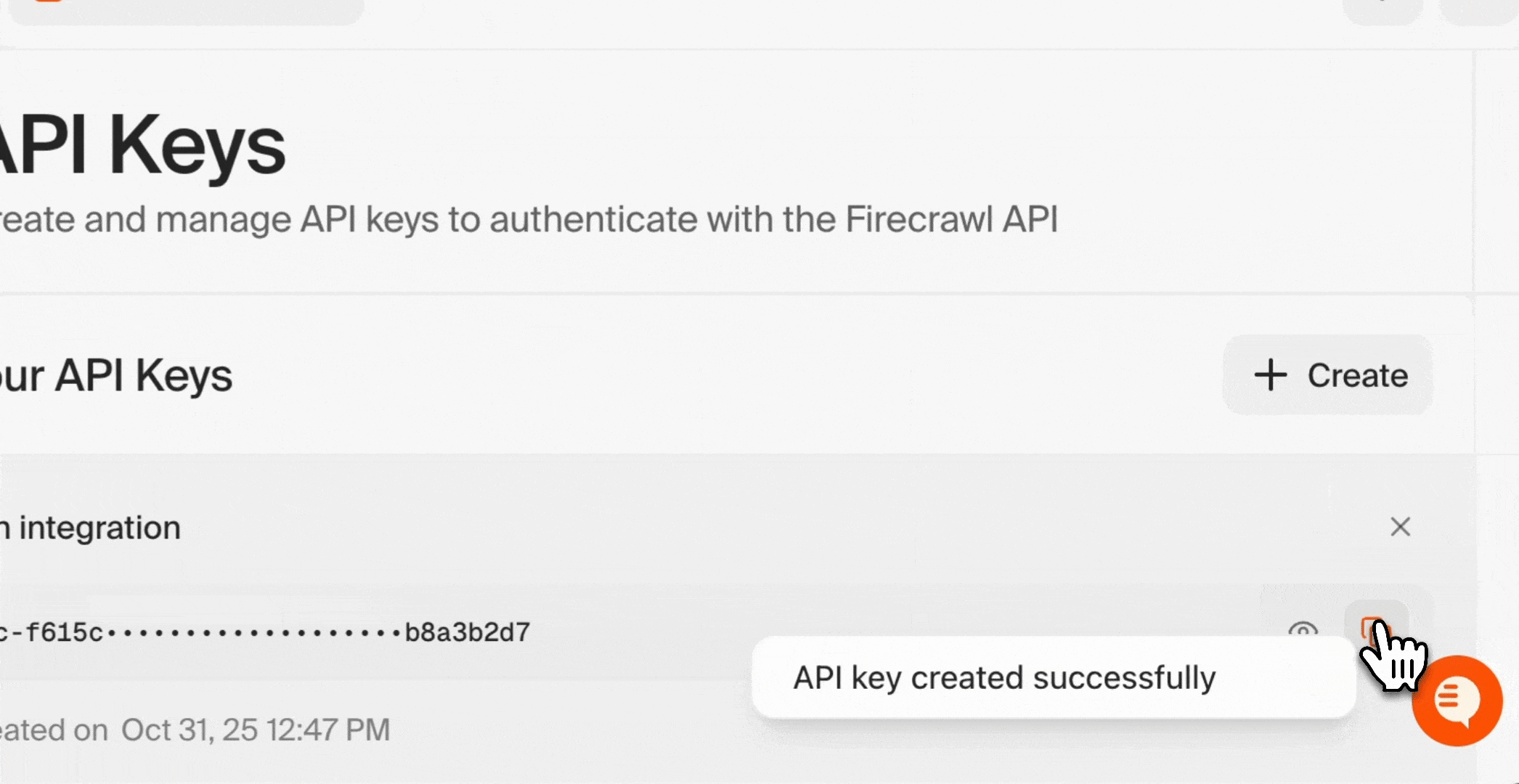 你的 API key 类似密码。请妥善保管,切勿公开分享。你将在下一节用到此密钥。
注册 Firecrawl 时会提供免费额度,足以测试你的工作流并完成本教程。
你的 API key 类似密码。请妥善保管,切勿公开分享。你将在下一节用到此密钥。
注册 Firecrawl 时会提供免费额度,足以测试你的工作流并完成本教程。
## 步骤 2:设置 n8n
n8n 提供两种部署方式:云端托管或自托管。对于新手,使用云端版本是最快的入门途径。
### 选择你的 n8n 版本
**n8n Cloud (推荐新手使用) :**
* 无需安装
* 提供免费套餐
* 托管基础设施
* 自动更新
**自托管:**
* 完全掌控数据
* 在你自己的服务器上运行
* 需要安装 Docker
* 适合对安全有特定要求的高级用户
选择最符合你需求的方案。两种方式都会进入同一套工作流编辑器界面。
### 选项 A:n8n Cloud (推荐给新手)
1. 访问 [n8n.cloud](https://n8n.cloud)
2. 点击“Start Free”或“Sign Up”
3. 使用邮箱或 GitHub 注册
4. 完成验证流程
5. 系统会将你带到 n8n 控制台
 免费套餐提供构建和测试工作流所需的一切。若需要更多执行时间或高级功能,可随时升级。
免费套餐提供构建和测试工作流所需的一切。若需要更多执行时间或高级功能,可随时升级。
### 选项 B:使用 Docker 自托管
如果您希望在自有基础设施上运行 n8n,可以使用 Docker 快速完成设置。
**先决条件:**
* 计算机已安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)
* 具备基本的命令行/终端使用经验
**安装步骤:**
1. 打开终端或命令提示符
2. 创建一个 Docker 卷以持久化工作流数据:
```bash theme={null}
docker volume create n8n_data
```
该数据卷用于存储你的工作流、凭据和执行历史,即使重启容器也会保留。
3. 运行 n8n Docker 容器:
```bash theme={null}
docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8n
```
 4. 等待 n8n 启动。你会看到输出显示服务器已在运行
5. 打开浏览器,访问 `http://localhost:5678`
6. 使用邮箱注册,创建你的 n8n 账户
4. 等待 n8n 启动。你会看到输出显示服务器已在运行
5. 打开浏览器,访问 `http://localhost:5678`
6. 使用邮箱注册,创建你的 n8n 账户
 你的自托管 n8n 实例已在本地运行。界面与 n8n Cloud 完全一致,因此无论你选择哪种方案,都可以继续按照本指南的其余部分操作。
`--rm` 标志会在你停止容器时自动删除容器,但你的数据会安全保存在 `n8n_data` 卷中。用于生产环境时,请参阅 [n8n 自托管文档](https://docs.n8n.io/hosting/) 了解更高级的配置选项。
你的自托管 n8n 实例已在本地运行。界面与 n8n Cloud 完全一致,因此无论你选择哪种方案,都可以继续按照本指南的其余部分操作。
`--rm` 标志会在你停止容器时自动删除容器,但你的数据会安全保存在 `n8n_data` 卷中。用于生产环境时,请参阅 [n8n 自托管文档](https://docs.n8n.io/hosting/) 了解更高级的配置选项。
### 了解 n8n 界面
首次登录 n8n 时,你会看到主仪表盘:
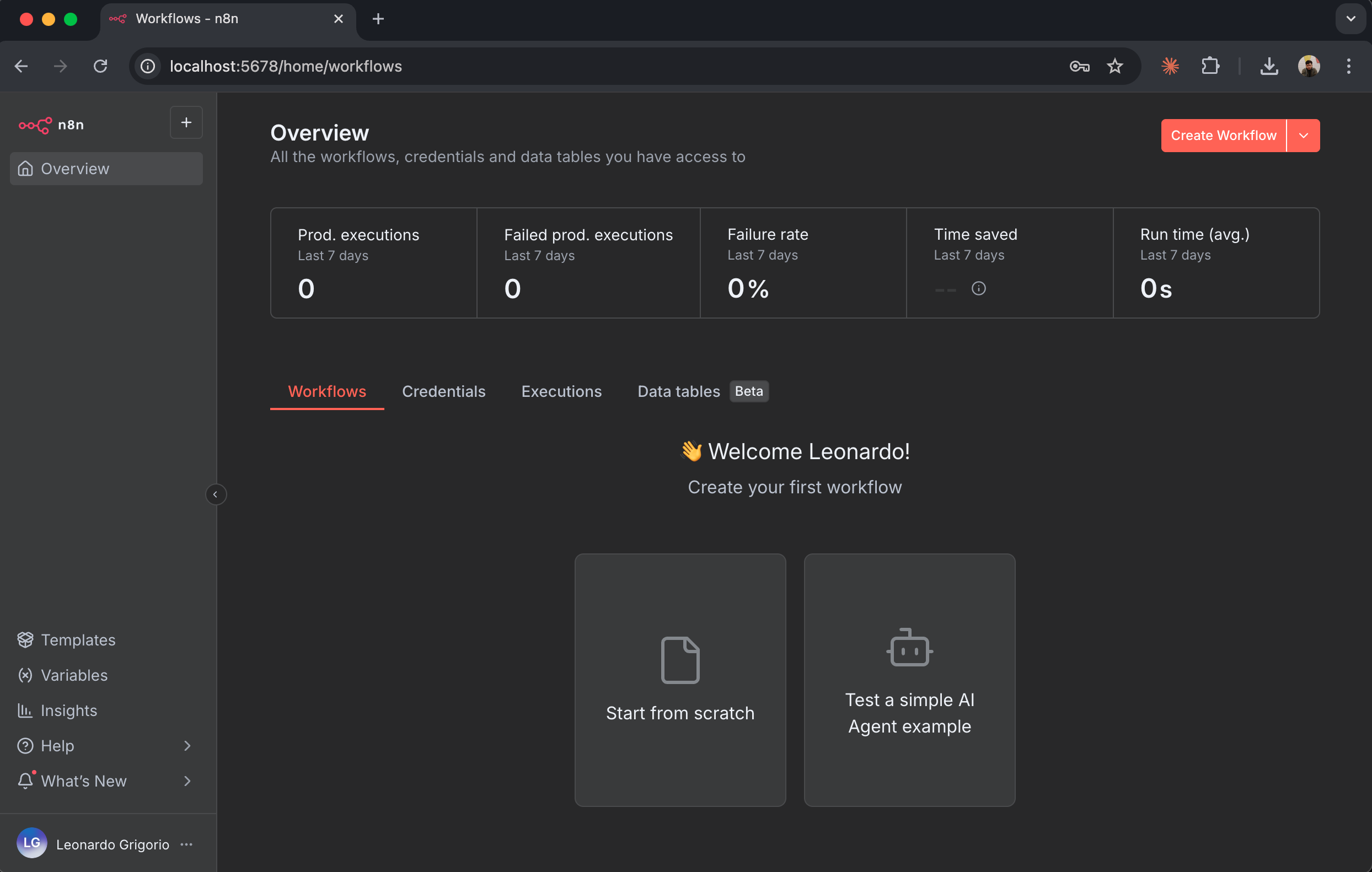 关键界面元素:
* **Workflows**:已保存的自动化流程会显示在这里
* **Executions**:工作流运行历史
* **Credentials**:已存储的 API 密钥与身份验证令牌
* **Settings**:账户与工作区设置
点击“Create New Workflow”打开工作流编辑器。
关键界面元素:
* **Workflows**:已保存的自动化流程会显示在这里
* **Executions**:工作流运行历史
* **Credentials**:已存储的 API 密钥与身份验证令牌
* **Settings**:账户与工作区设置
点击“Create New Workflow”打开工作流编辑器。
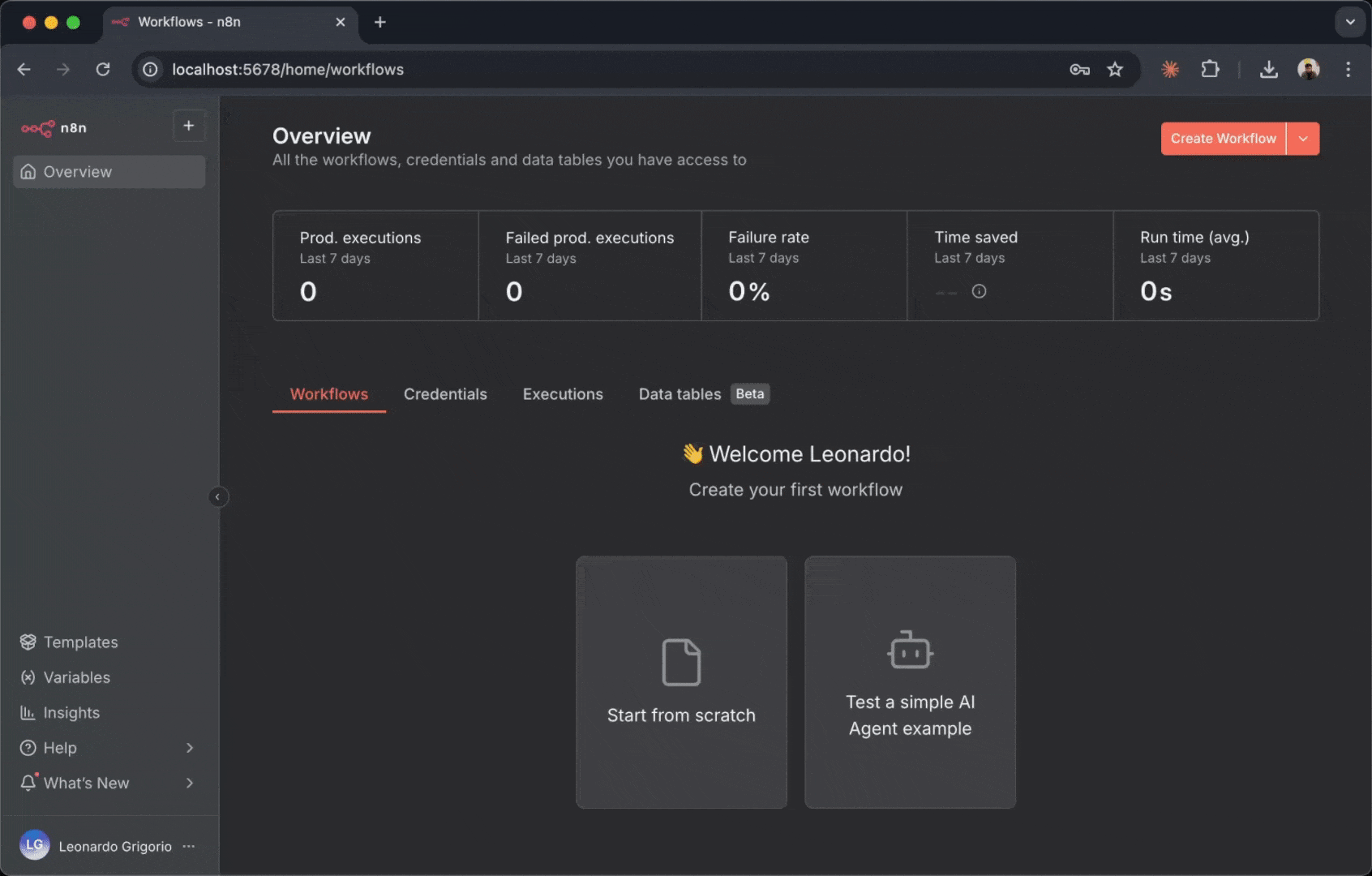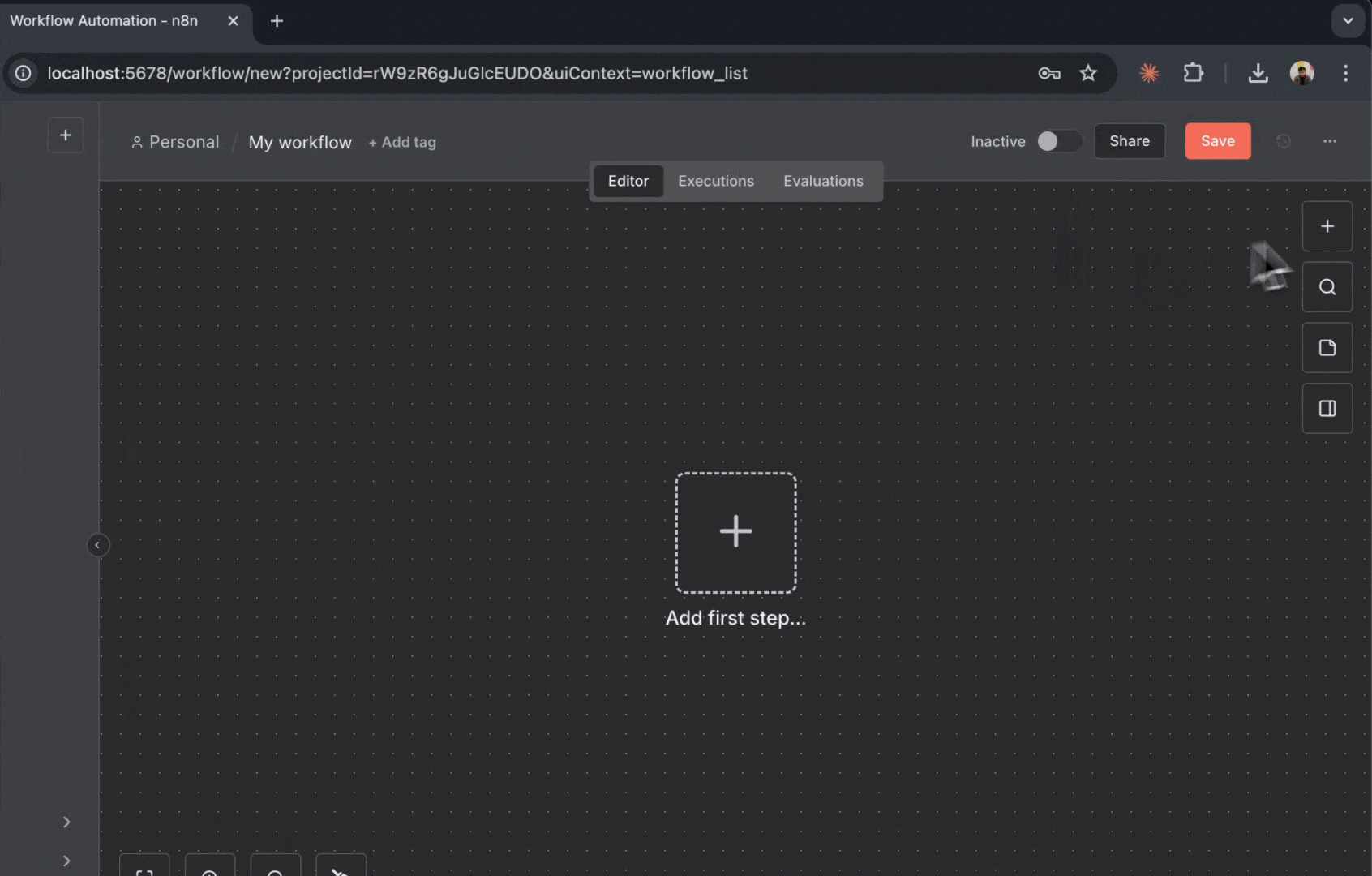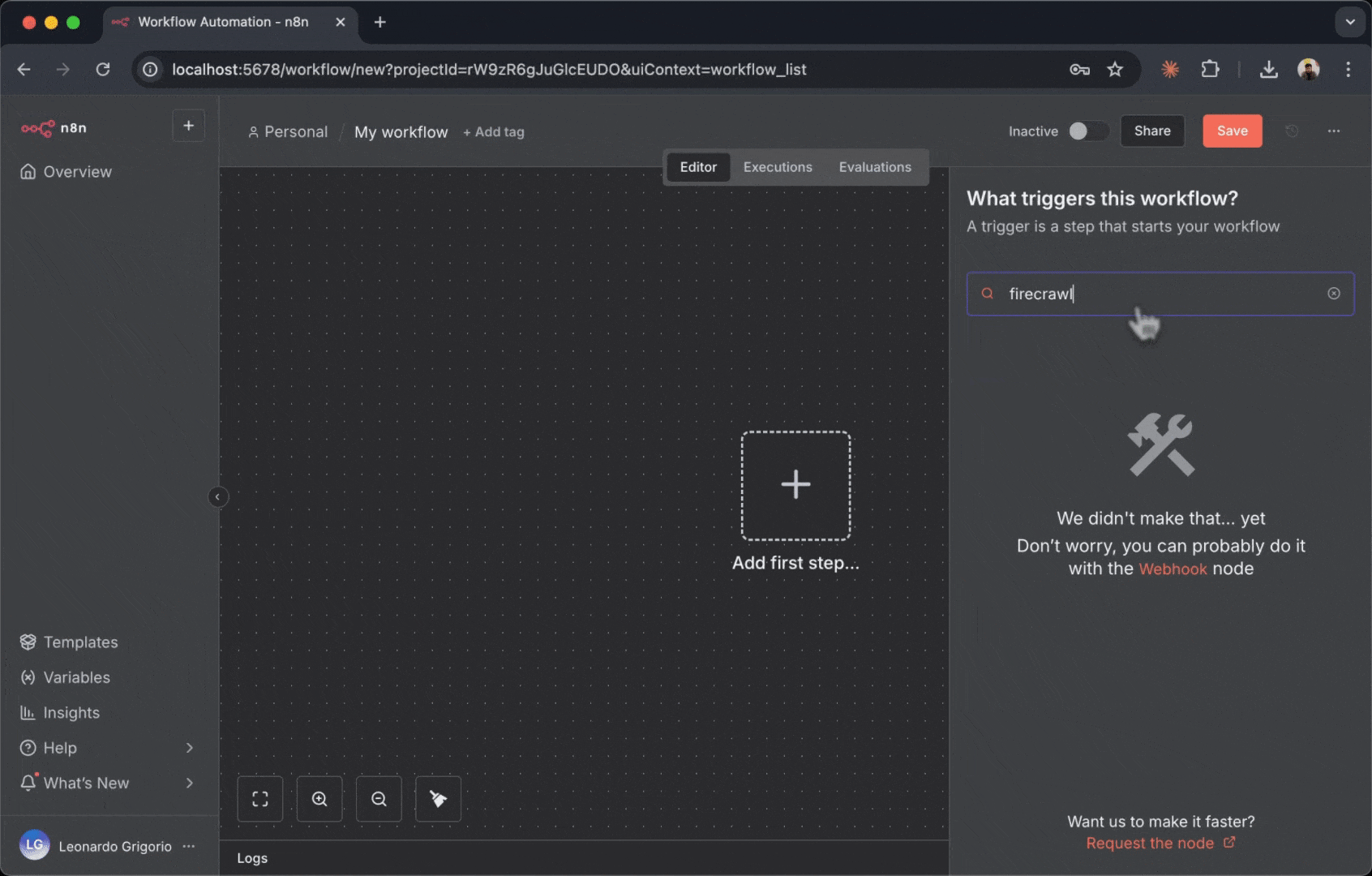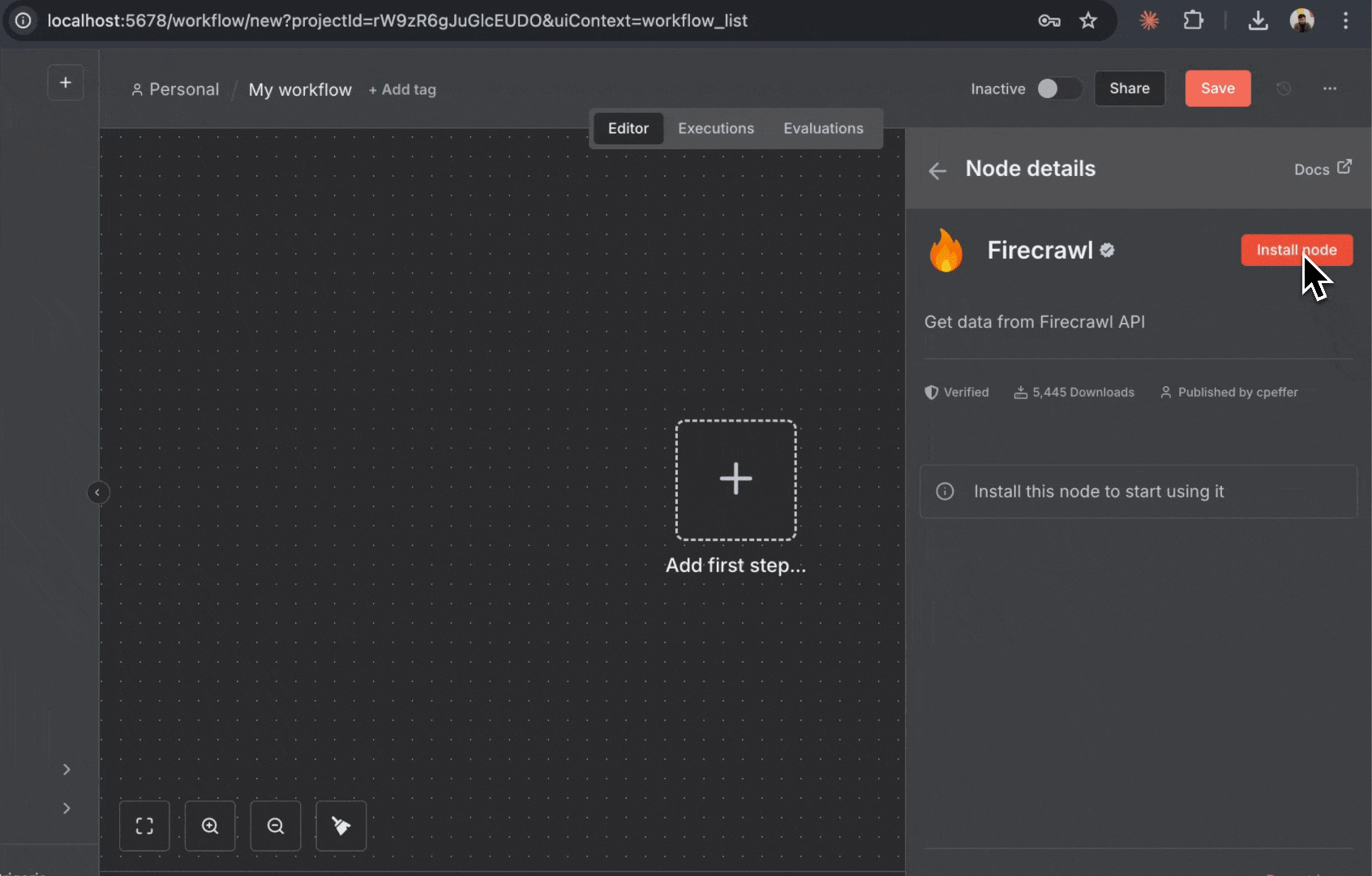
### 工作流画布
工作流编辑器是你构建自动化流程的地方:
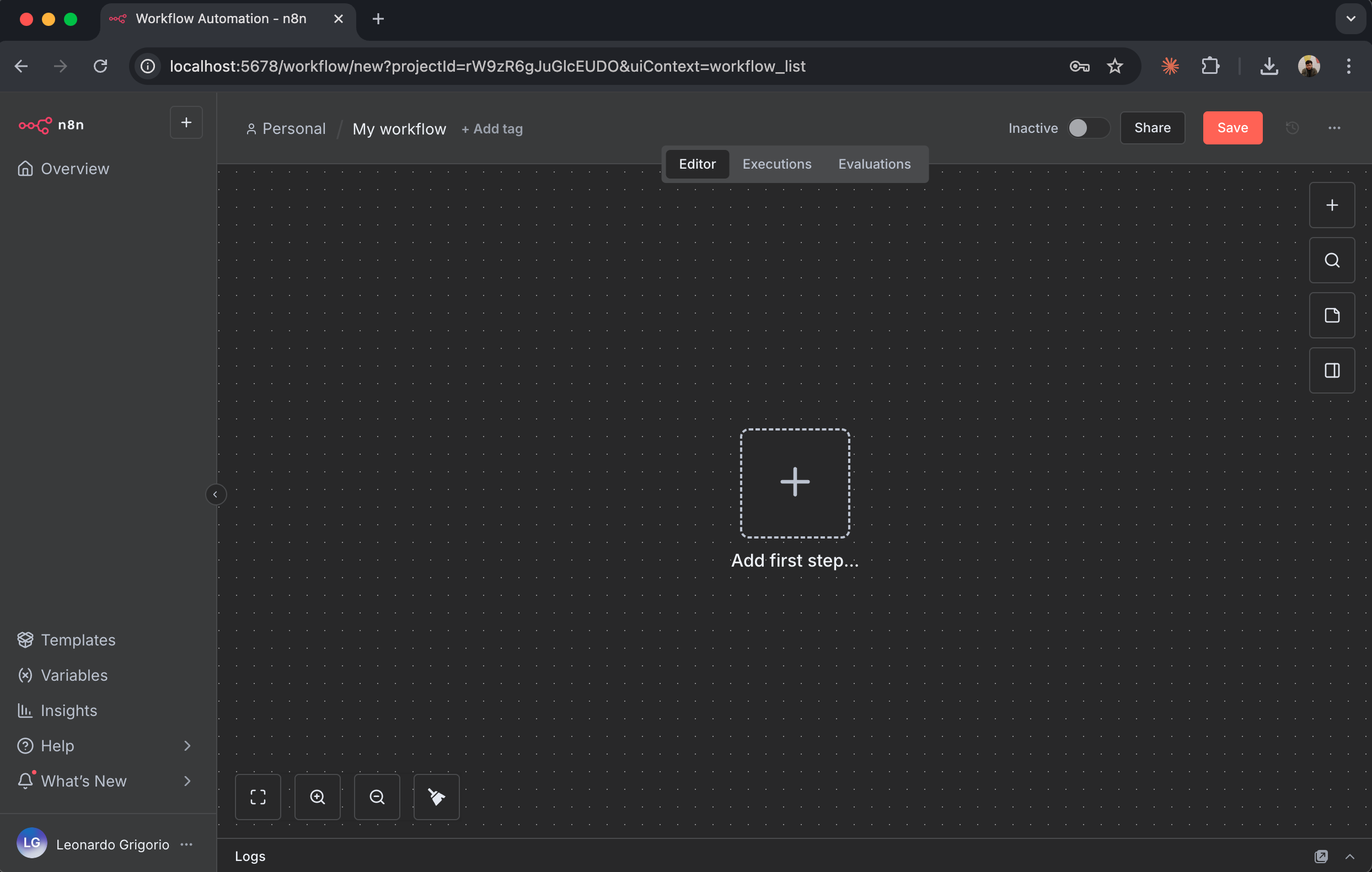 重要元素:
* **画布 (Canvas) **:放置并连接节点的主区域
* **添加节点按钮 (+) **:点击以向工作流添加新节点
* **节点面板 (Node Panel) **:点击“+”后打开,显示所有可用节点
* **执行工作流 (Execute Workflow) **:手动运行工作流进行测试
* **保存 (Save) **:保存你的工作流配置
现在,通过添加 Firecrawl 节点来构建你的第一个工作流。
重要元素:
* **画布 (Canvas) **:放置并连接节点的主区域
* **添加节点按钮 (+) **:点击以向工作流添加新节点
* **节点面板 (Node Panel) **:点击“+”后打开,显示所有可用节点
* **执行工作流 (Execute Workflow) **:手动运行工作流进行测试
* **保存 (Save) **:保存你的工作流配置
现在,通过添加 Firecrawl 节点来构建你的第一个工作流。
## 步骤 3:安装并配置 Firecrawl 节点
n8n 原生支持 Firecrawl。您将安装该节点,并使用之前创建的 API 密钥将其连接到您的 Firecrawl 帐户。
### 将 Firecrawl 节点添加到你的工作流
1. 在新建的工作流画布中,点击中央的“**+**”按钮
2. 右侧会打开节点选择面板
3. 在顶部搜索框中输入“**Firecrawl**”
4. 你会在搜索结果中看到 Firecrawl 节点
 5. 点击 Firecrawl 节点旁的“**Install**”
6. 等待安装完成 (通常只需几秒)
7. 安装完成后,点击 Firecrawl 节点将其添加到画布中
5. 点击 Firecrawl 节点旁的“**Install**”
6. 等待安装完成 (通常只需几秒)
7. 安装完成后,点击 Firecrawl 节点将其添加到画布中
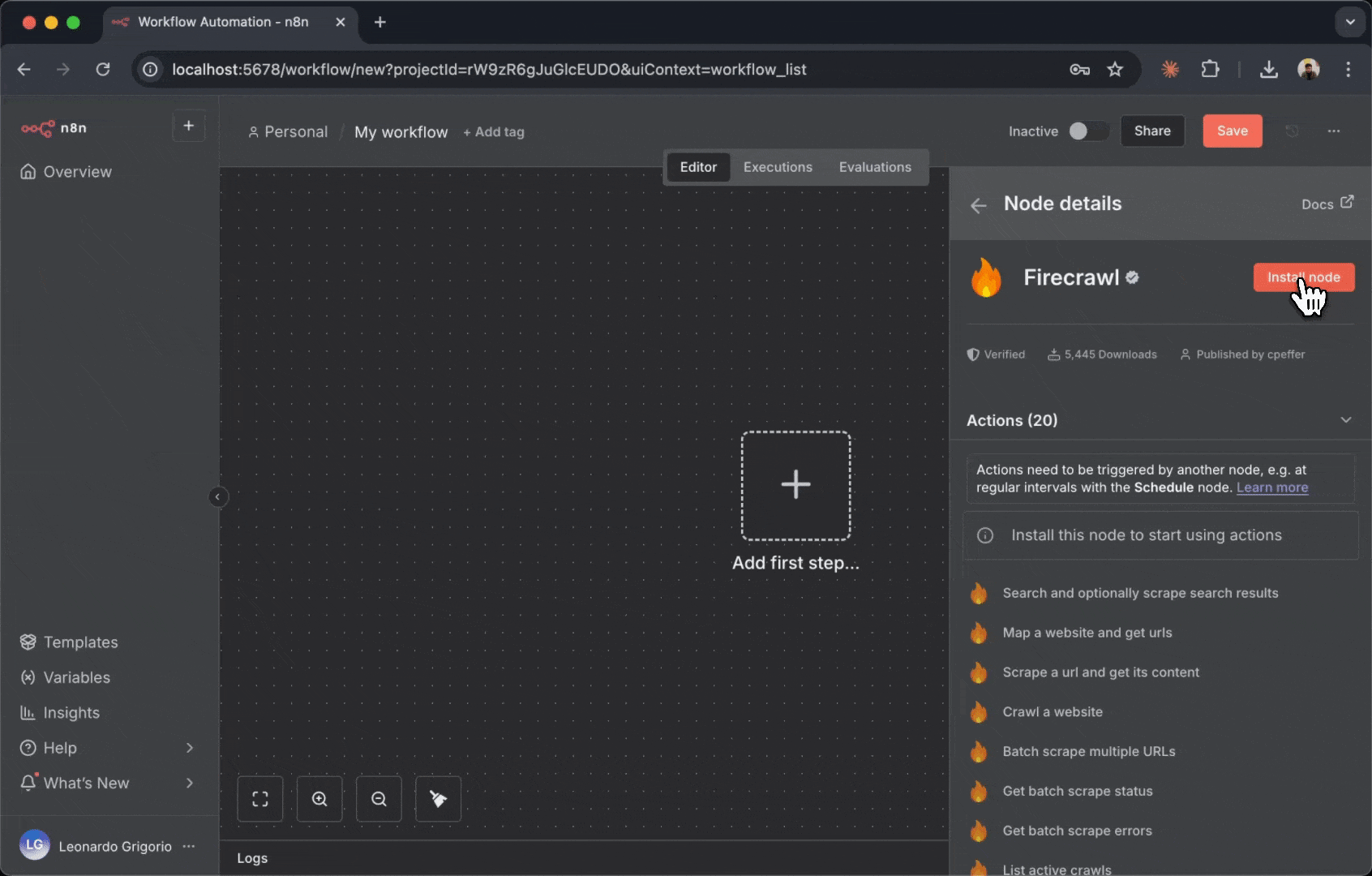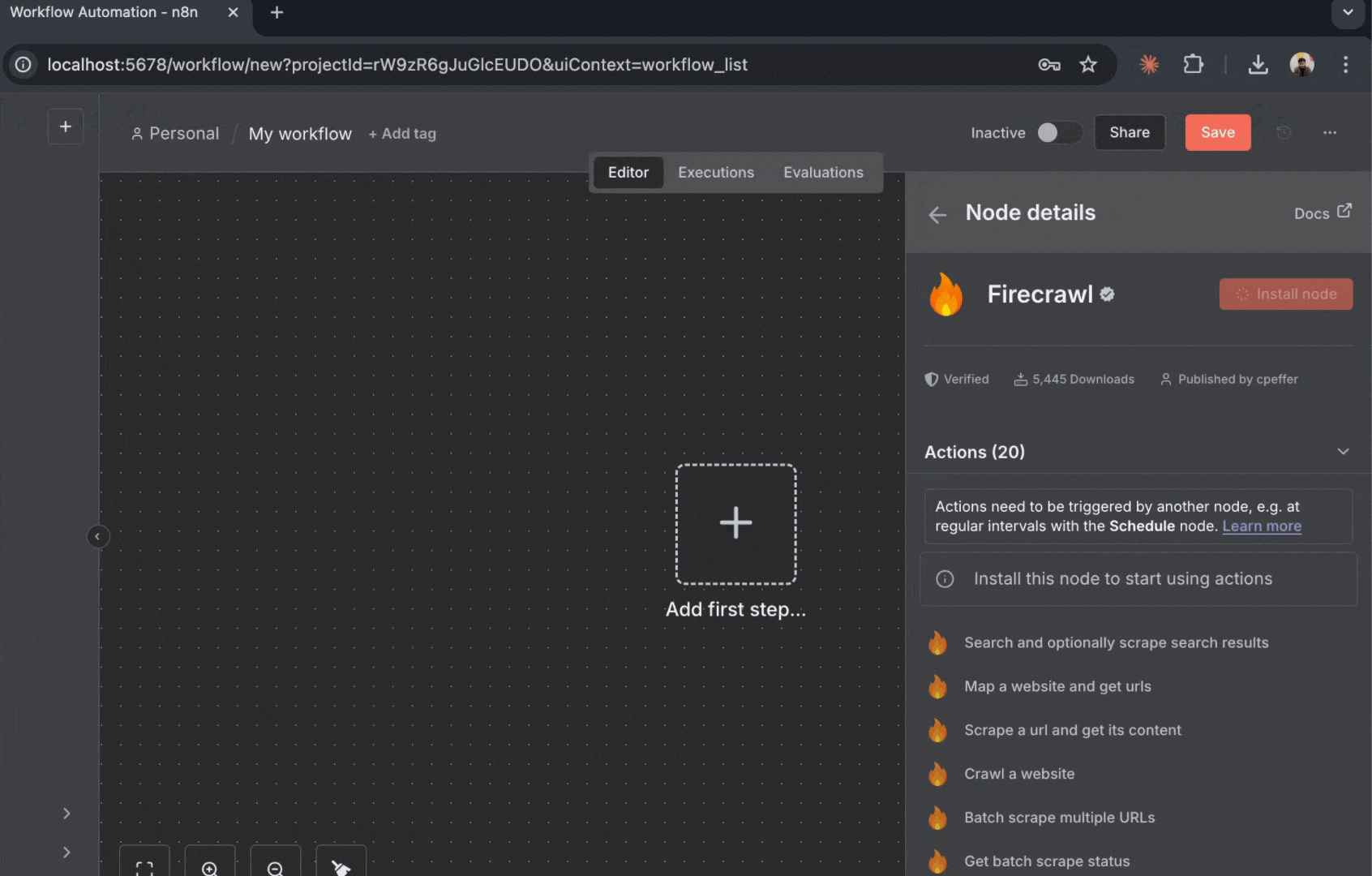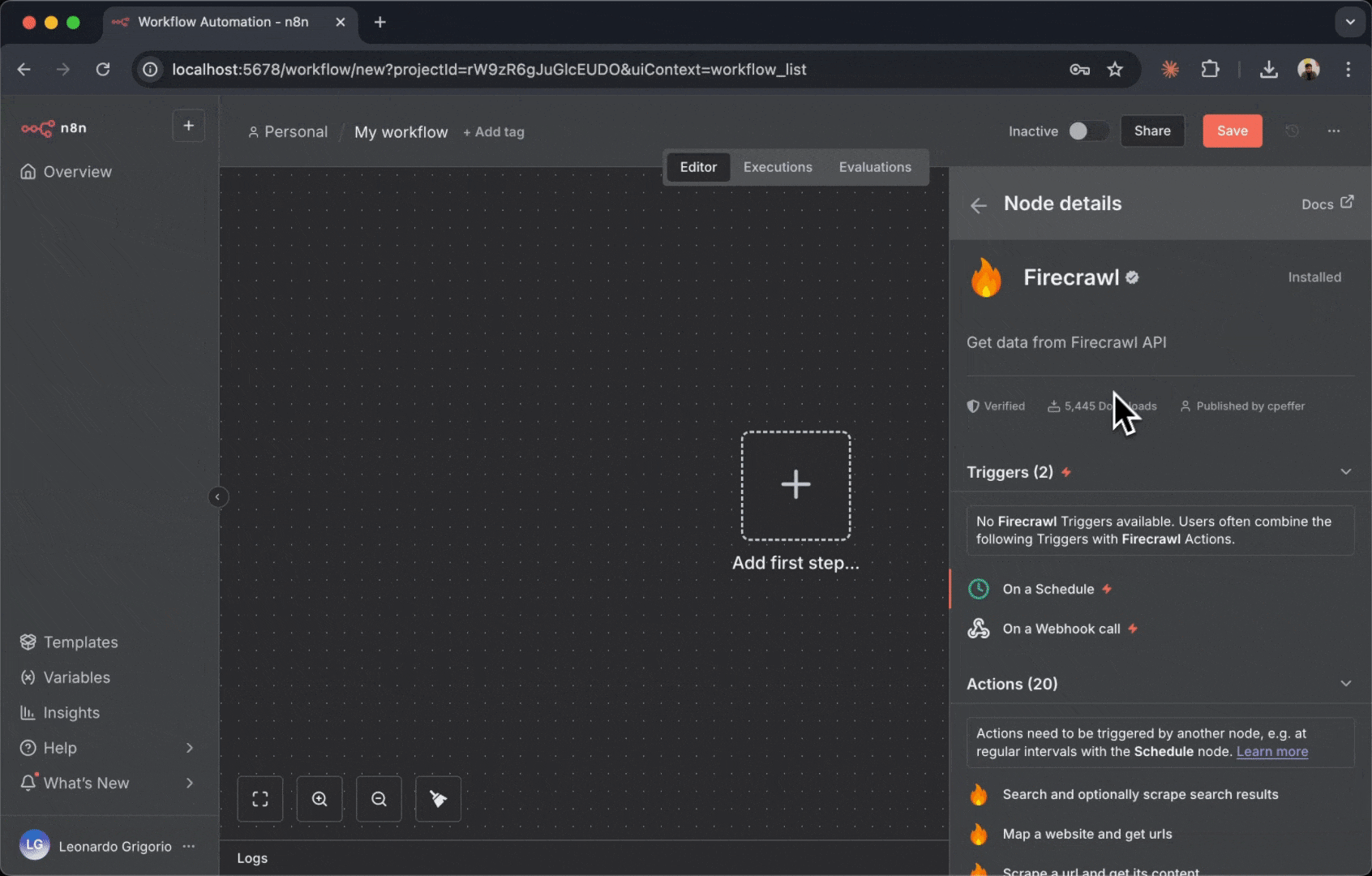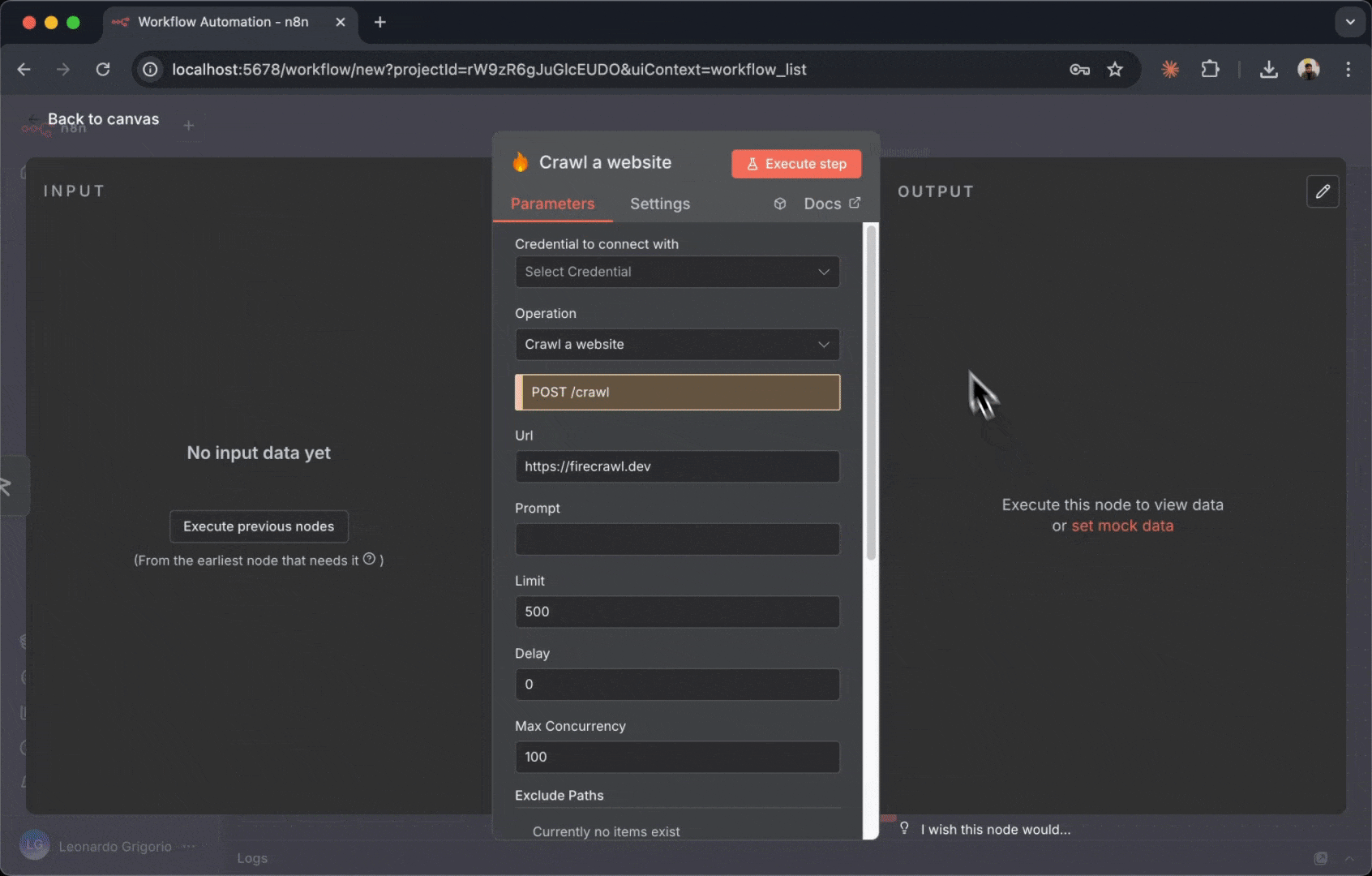 Firecrawl 节点会以带有 Firecrawl 标志的方框形式出现在你的画布上。该节点代表你工作流中的一次 Firecrawl 操作。
Firecrawl 节点会以带有 Firecrawl 标志的方框形式出现在你的画布上。该节点代表你工作流中的一次 Firecrawl 操作。
### 连接你的 Firecrawl API 密钥
**n8n Cloud 用户:** 包含免费 Hobby (入门) 套餐和 100,000 额度的限时优惠已结束。添加 Firecrawl 节点时,你仍然可以使用一键式 **“Connect to Firecrawl”** OAuth 按钮。这会自动创建一个与你的 n8n 账户关联的全新 Firecrawl 团队,并授予 **10,000 免费额度**。这些额度不包含 Hobby (入门) 套餐升级。要在 [Firecrawl Dashboard](https://www.firecrawl.dev/app/usage) 中查看这些额度,请确保你已通过左上角的团队选择器切换到与你的 n8n 关联的团队。
在使用 Firecrawl 节点之前,你需要使用 API 密钥对其进行身份验证:
1. 点击 Firecrawl 节点框,在右侧打开配置面板
2. 在顶部你会看到一个 “Credential to connect with” 下拉菜单
3. 首次使用时,点击 “Create New Credential”
 4. 将打开凭据配置窗口
5. 为该凭据输入名称 (例如 “My Firecrawl Account”)
6. 在 “API Key” 字段粘贴你的 Firecrawl API 密钥
7. 点击底部的 “Save”
凭据现已保存在 n8n 中。之后使用 Firecrawl 节点时无需再次输入 API 密钥。
4. 将打开凭据配置窗口
5. 为该凭据输入名称 (例如 “My Firecrawl Account”)
6. 在 “API Key” 字段粘贴你的 Firecrawl API 密钥
7. 点击底部的 “Save”
凭据现已保存在 n8n 中。之后使用 Firecrawl 节点时无需再次输入 API 密钥。
### 测试连接
让我们确认你的 Firecrawl 节点已正确连接:
1. 在仍选中 Firecrawl 节点的情况下,查看配置面板
2. 在“Resource”下拉菜单中选择“Scrape a url and get its content”
3. 在“URL”字段中输入:`https://firecrawl.dev`
4. 其余设置先保持默认
5. 点击节点右下角的“Test step”按钮
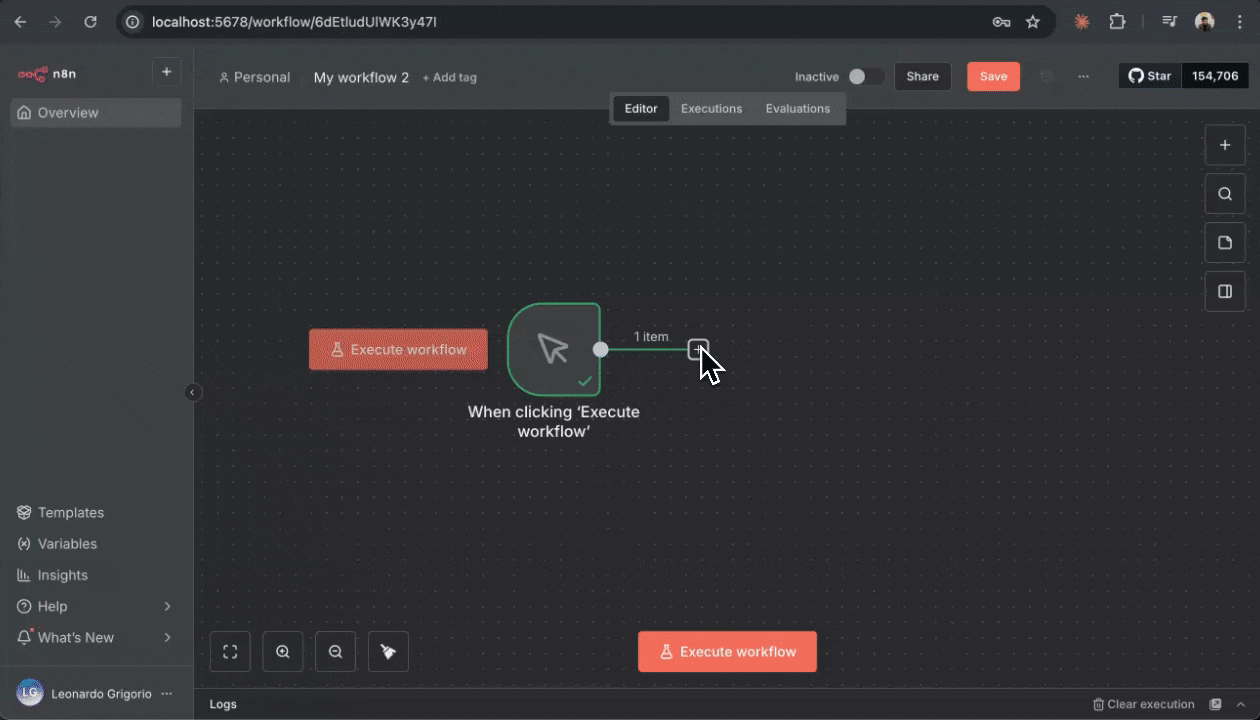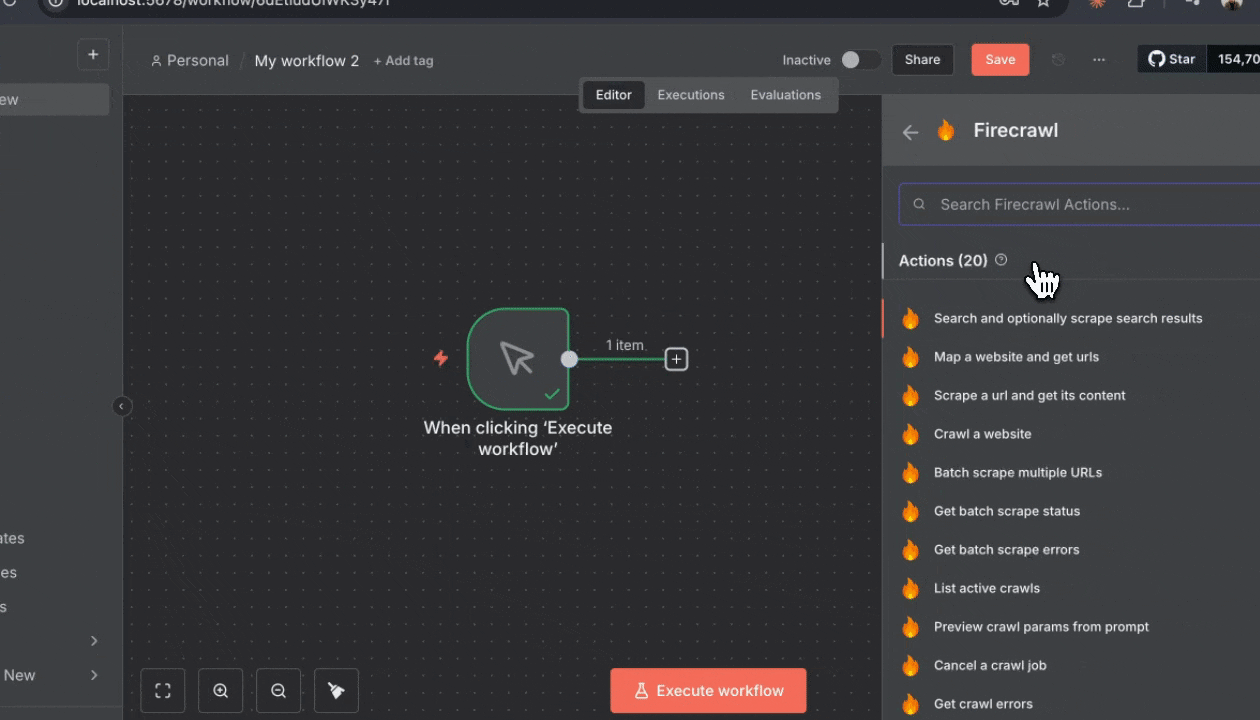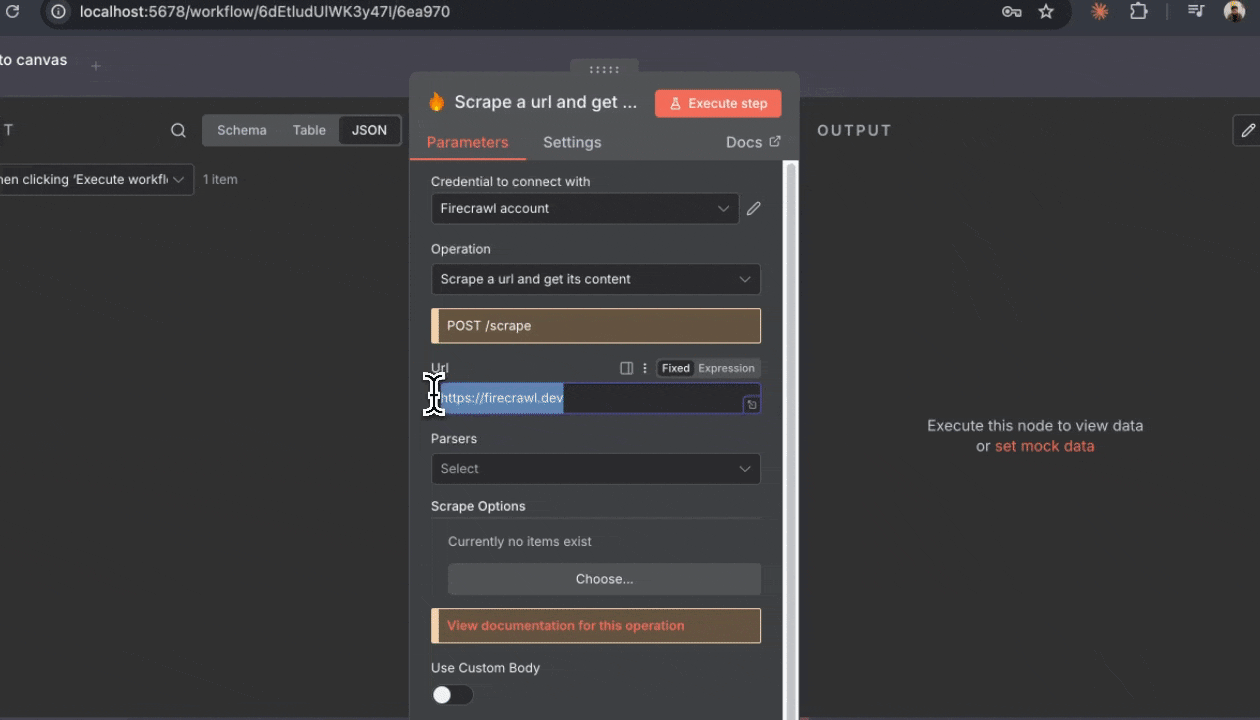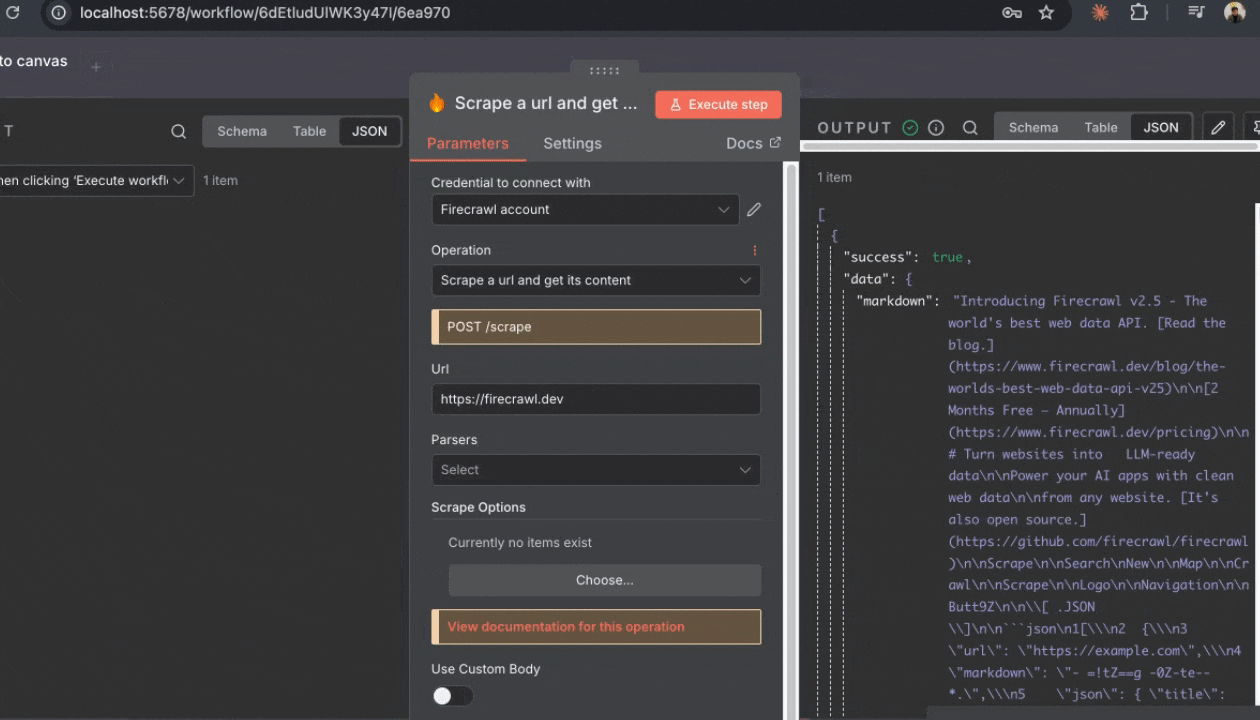 如果一切配置正确,你会在节点下方的输出面板中看到来自 example.com 的抓取结果。
恭喜!你的 Firecrawl 节点现已连接并正常工作。
如果一切配置正确,你会在节点下方的输出面板中看到来自 example.com 的抓取结果。
恭喜!你的 Firecrawl 节点现已连接并正常工作。
## 步骤 4:创建你的 Telegram 机器人
在构建第一个工作流之前,你需要一个 Telegram 机器人来接收通知。Telegram 机器人免费,可通过 Telegram 的 BotFather 轻松创建。
### 使用 BotFather 创建机器人
1. 在手机或桌面端打开 Telegram
2. 搜索“**@BotFather**” (Telegram 的官方机器人)
3. 点击“**Start**”与 BotFather 开始对话
4. 发送命令 `/newbot` 创建新机器人
5. BotFather 会让你为机器人选择一个名称 (这是用户看到的显示名称)
6. 输入类似“**My Firecrawl Bot**”的名称
7. 接下来为机器人选择一个用户名。它必须以“bot”结尾 (例如,“**my\_firecrawl\_updates\_bot**”)
8. 如果该用户名可用,BotFather 会创建你的机器人,并向你发送包含机器人令牌 (token) 的消息
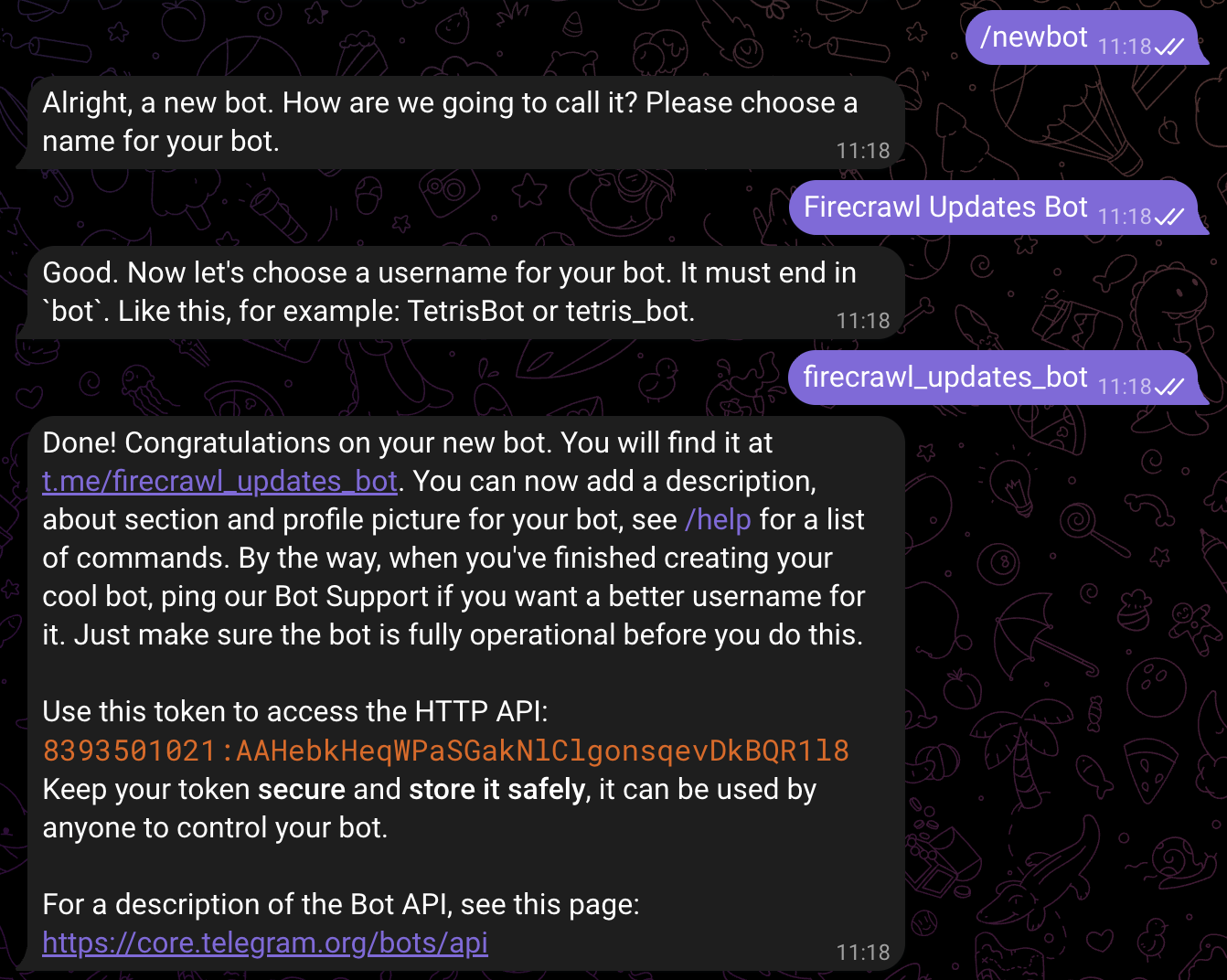 请妥善保存你的机器人令牌 (token) 。该令牌类似密码,允许 n8n 以你的机器人身份发送消息。切勿公开分享。
请妥善保存你的机器人令牌 (token) 。该令牌类似密码,允许 n8n 以你的机器人身份发送消息。切勿公开分享。
### 获取你的聊天 ID
要向自己发送消息,你需要 Telegram 聊天 ID:
1. 打开浏览器并访问此 URL (将 `YOUR_BOT_TOKEN` 替换为你的实际 Bot Token) :
```
https://api.telegram.org/botYOUR_BOT_TOKEN/getUpdates
```
2. 保持此浏览器标签页打开
3. 在 Telegram 中搜索你刚创建的机器人的用户名
4. 点击“**Start**”与机器人开始对话
5. 向机器人发送任意消息 (例如“hello”)
6. 回到浏览器标签页并刷新页面
7. 在 JSON 响应中查找 `"chat":{"id":` 字段
8. `"id":` 后面的数字就是你的聊天 ID (例如 `123456789`)
9. 保存该聊天 ID 以备后用
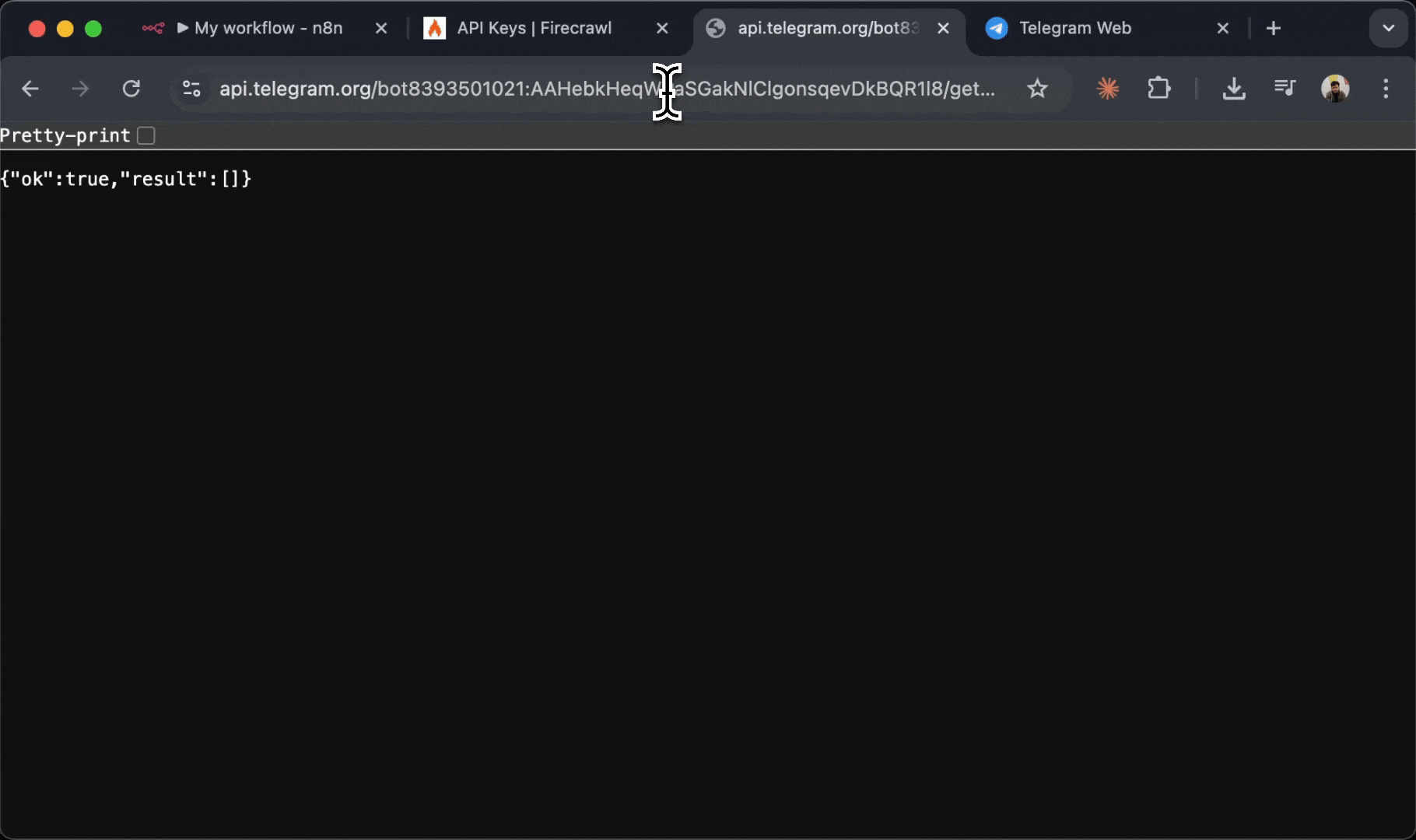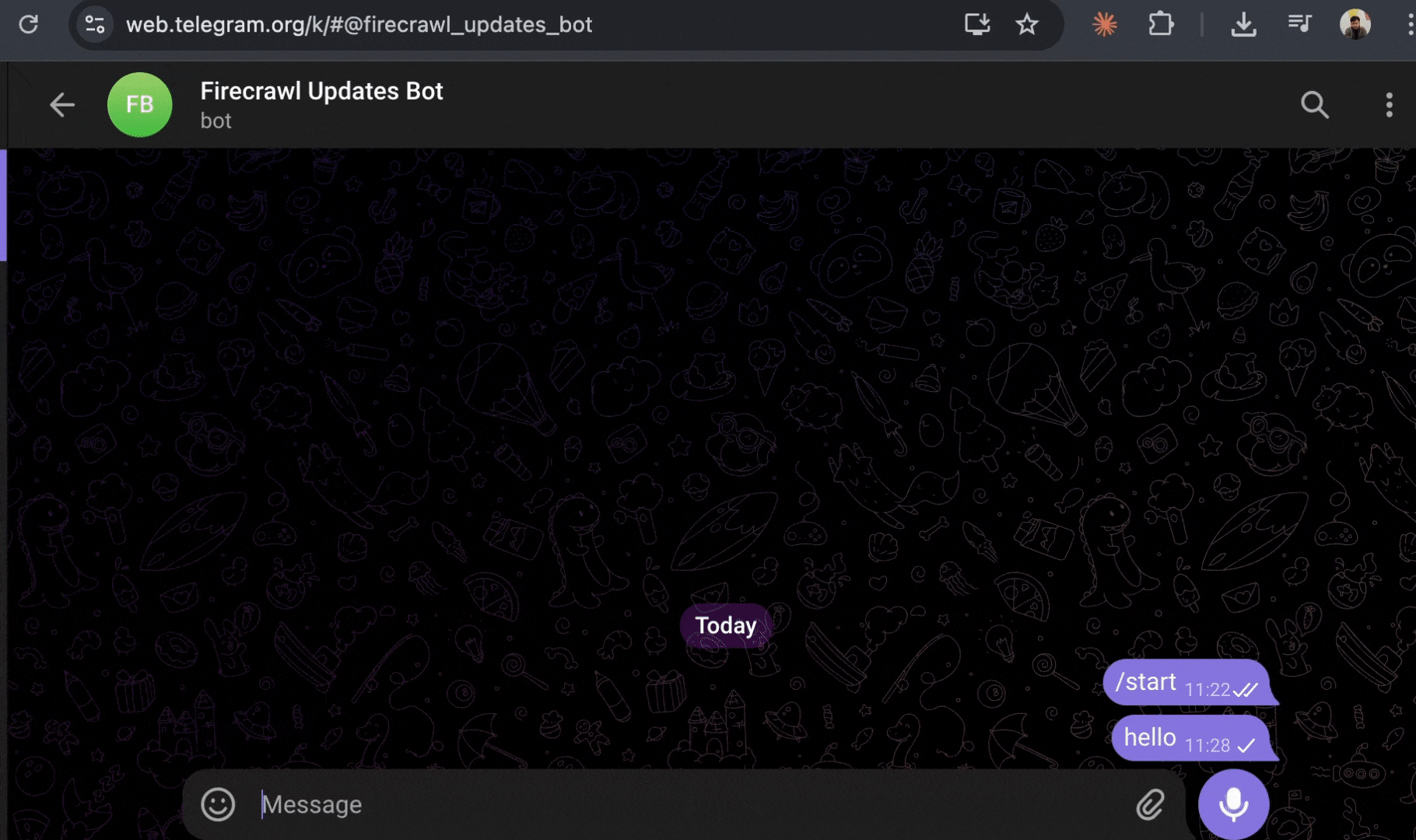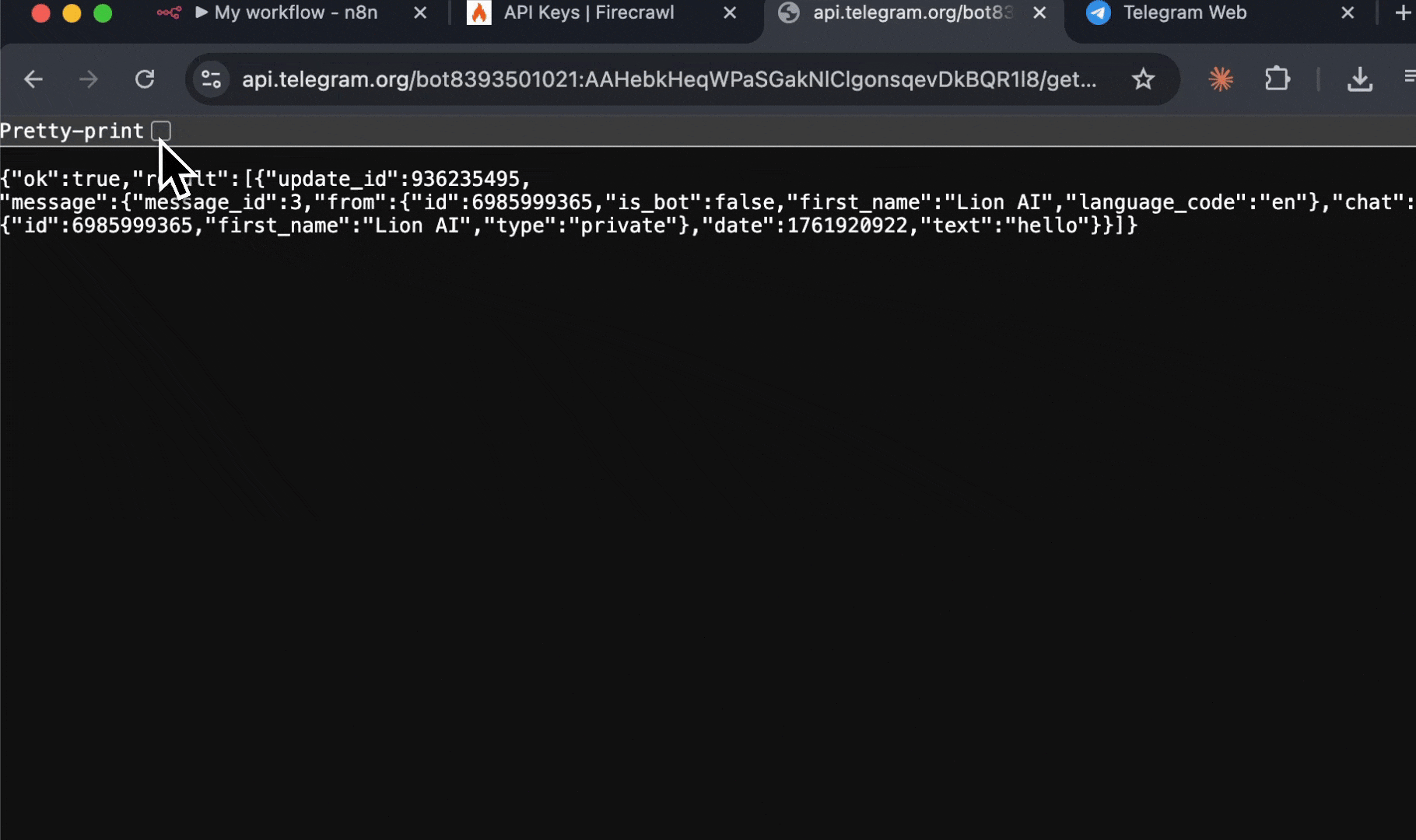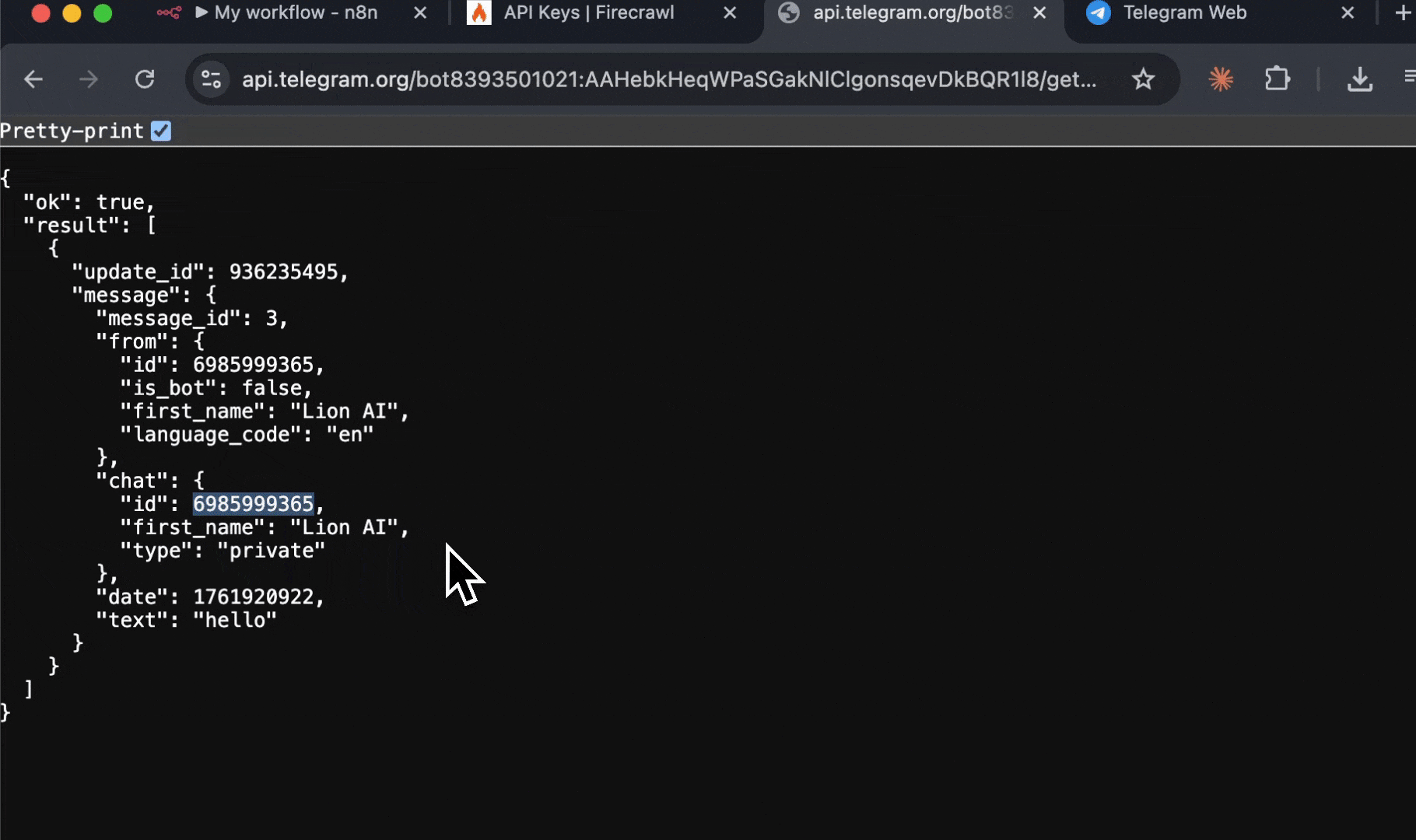 你的聊天 ID 是你与该机器人会话的唯一标识符。你将使用它告诉 n8n 将消息发送到哪里。
现在你已经具备将 Telegram 集成到 n8n 工作流所需的一切。
你的聊天 ID 是你与该机器人会话的唯一标识符。你将使用它告诉 n8n 将消息发送到哪里。
现在你已经具备将 Telegram 集成到 n8n 工作流所需的一切。
## 步骤 5:用 Telegram 构建实用工作流
现在我们来构建三个真实场景的工作流,将信息直接推送到你的 Telegram。这些示例展示了不同的 Firecrawl 操作,以及如何将它们与 Telegram 通知集成。
### 示例 1:每日 Firecrawl 产品更新摘要
每天早晨在 Telegram 接收 Firecrawl 产品更新的每日摘要。
**你将构建:**
* 每天上午 9 点抓取 Firecrawl 的产品更新博客
* 使用 AI 生成内容摘要
* 将摘要发送到你的 Telegram
**步骤说明:**
1. 在 n8n 中创建一个新工作流
2. 添加 **Schedule Trigger** 节点:
* 点击画布上的“**+**”按钮
* 搜索“**Schedule Trigger**”
* 配置:每天上午 9:00
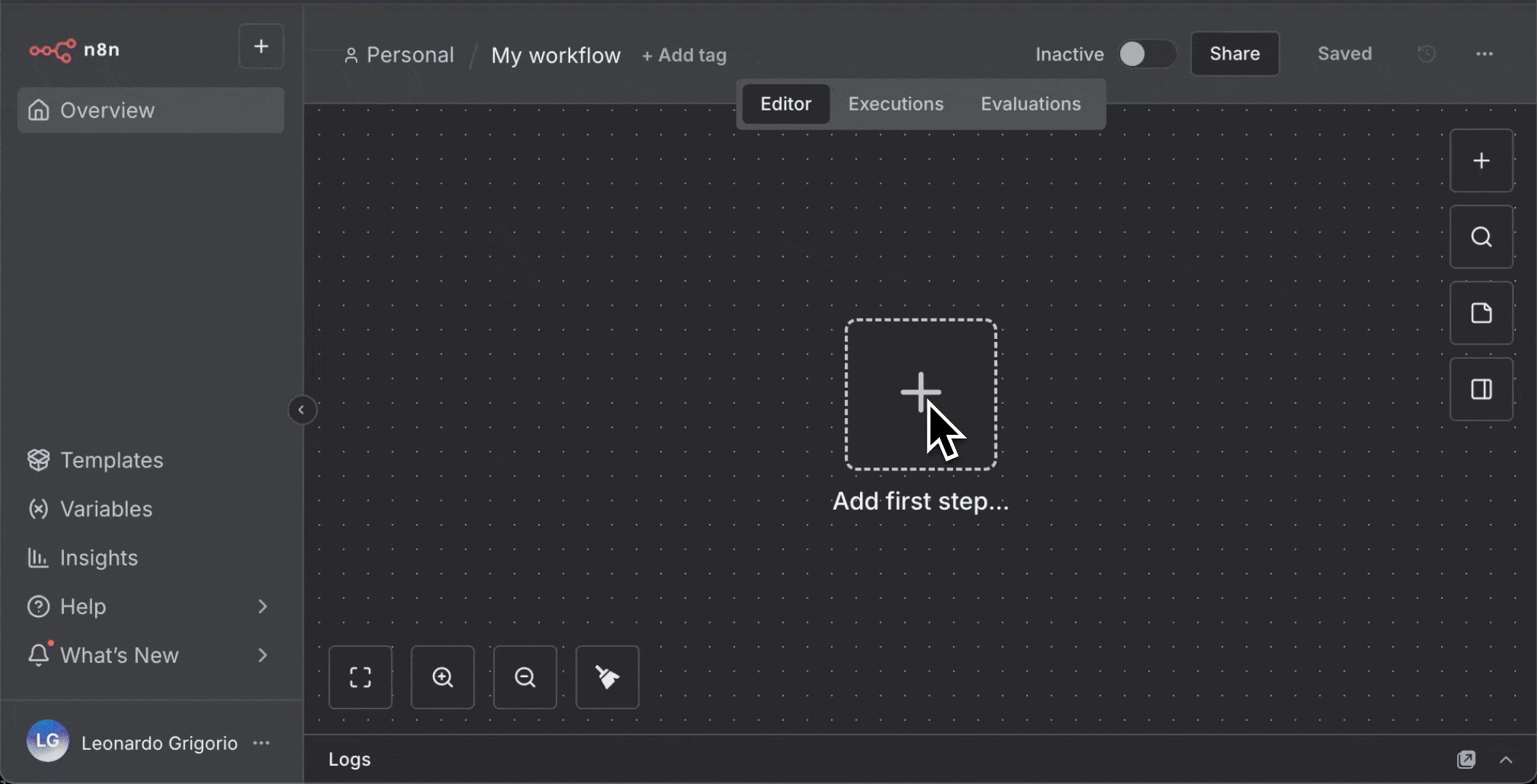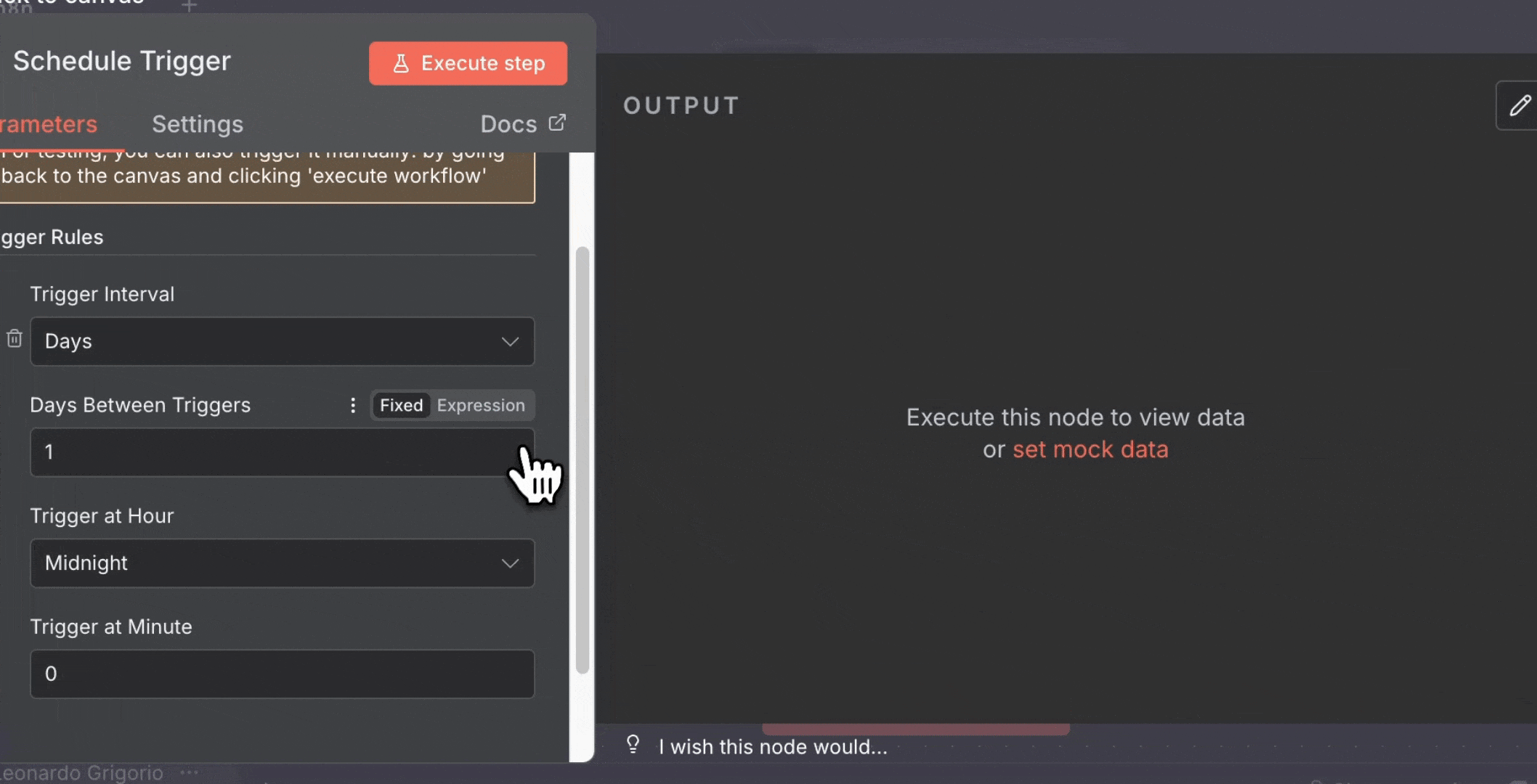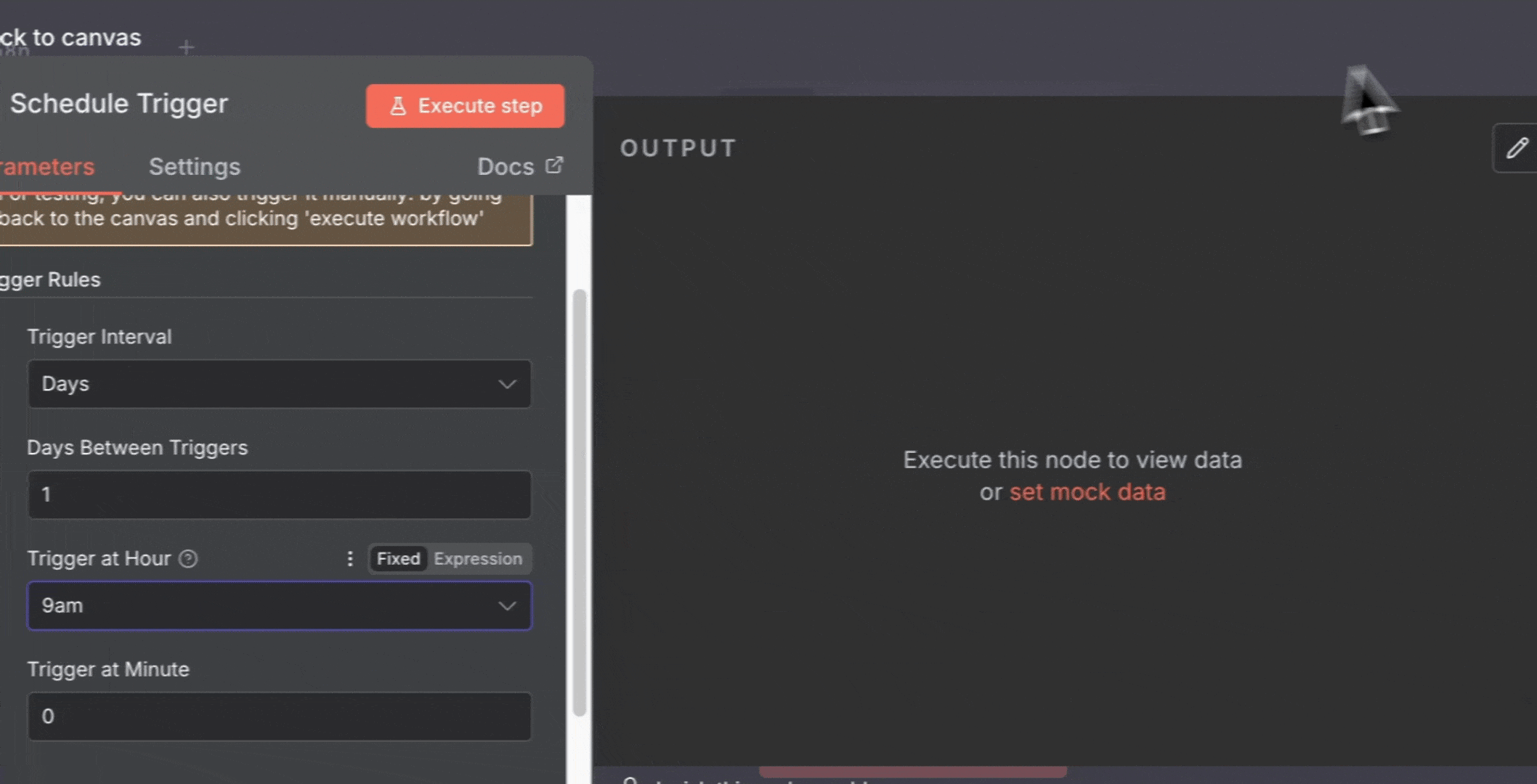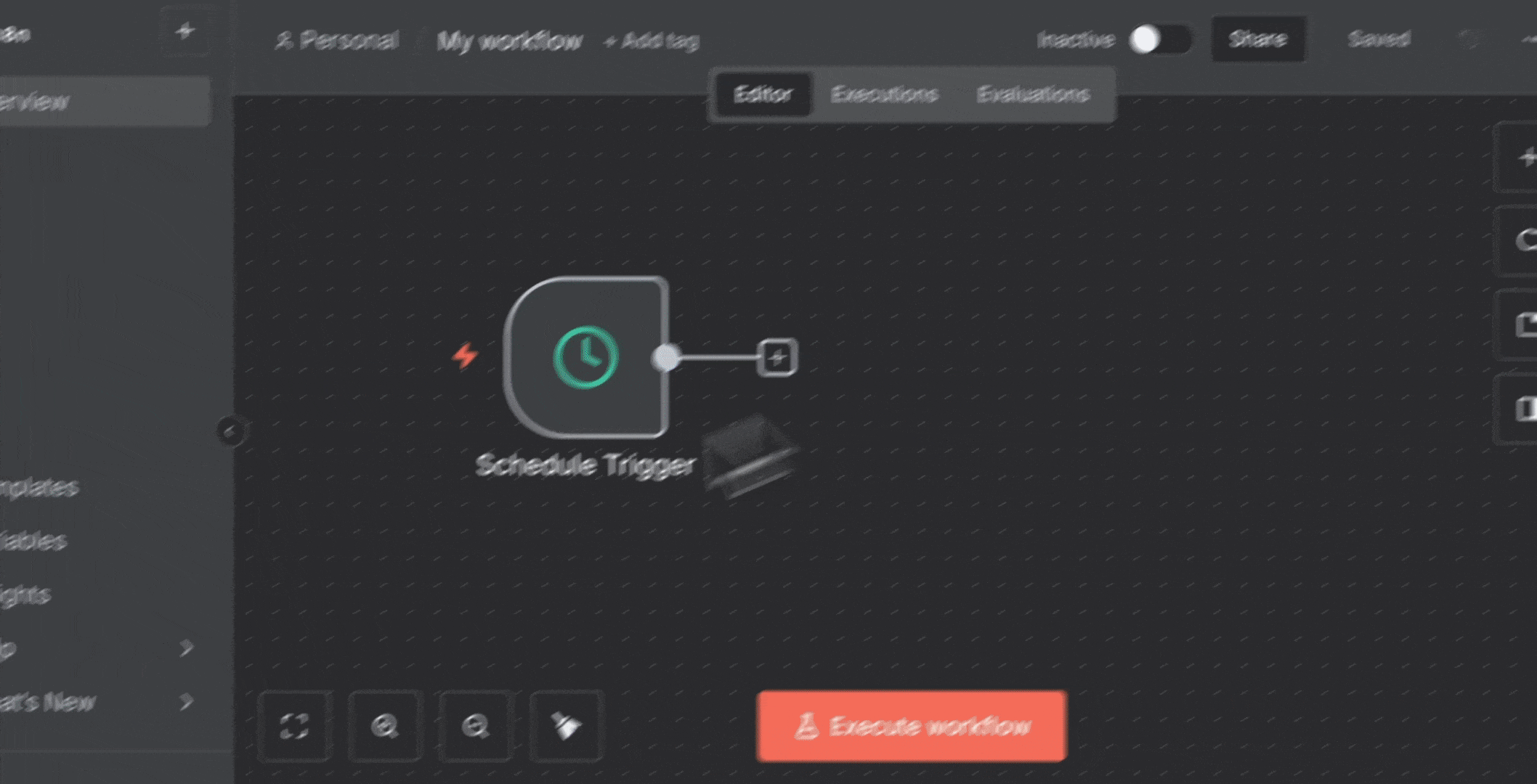 3. 添加 **Firecrawl** 节点:
* 点击 Schedule Trigger 旁边的“**+**”
* 搜索并添加“**Firecrawl**”
* 选择你的 Firecrawl 凭证
* 配置:
* **Resource**: Scrape a url and get its content
* **URL**: `https://www.firecrawl.dev/blog/category/product-updates`
* **Formats**: 选择“Summary”
3. 添加 **Firecrawl** 节点:
* 点击 Schedule Trigger 旁边的“**+**”
* 搜索并添加“**Firecrawl**”
* 选择你的 Firecrawl 凭证
* 配置:
* **Resource**: Scrape a url and get its content
* **URL**: `https://www.firecrawl.dev/blog/category/product-updates`
* **Formats**: 选择“Summary”
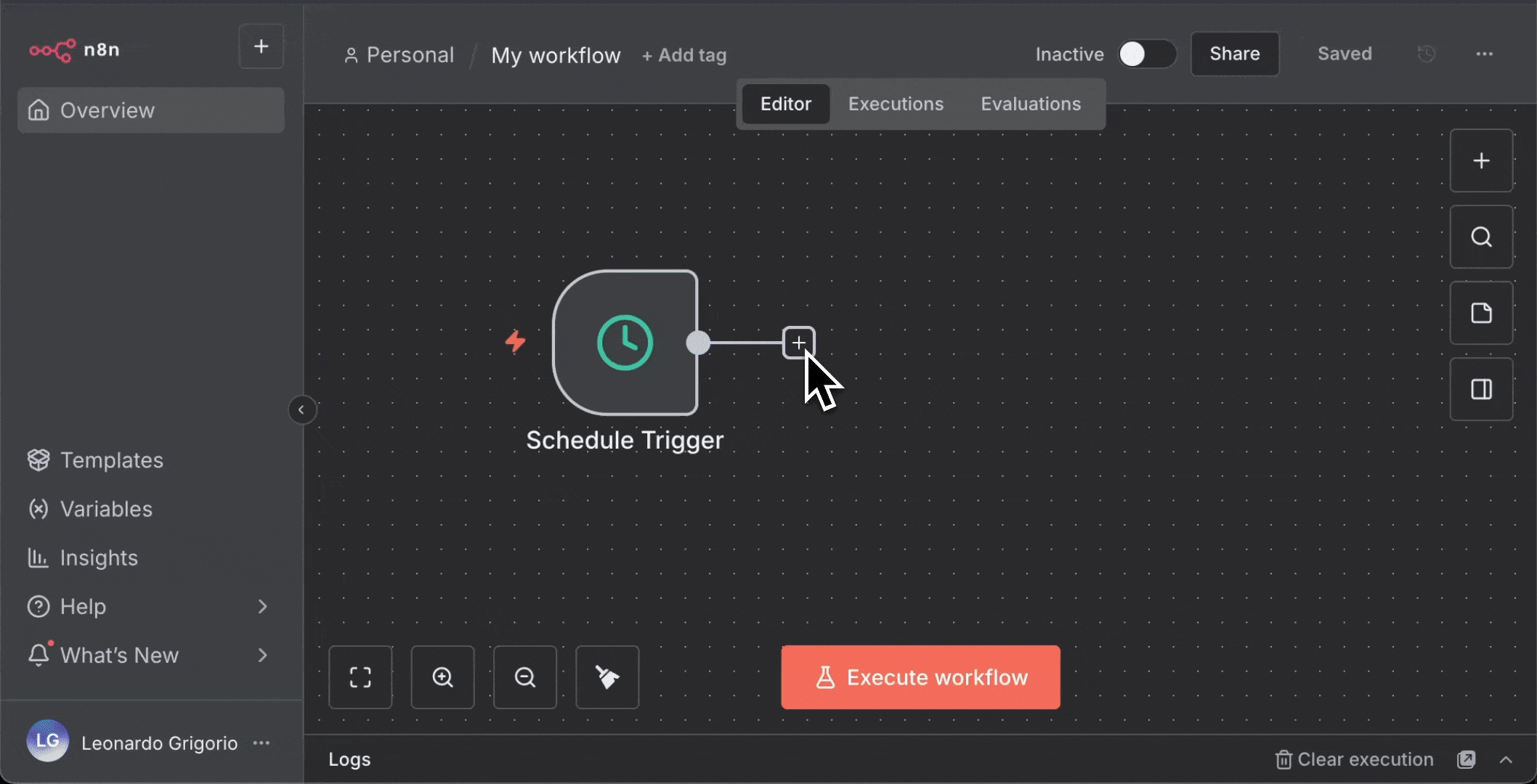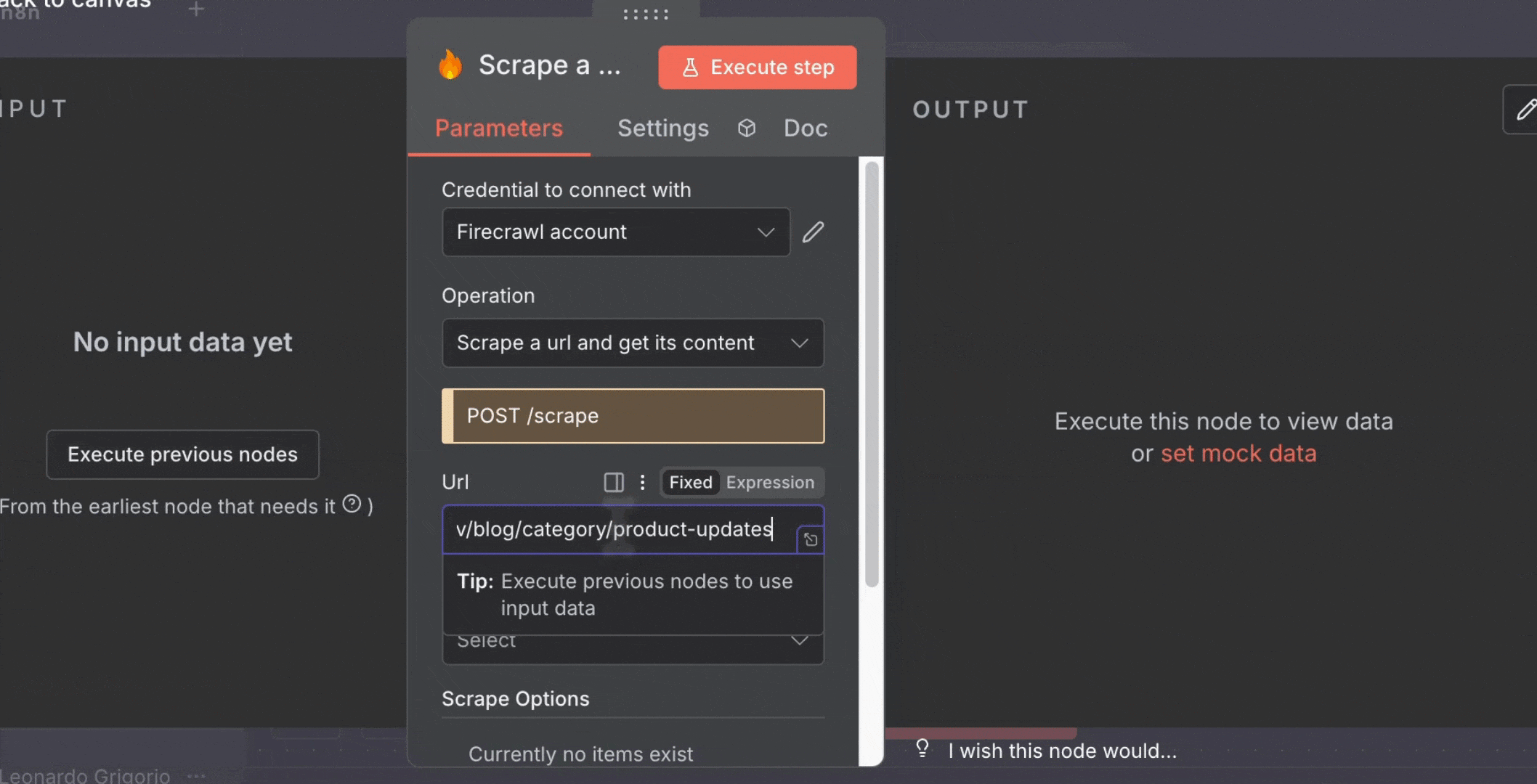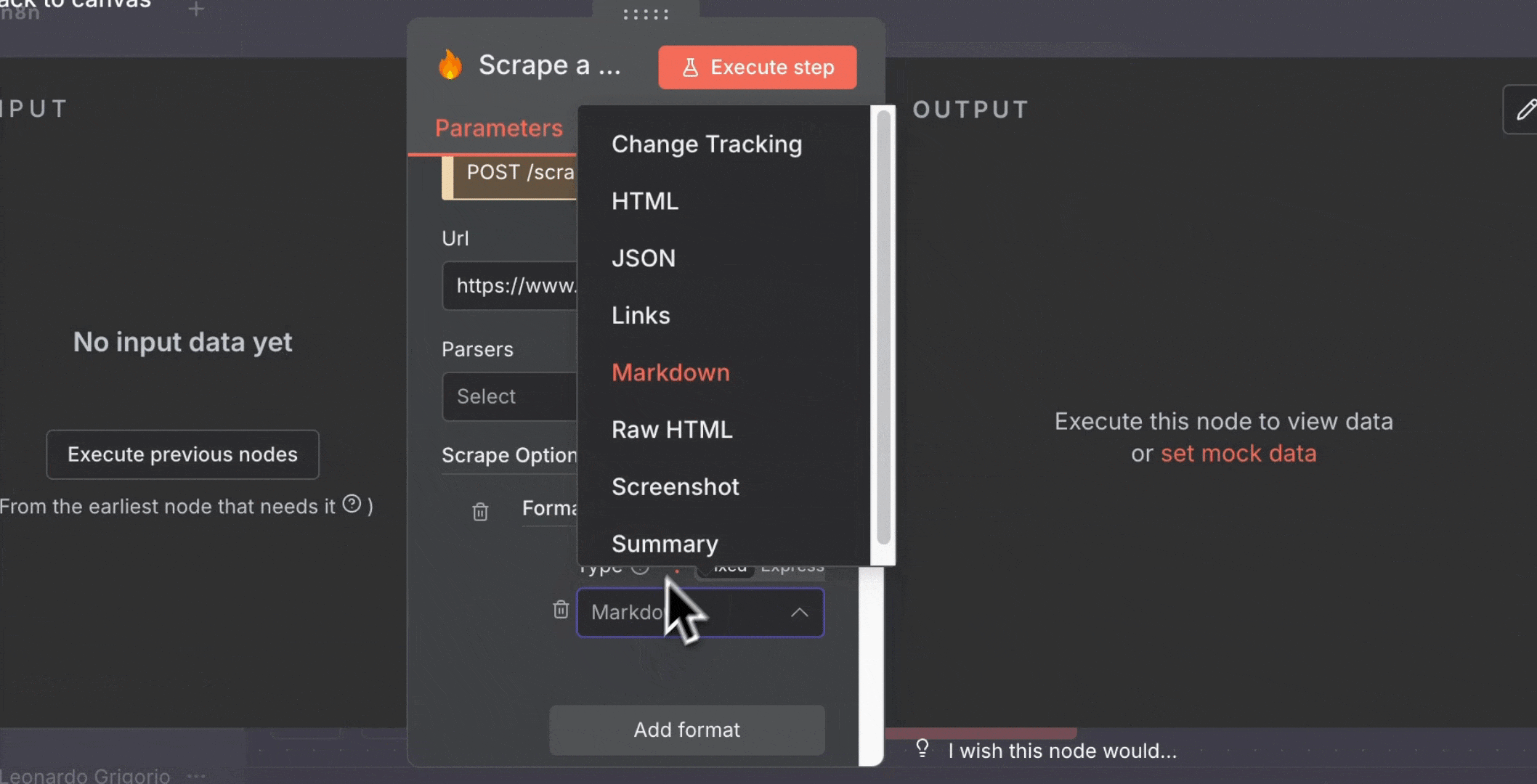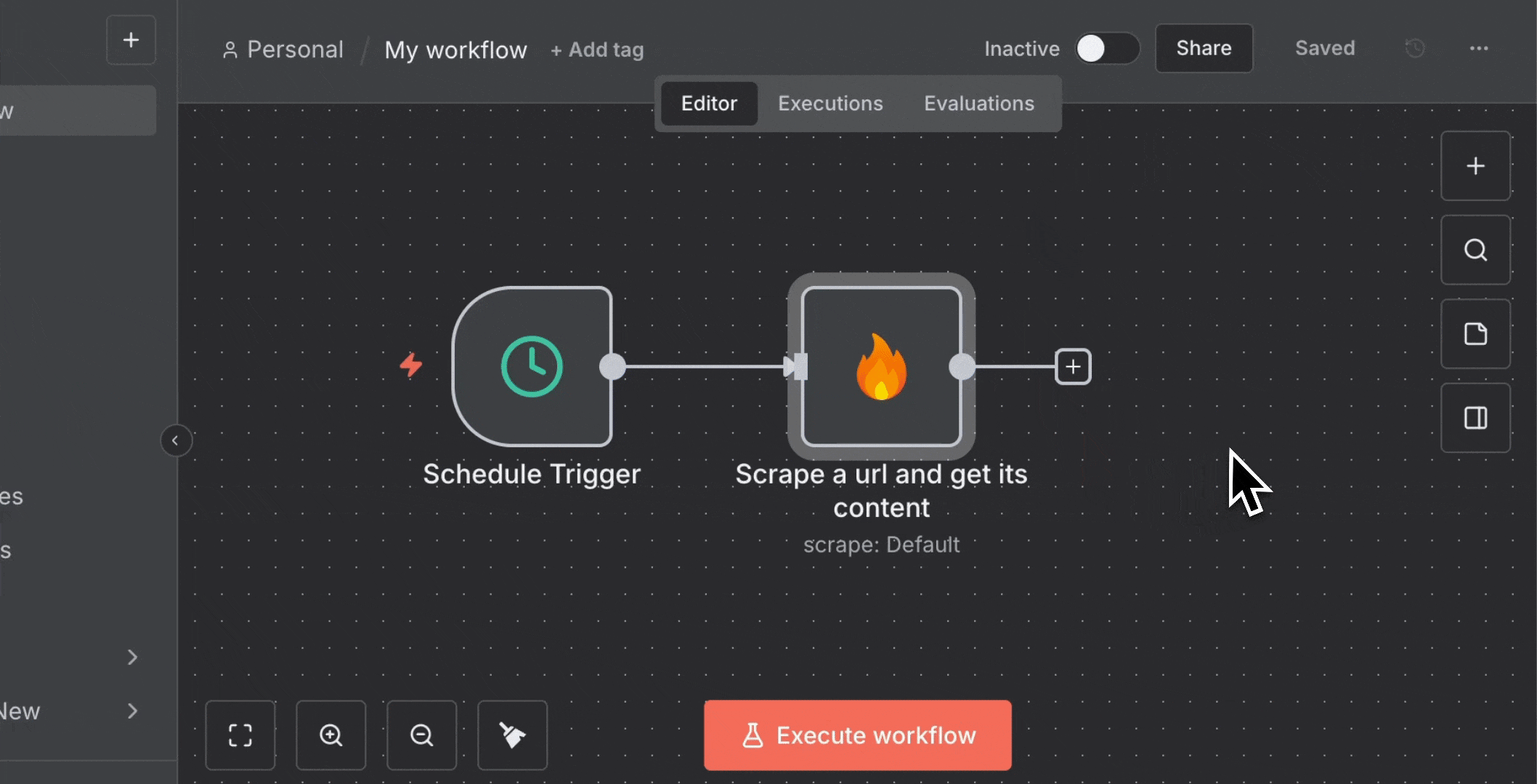 4. 添加 **Telegram** 节点:
* 点击 Firecrawl 旁边的“**+**”
* 搜索“**Telegram**”
* 点击“**Send a text message**”将其添加到画布
5. 设置 Telegram 凭证:
* 点击 Telegram 节点打开其配置
* 在“Credential to connect with”下拉菜单中,点击“**Create New Credential**”
* 粘贴你从 BotFather 获取的 bot token
* 点击“**Save**”
4. 添加 **Telegram** 节点:
* 点击 Firecrawl 旁边的“**+**”
* 搜索“**Telegram**”
* 点击“**Send a text message**”将其添加到画布
5. 设置 Telegram 凭证:
* 点击 Telegram 节点打开其配置
* 在“Credential to connect with”下拉菜单中,点击“**Create New Credential**”
* 粘贴你从 BotFather 获取的 bot token
* 点击“**Save**”
 6. 配置 Telegram 消息:
* **Operation**: Send Message
* **Chat ID**: 输入你的 chat ID
* **Text**: 先保留一个“hello”消息
* 点击 **Execute step** 测试在接收来自 Firecrawl 的摘要时发送消息。
6. 配置 Telegram 消息:
* **Operation**: Send Message
* **Chat ID**: 输入你的 chat ID
* **Text**: 先保留一个“hello”消息
* 点击 **Execute step** 测试在接收来自 Firecrawl 的摘要时发送消息。
 * 现在基于 Firecrawl 的摘要结构,从 Firecrawl 节点输出中拖拽 `summary` 字段,将摘要添加到消息文本。
7. 测试工作流:
* 点击“**Execute Workflow**”
* 在 Telegram 中查看摘要消息
* 现在基于 Firecrawl 的摘要结构,从 Firecrawl 节点输出中拖拽 `summary` 字段,将摘要添加到消息文本。
7. 测试工作流:
* 点击“**Execute Workflow**”
* 在 Telegram 中查看摘要消息
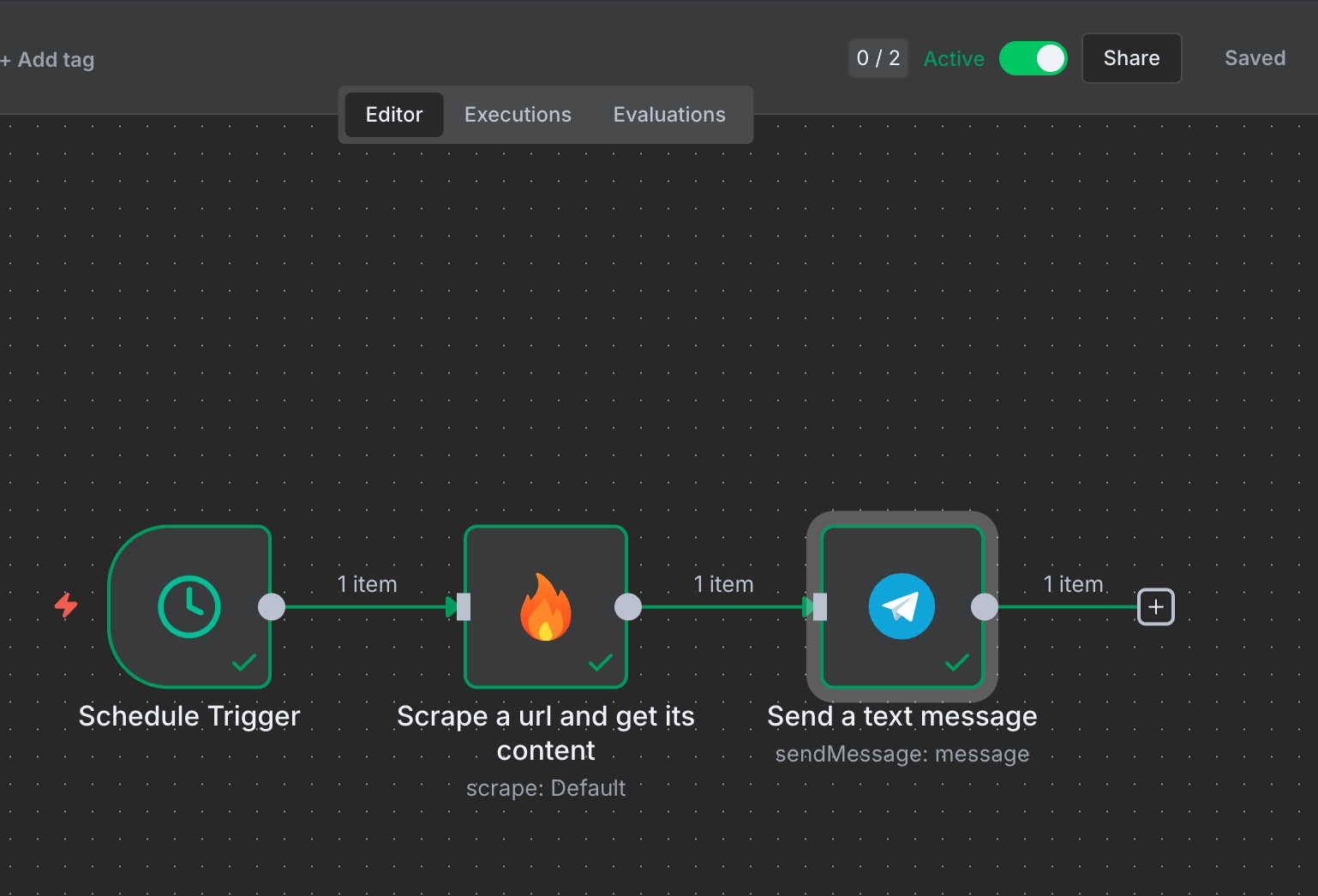 8. 通过切换“**Active**”开关来激活工作流
你的 Telegram 机器人现在会在每天上午 9 点向你发送 Firecrawl 产品更新的每日摘要。
8. 通过切换“**Active**”开关来激活工作流
你的 Telegram 机器人现在会在每天上午 9 点向你发送 Firecrawl 产品更新的每日摘要。
### 示例 2:AI 新闻搜索并发送到 Telegram
此工作流使用 Firecrawl 的 Search 操作查找 AI 新闻,并将格式化后的结果发送到 Telegram。
**与示例 1 的关键区别:**
* 使用 **Manual Trigger** 而非 Schedule (按需运行)
* 使用 **Search** 操作而非 Scrape
* 包含一个 **Code** 节点以格式化多条结果
**构建工作流:**
1. 创建一个新工作流并添加一个 **Manual Trigger** 节点
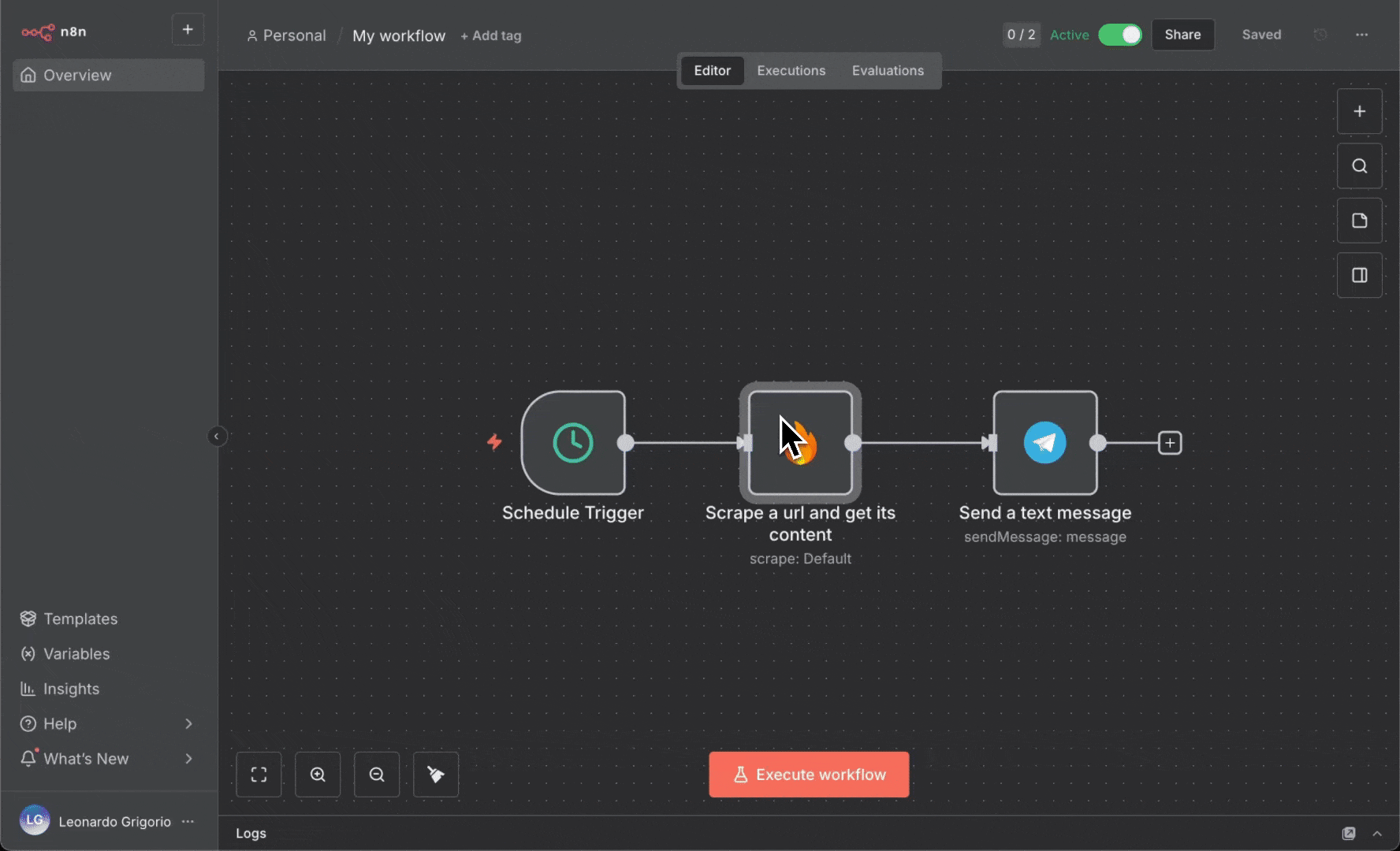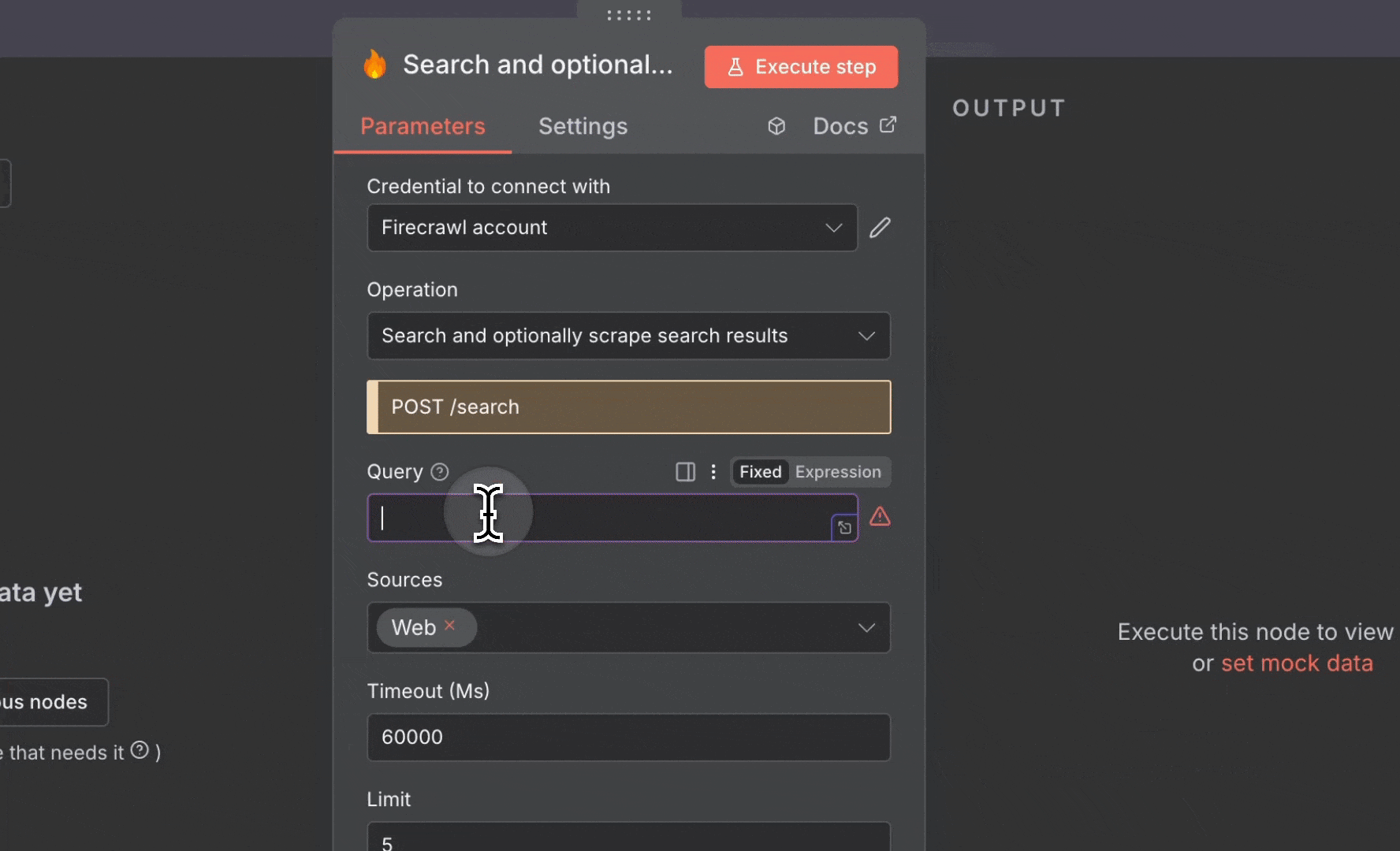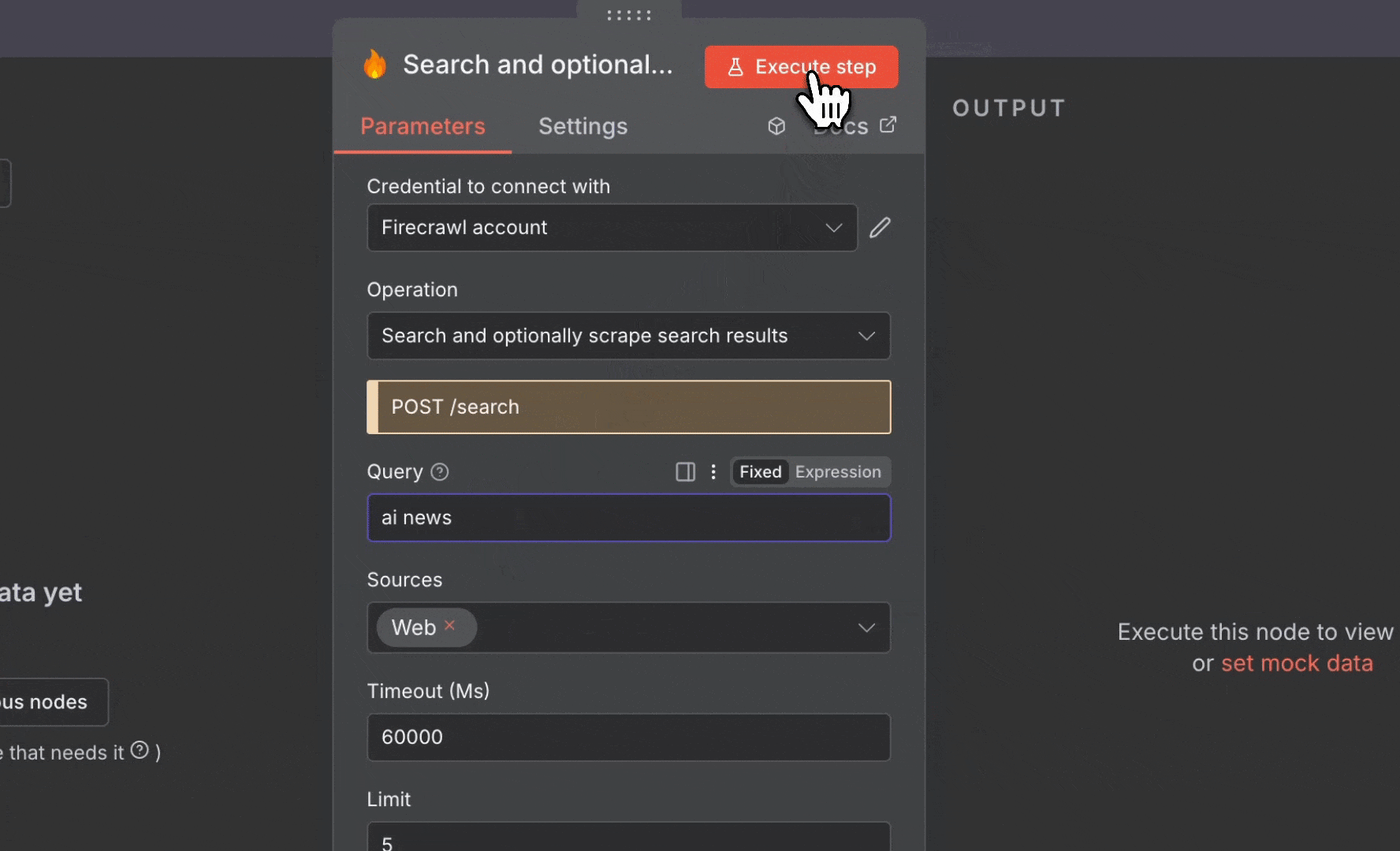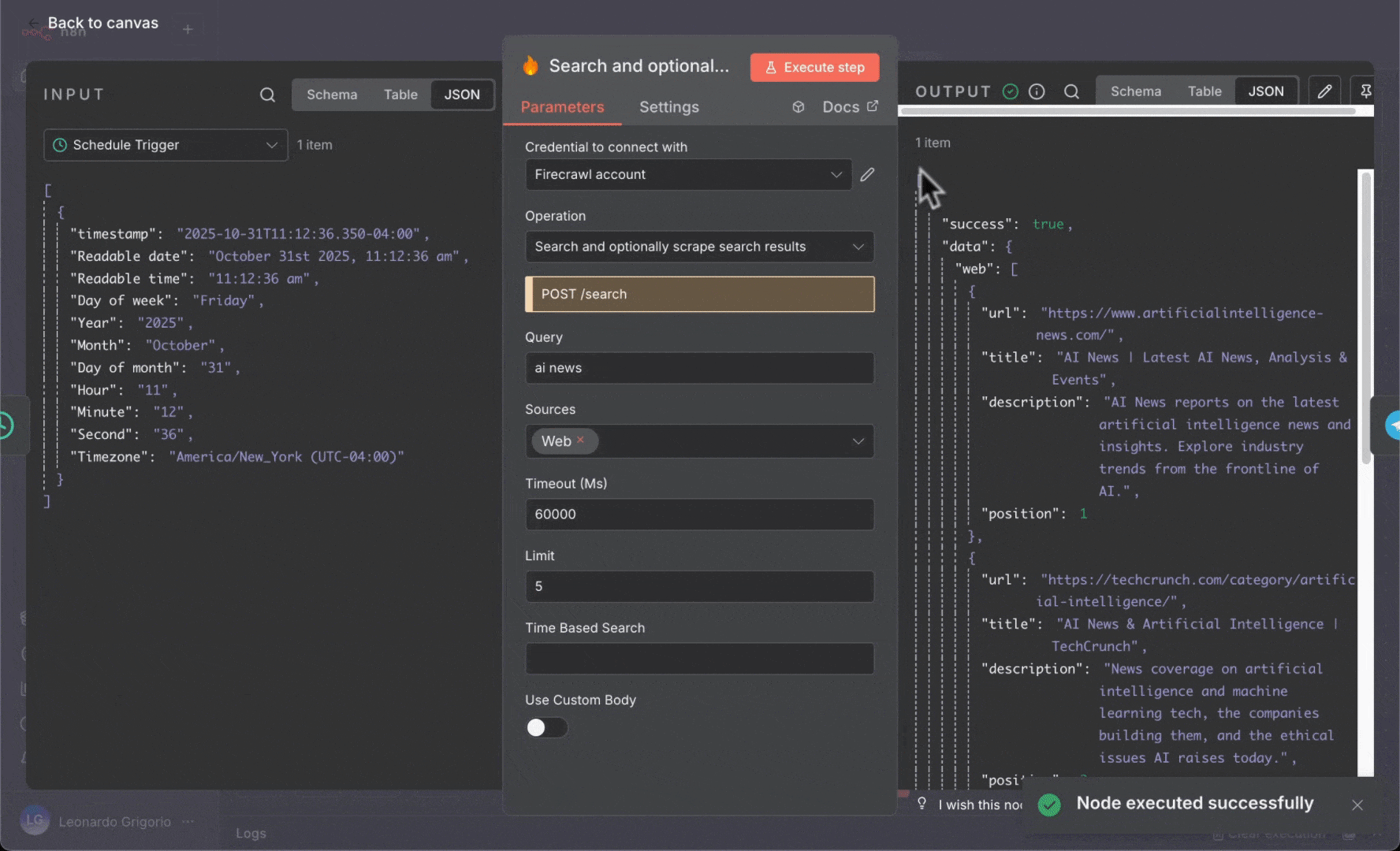
2. 添加 **Firecrawl** 节点并使用以下设置:
* **Resource**:Search,并可选地抓取搜索结果
* **Query**:`ai news`
* **Limit**:5
 3. 添加一个 **Code** 节点以格式化搜索结果:
* 选择 “Run Once for All Items”
* 粘贴以下代码:
```javascript theme={null}
const results = $input.all();
let message = "最新 AI 新闻:\n\n";
results.forEach((item) => {
const webData = item.json.data.web;
webData.forEach((article, index) => {
message += `${index + 1}. ${article.title}\n`;
message += `${article.description}\n`;
message += `${article.url}\n\n`;
});
});
return [{ json: { message } }];
```
3. 添加一个 **Code** 节点以格式化搜索结果:
* 选择 “Run Once for All Items”
* 粘贴以下代码:
```javascript theme={null}
const results = $input.all();
let message = "最新 AI 新闻:\n\n";
results.forEach((item) => {
const webData = item.json.data.web;
webData.forEach((article, index) => {
message += `${index + 1}. ${article.title}\n`;
message += `${article.description}\n`;
message += `${article.url}\n\n`;
});
});
return [{ json: { message } }];
```
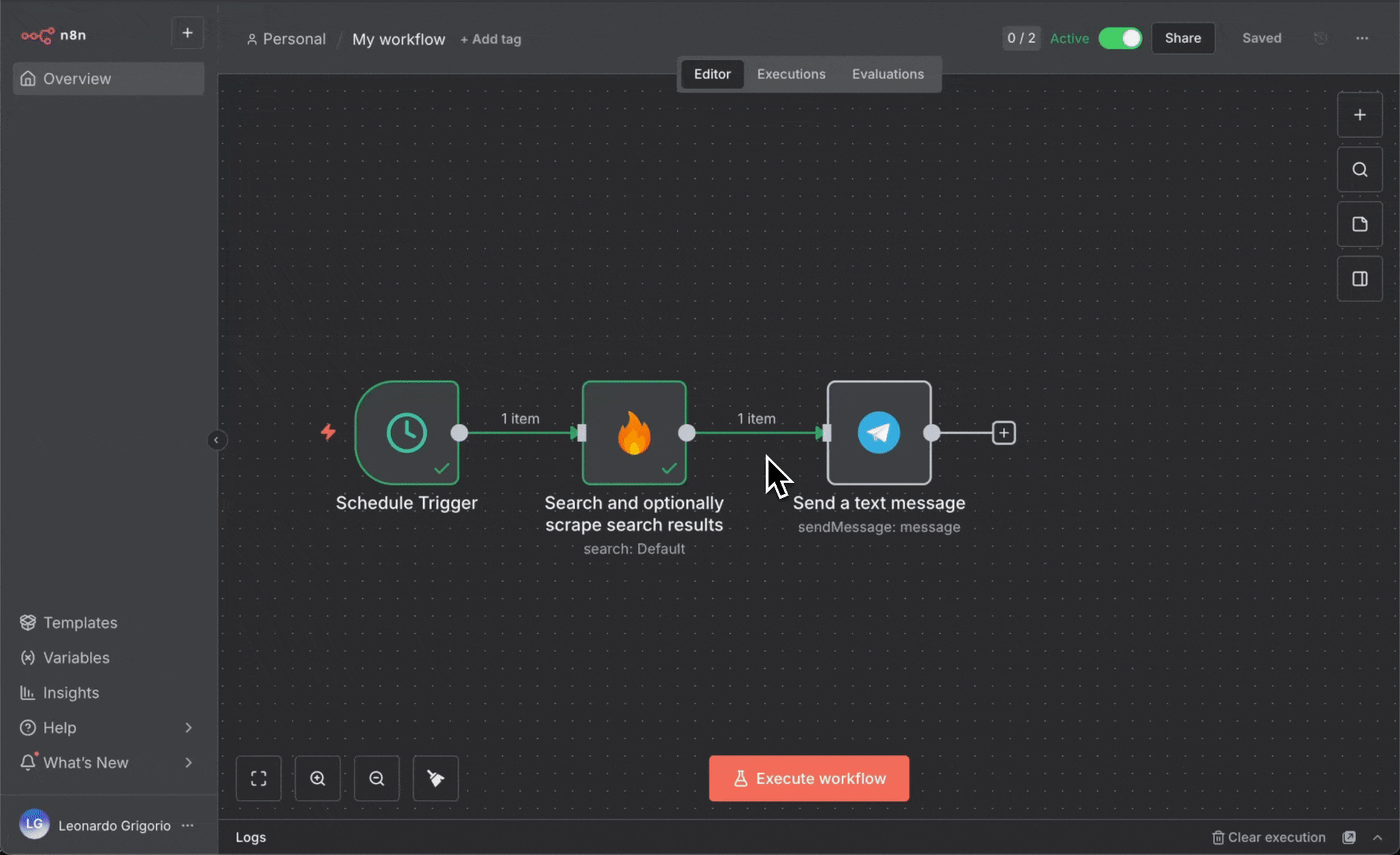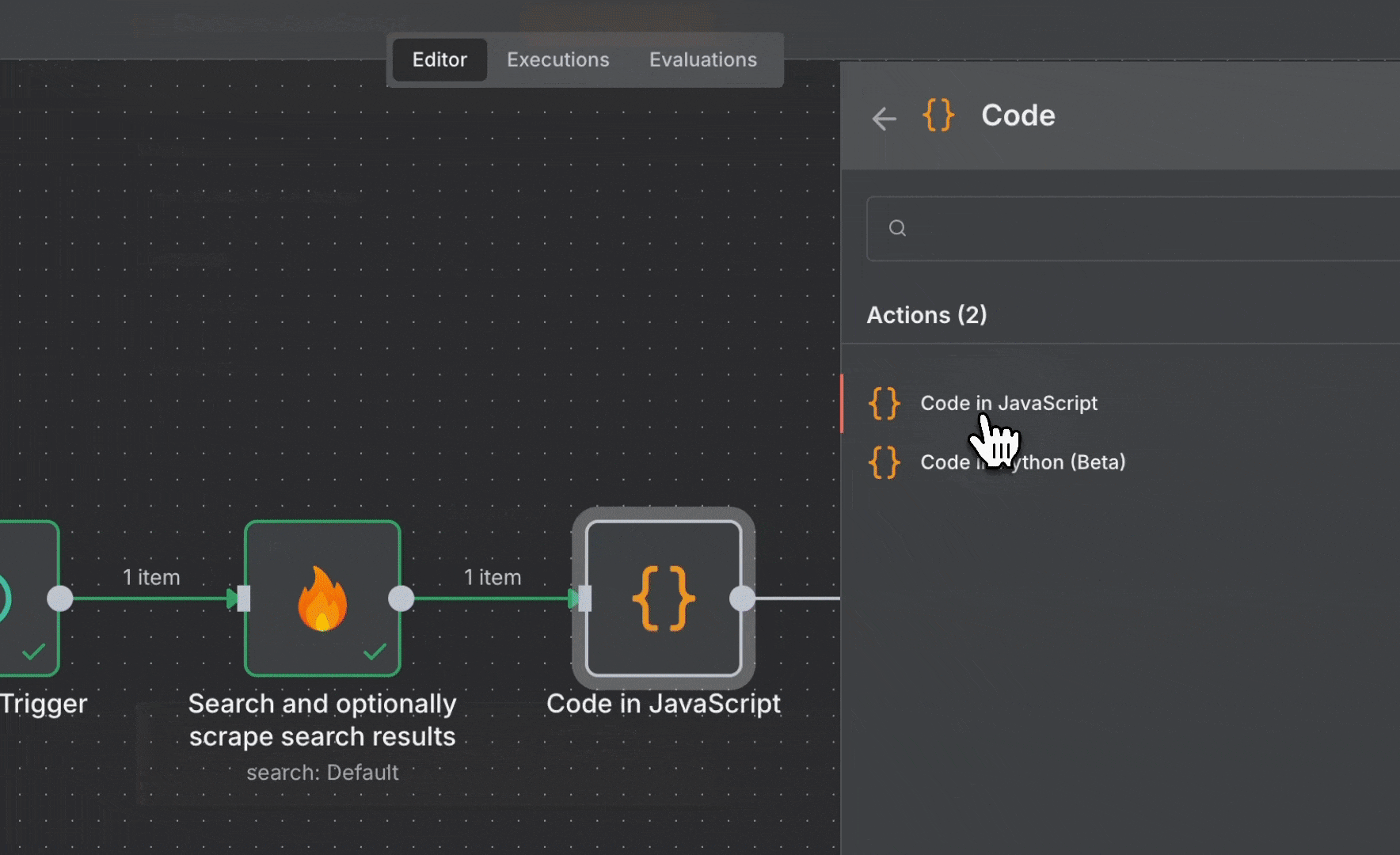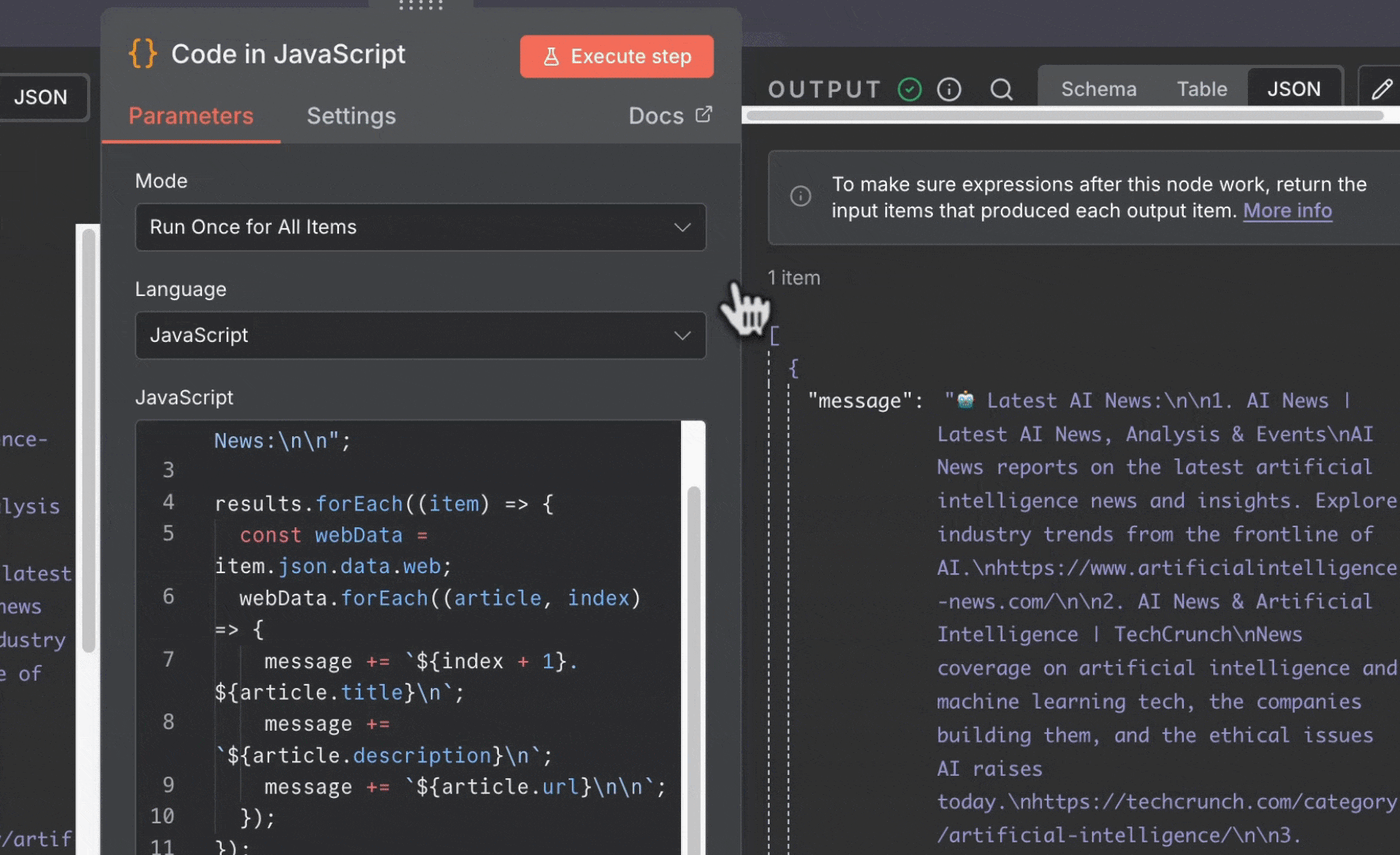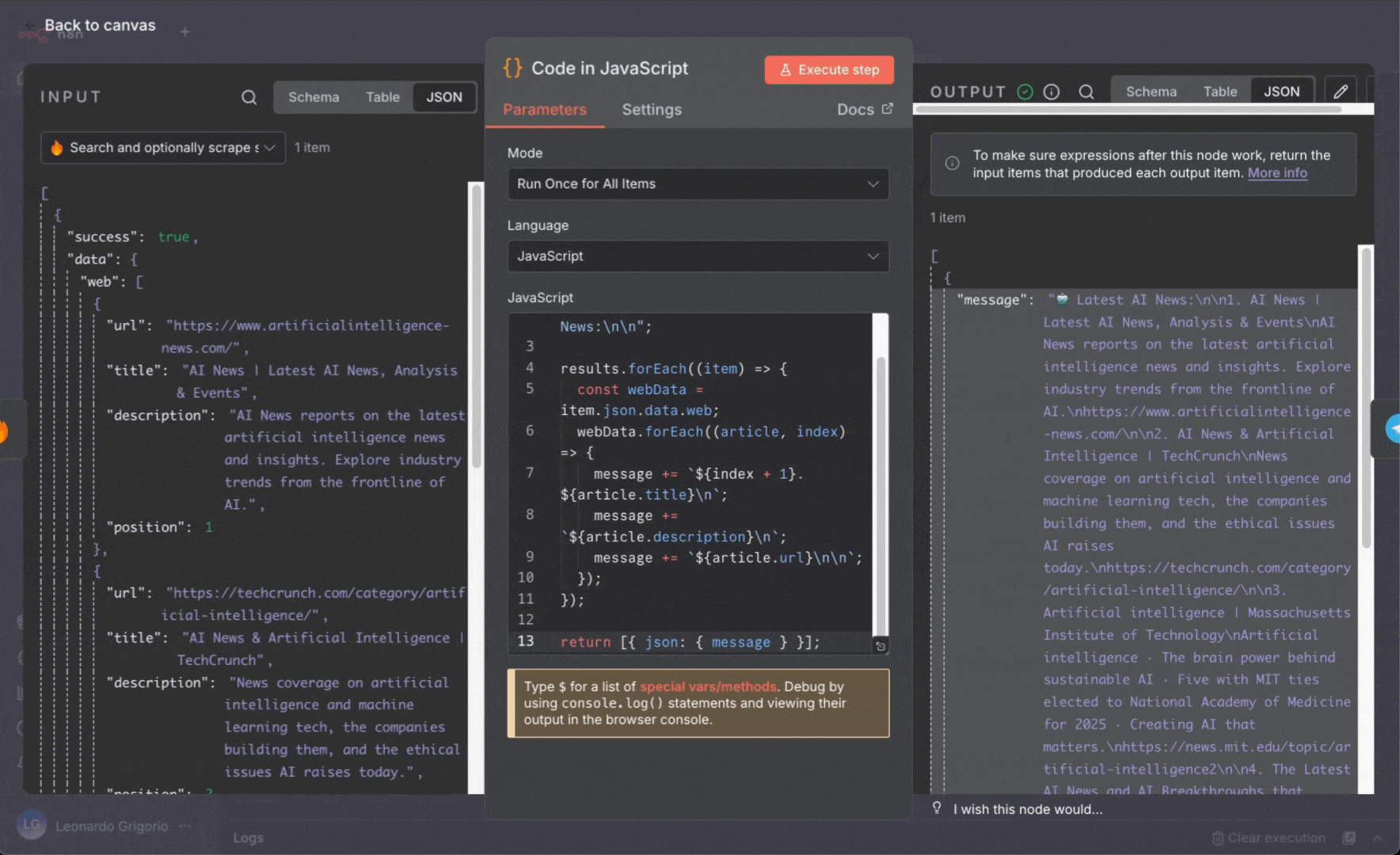 4. 更新 **Telegram** 节点 (使用已保存的凭据) :
* **Text**:从 Code 节点拖入 `message` 字段
4. 更新 **Telegram** 节点 (使用已保存的凭据) :
* **Text**:从 Code 节点拖入 `message` 字段
 将 Manual Trigger 替换为 Schedule Trigger,以按设定的时间间隔自动获取 AI 新闻更新。
将 Manual Trigger 替换为 Schedule Trigger,以按设定的时间间隔自动获取 AI 新闻更新。
### 示例 3:AI 驱动的新闻摘要
此工作流在示例 2 的基础上引入 AI,使用 OpenAI 在发送到 Telegram 之前智能生成最新 AI 新闻的摘要。
**与示例 2 的关键变化:**
* 添加 **OpenAI 凭证** 配置
* 在 Code 和 Telegram 之间添加 **AI Agent** 节点
* AI Agent 智能分析并总结所有新闻文章
* Telegram 接收的是 AI 生成的摘要,而非原始新闻列表
**修改工作流:**
1. **获取你的 OpenAI API 密钥**:
* 前往 [platform.openai.com/api-keys](https://platform.openai.com/api-keys)
* 登录或创建账号
* 点击“**Create new secret key**”
* 为其命名 (例如,“n8n Integration”)
* 立即复制 API 密钥 (之后将无法再次查看)
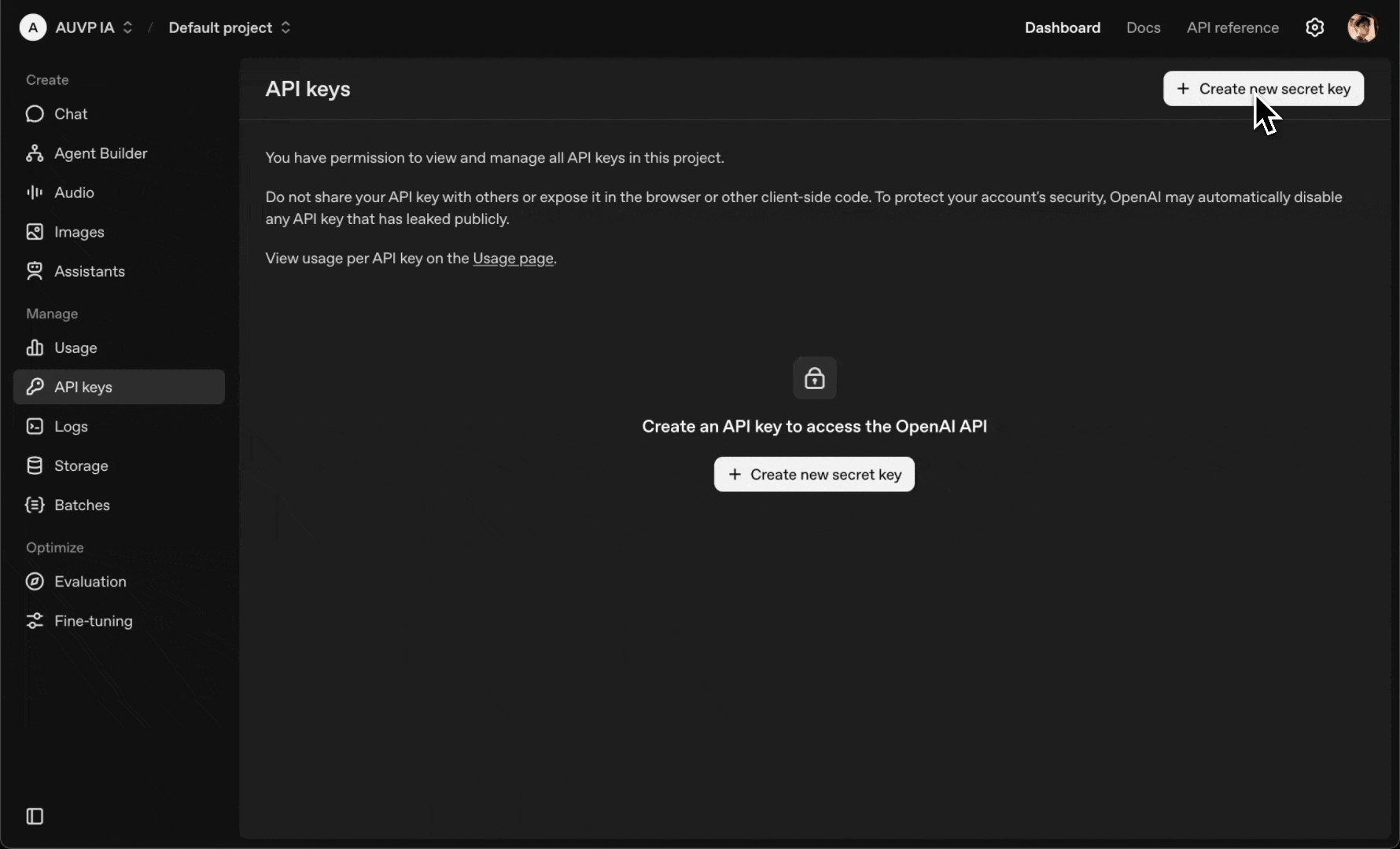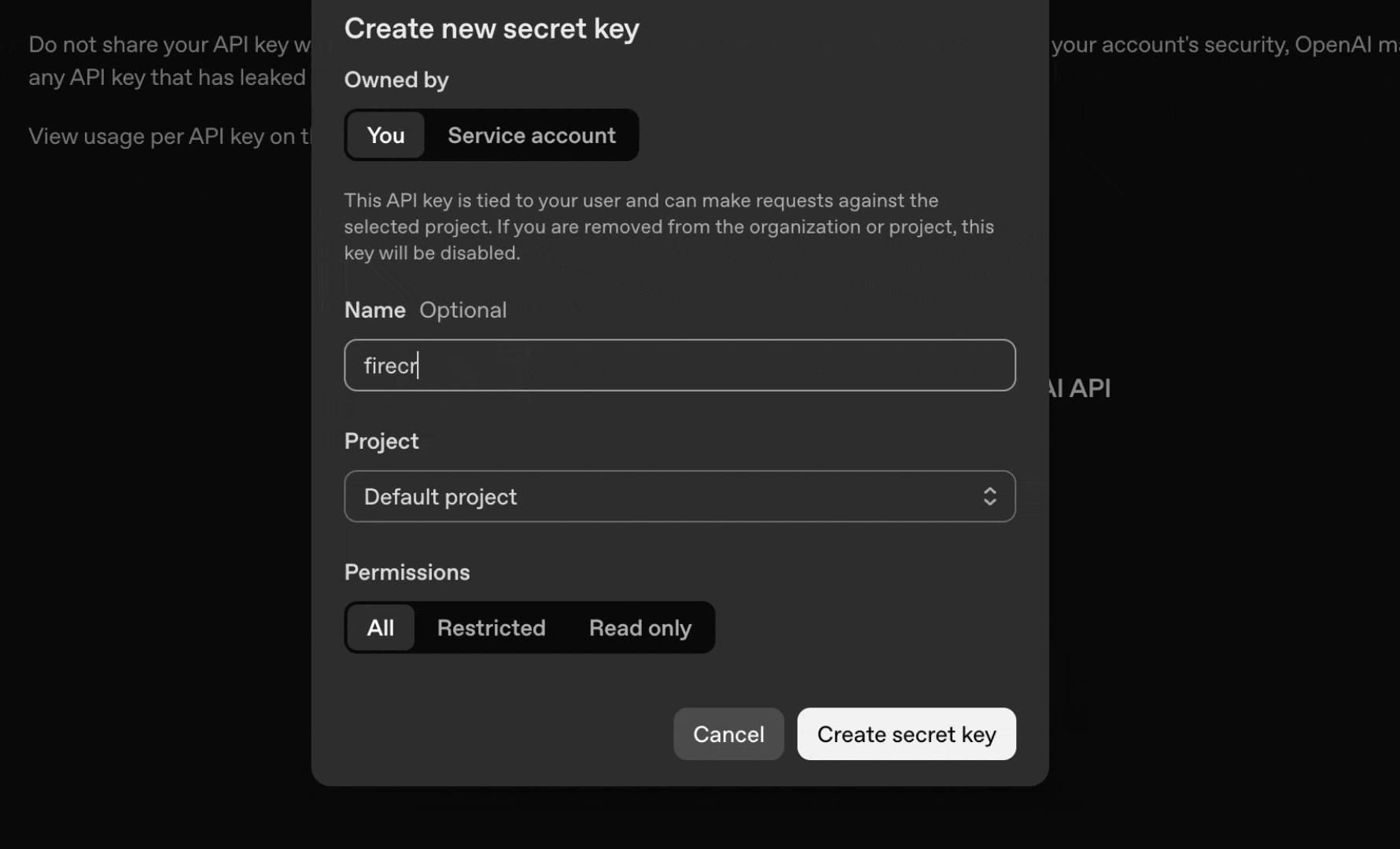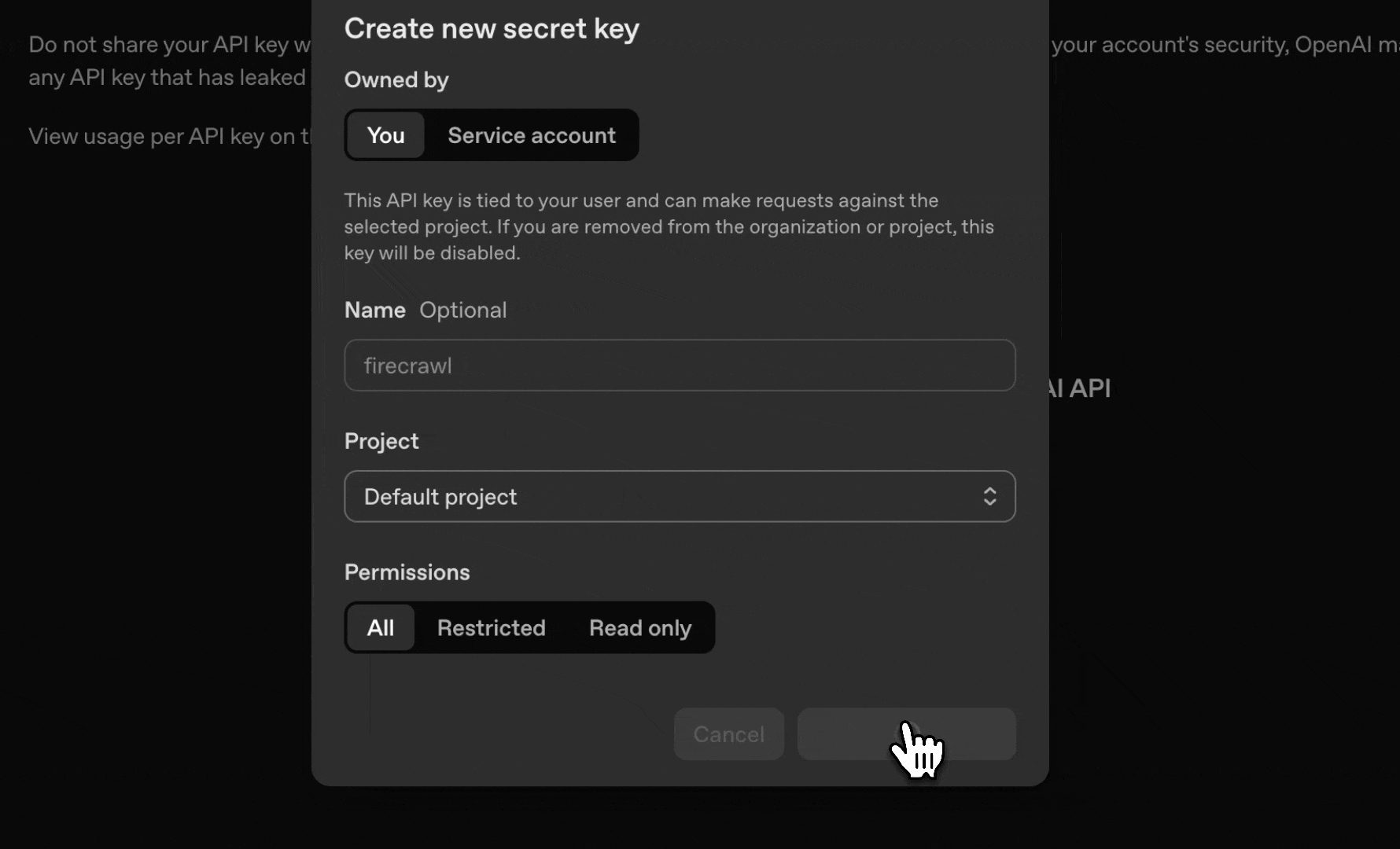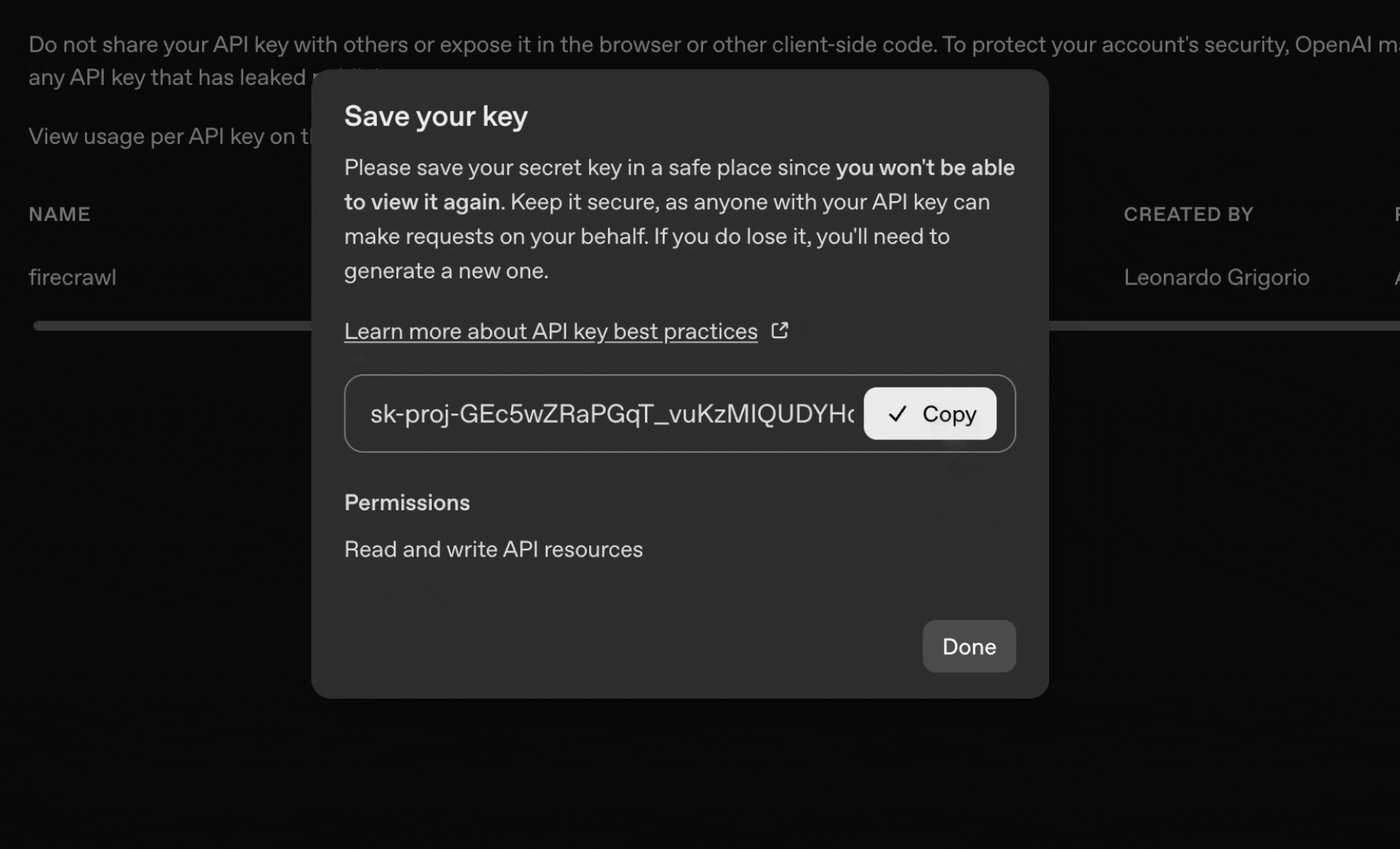 2. **添加并连接 AI Agent 节点**:
* 在 Code 节点后点击“**+**”
* 搜索“**Basic LLM Chain**”或“**AI Agent**”
* 将 Code 节点中的 `message` 字段拖到 AI Agent 的输入提示字段
* 选择 **OpenAI** 作为 LLM 提供方
2. **添加并连接 AI Agent 节点**:
* 在 Code 节点后点击“**+**”
* 搜索“**Basic LLM Chain**”或“**AI Agent**”
* 将 Code 节点中的 `message` 字段拖到 AI Agent 的输入提示字段
* 选择 **OpenAI** 作为 LLM 提供方
 3. **添加你的 OpenAI 凭证**:
* 点击“**Create New Credential**”以添加 OpenAI 凭证
* 粘贴你的 OpenAI API 密钥
* 选择模型:**gpt-5-mini** (更具性价比) 或 **gpt-5** (更强大)
* 点击“**Save**”
3. **添加你的 OpenAI 凭证**:
* 点击“**Create New Credential**”以添加 OpenAI 凭证
* 粘贴你的 OpenAI API 密钥
* 选择模型:**gpt-5-mini** (更具性价比) 或 **gpt-5** (更强大)
* 点击“**Save**”
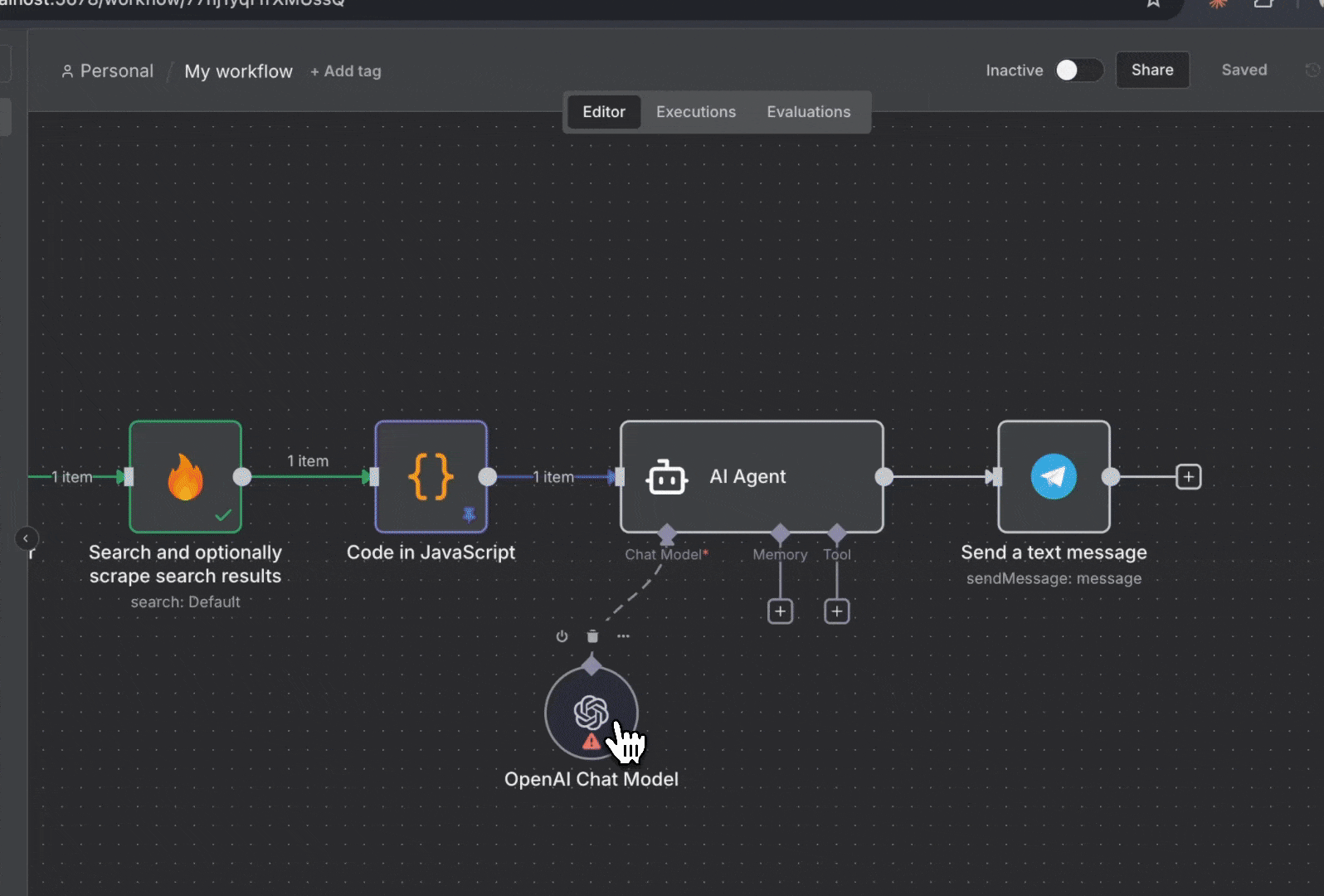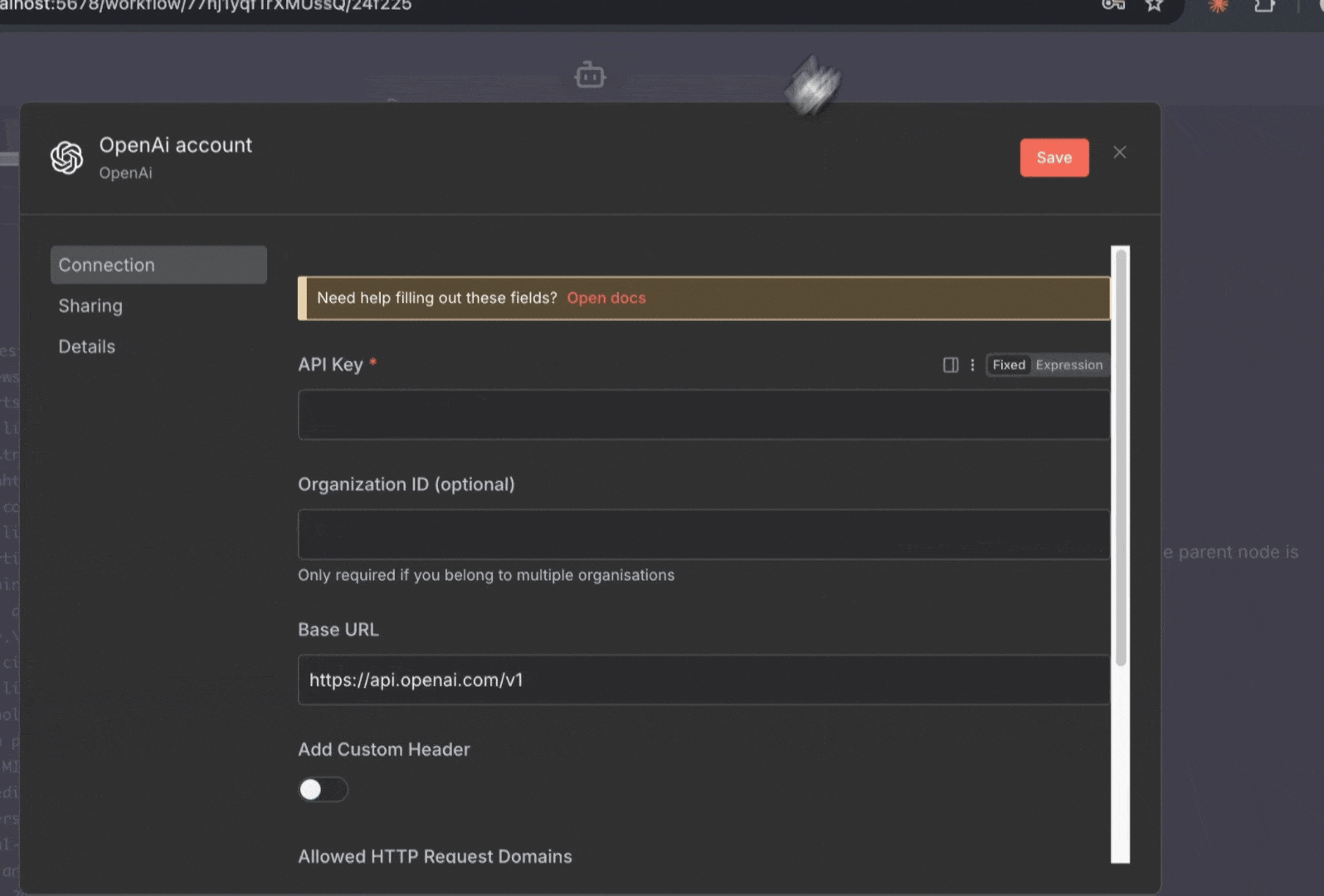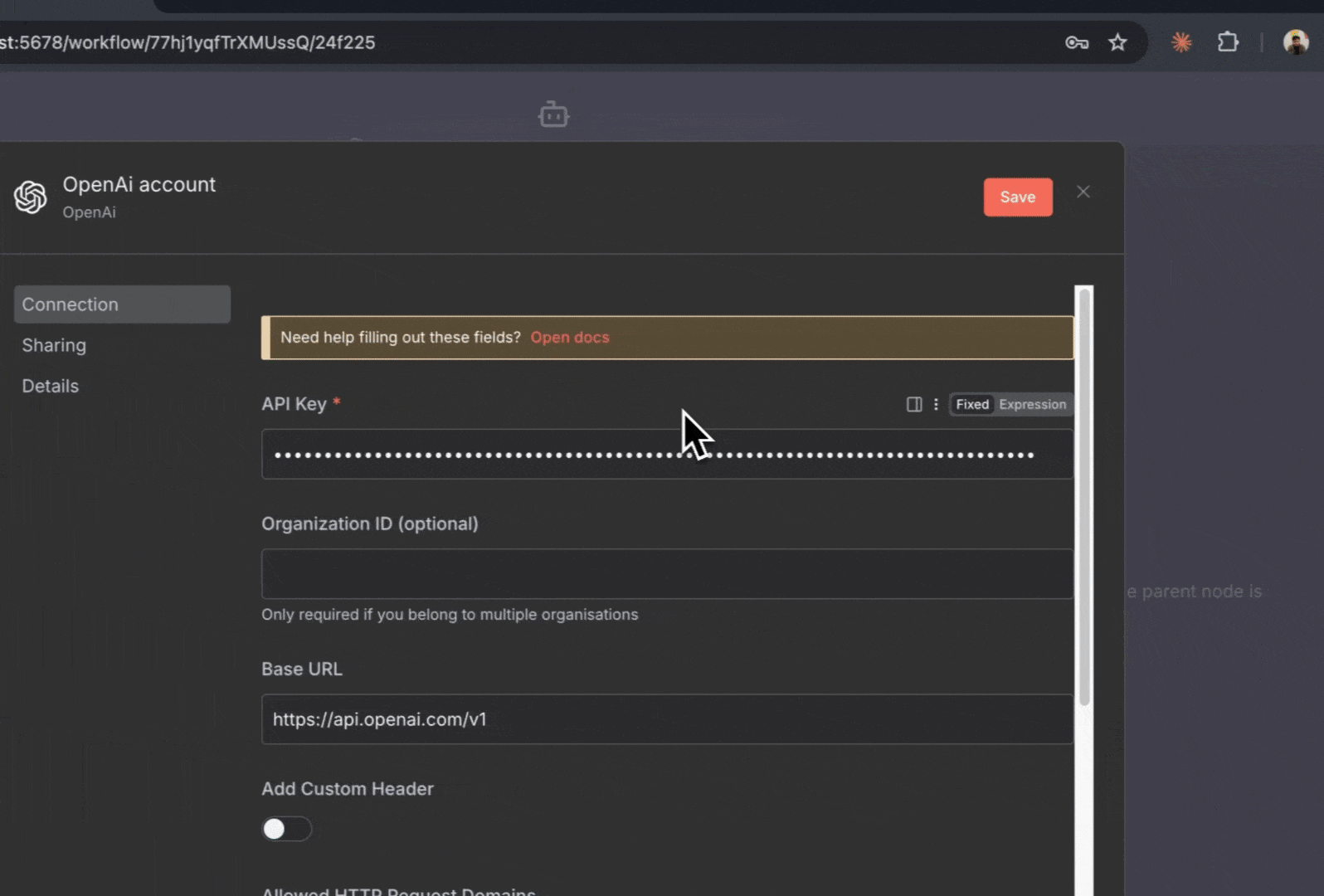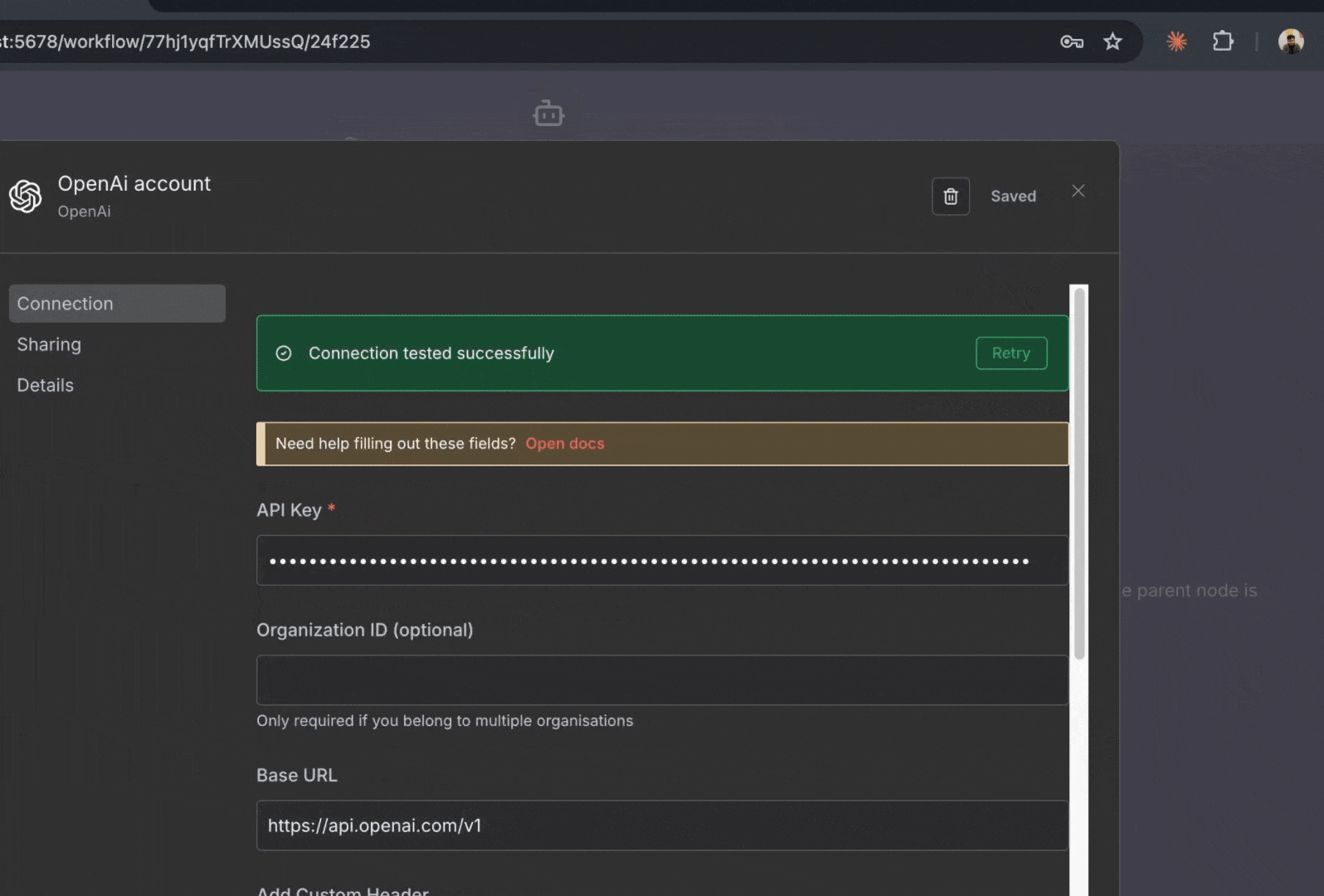 4. **向 AI Agent 添加系统提示**:
* 在 AI Agent 节点中,添加以下系统提示:
```
你是一名 AI 新闻分析师。请分析所提供的 AI 新闻文章,并生成简洁、
有见地的摘要,重点突出最重要的进展和趋势。
将相关主题归类整理,并说明这些进展的重要性及其背景。
摘要应保持对话式风格且引人入胜,控制在 3-4 段左右。
```
4. **向 AI Agent 添加系统提示**:
* 在 AI Agent 节点中,添加以下系统提示:
```
你是一名 AI 新闻分析师。请分析所提供的 AI 新闻文章,并生成简洁、
有见地的摘要,重点突出最重要的进展和趋势。
将相关主题归类整理,并说明这些进展的重要性及其背景。
摘要应保持对话式风格且引人入胜,控制在 3-4 段左右。
```
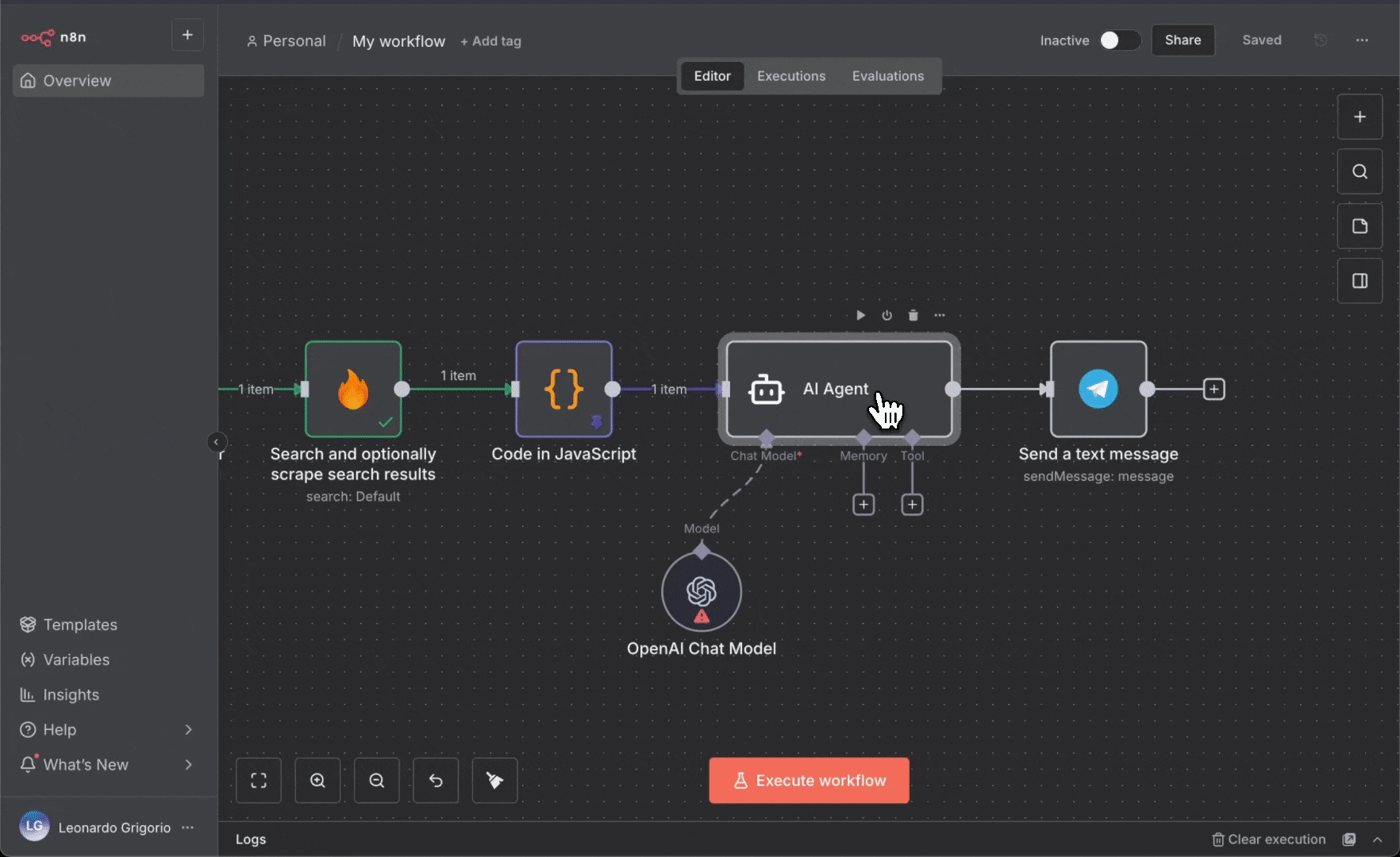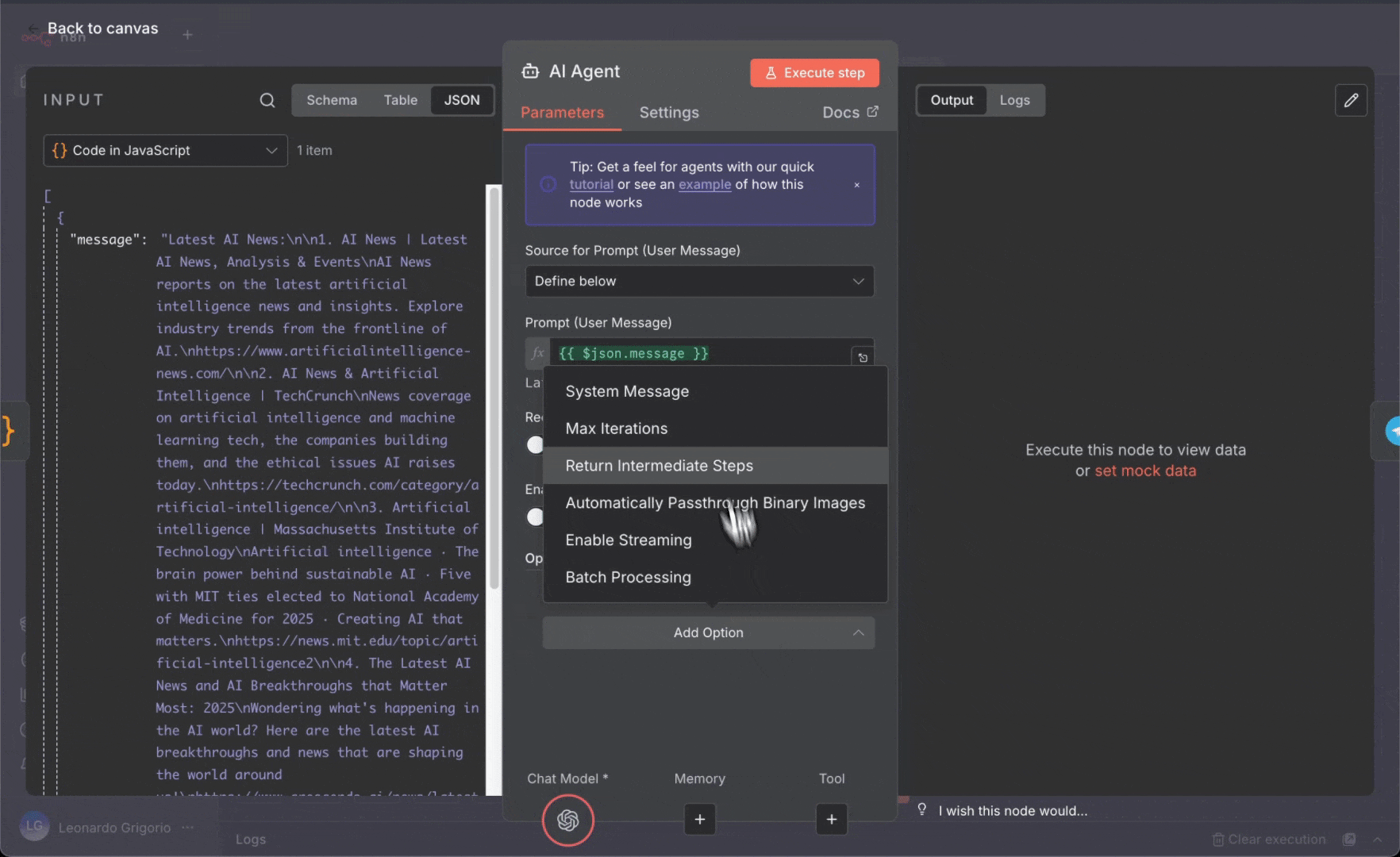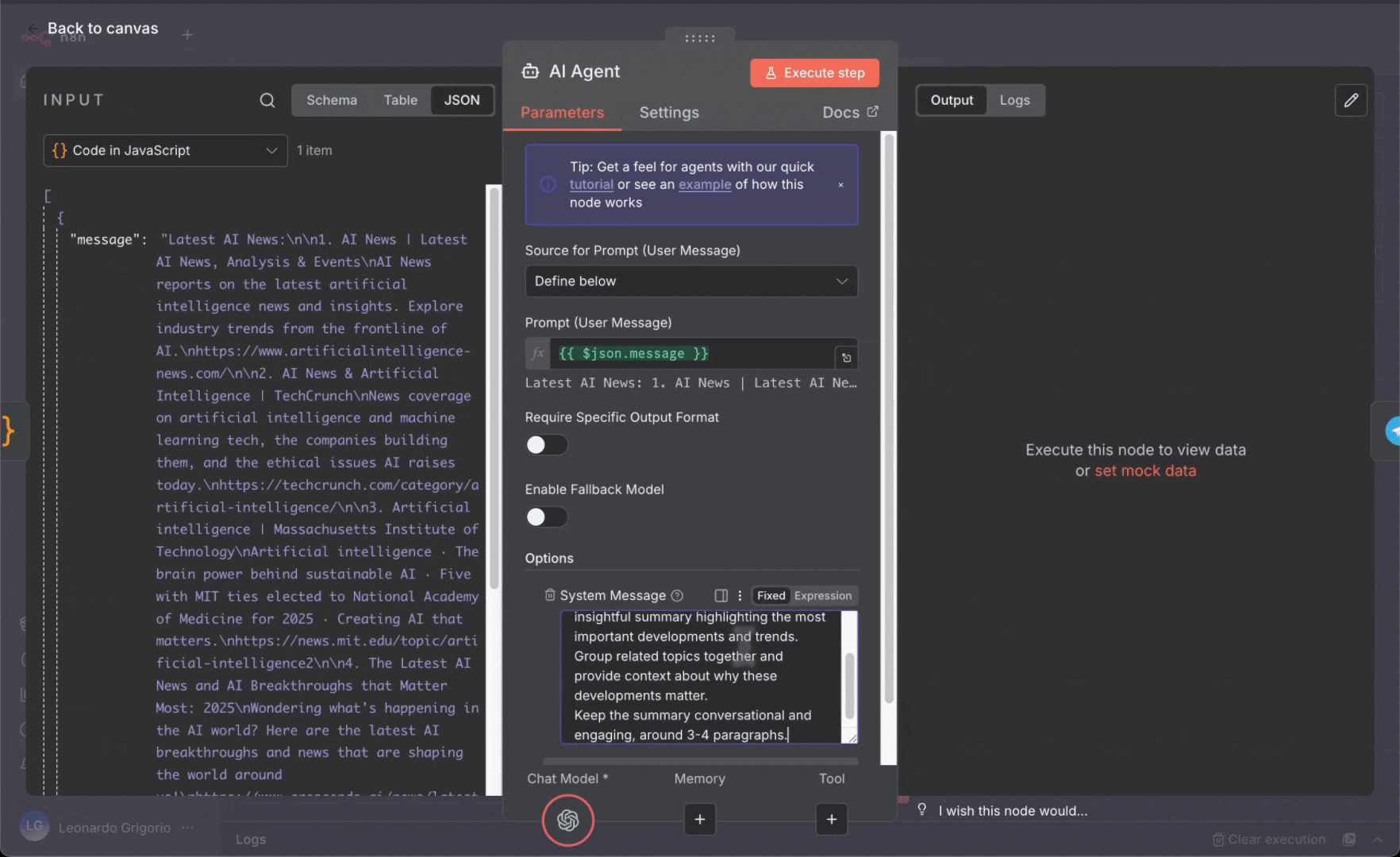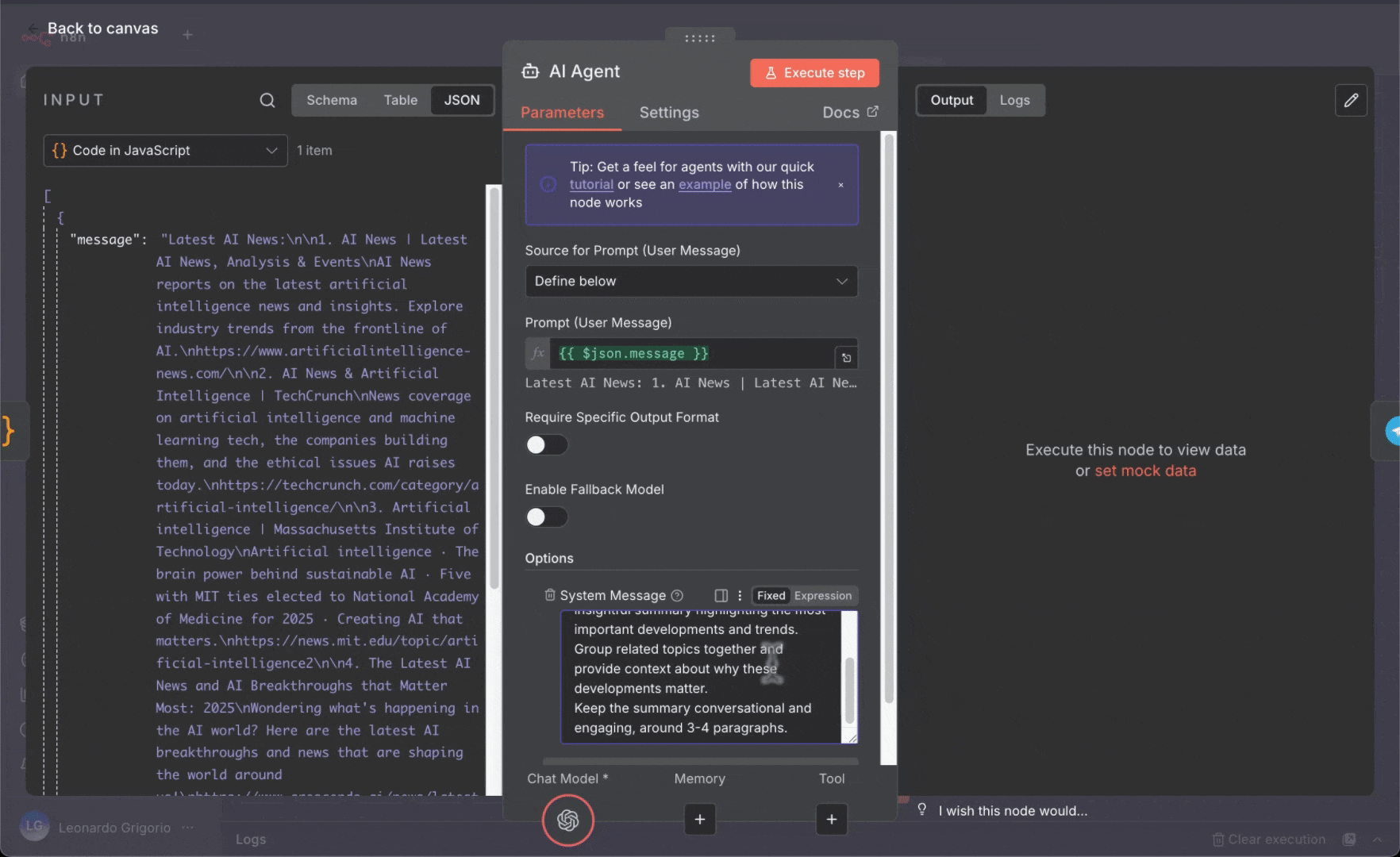 5. **更新 Telegram 节点并测试**:
* 更新 Telegram 节点:
* **Text**:拖入 AI Agent 的输出 (生成的摘要)
* 移除与 Code 节点消息的旧映射
* 点击“**Execute Workflow**”进行测试
* AI 将分析所有新闻文章并生成摘要
* 在 Telegram 中查看 AI 生成的摘要
5. **更新 Telegram 节点并测试**:
* 更新 Telegram 节点:
* **Text**:拖入 AI Agent 的输出 (生成的摘要)
* 移除与 Code 节点消息的旧映射
* 点击“**Execute Workflow**”进行测试
* AI 将分析所有新闻文章并生成摘要
* 在 Telegram 中查看 AI 生成的摘要
 AI Agent 会接收所有已格式化的新闻文章并生成智能摘要,帮助你一目了然地把握趋势与重要进展。
AI Agent 会接收所有已格式化的新闻文章并生成智能摘要,帮助你一目了然地把握趋势与重要进展。
## 了解 Firecrawl 操作
现在你已经搭建了一些工作流,我们来看看 n8n 中可用的各类 Firecrawl 操作。每种操作都面向特定的网页爬取场景而设计。
### 抓取一个 URL 并获取其内容
从单个网页提取内容,并以多种 formats 返回。
**功能:**
* 抓取单个 URL
* 返回干净的 markdown、HTML 或由 AI 生成的摘要
* 可截取页面截图并提取链接
**最适合:**
* 文章提取
* 产品页面监控
* 博文抓取
* 生成页面摘要
**示例用例:** 每日博客摘要 (如上方示例 1)
### 使用持久化 profile 执行 Scrape + 交互
对于先执行 Scrape 再执行交互的工作流,请在 **Scrape** 步骤中设置持久化 `profile`。交互步骤只需要抓取响应中的 `scrapeId`,再加上 prompt 或代码即可。不要在交互请求体中添加 `profile`;交互会继承该抓取任务的 profile。
要保存 cookies、localStorage 和其他浏览器状态,请在工作流完成后停止交互会话。如果你只需要在后续某次工作流运行中读取现有 profile,请在 Scrape 步骤中将 `saveChanges` 设为 `false`。
如果你安装的 Firecrawl n8n 节点版本没有在 Scrape 操作中提供 profile 设置,请更新到最新版本的 Firecrawl n8n 节点。如果你的 n8n 版本支持为该节点自定义请求或请求体选项,也可以在那里传入相同的 `profile` 对象:
```json theme={null}
{
"profile": {
"name": "my-profile",
"saveChanges": true
}
}
```
### 搜索,并可选抓取搜索结果
执行网页搜索,可选抓取内容并返回结果。
**功能:**
* 搜索网页、新闻或图片
* 返回标题、描述和 URL
* 可选抓取结果的完整内容
**适用于:**
* 研究自动化
* 新闻监测
* 趋势洞察
* 寻找相关内容
**示例用例:** AI 新闻聚合 (如上面的示例 2)
### 爬取网站
递归发现并抓取站点中的多个页面。
**功能:**
* 自动跟踪链接
* 一次操作抓取多个页面
* 可按模式筛选 URL
**适用场景:**
* 完整文档抽取
* 网站归档
* 多页面数据采集
### 网站映射与 URL 获取
在不抓取页面内容的情况下,返回站点上发现的所有 URL。
**功能:**
* 发现站点内所有链接
* 返回精洁的 URL 列表
* 速度快、开销小
**适用场景:**
* URL 发现
* 生成网站地图
* 规划大规模爬取
使用 AI 按自定义提示或架构提取结构化信息。
**功能:**
* AI 驱动的数据抽取
* 以你指定的格式返回数据
* 支持跨多个页面
**适用于:**
* 自定义数据抽取
* 构建数据库
* 采集结构化信息
### 批量抓取
高效并行抓取多个 URL。
**功能:**
* 同时处理多个 URL
* 比循环更高效
* 统一返回所有结果
**最适用于:**
* 处理 URL 列表
* 批量数据采集
* 大规模抓取项目
### Agent
使用 AI Agent 根据自然语言提示自动浏览网站并提取数据。
**功能:**
* 接收描述所需数据的 prompt
* AI Agent 自动在网站中导航并提取信息
* 提供 **Sync** 模式 (等待结果) 和 **Async** 模式 (立即返回任务 ID)
* 使用 Async 模式时,可通过 **Get Agent Status** 轮询获取结果
**最适合用于:**
* 基于 prompt 引导的复杂、多页面数据采集
* 在不了解页面具体结构时提取信息
* 需要浏览多个页面的研究/调研任务
**Sync vs. Async:**
* **Agent (Sync)** 在一步中启动任务并等待结果——对大多数用例来说是最简单的方式。**Max Wait Time** 参数控制节点在超时前轮询的时长 (默认值:300 秒,最大值:600 秒) 。如果代理任务耗时超过该时长,节点会返回超时状态,即使该任务在 Firecrawl 侧仍可能完成。对于可能超过 10 分钟的任务,请改用 async 模式。
* **Agent (Async)** 会立即返回一个任务 ID。再添加一个 Firecrawl 节点并使用 **Get Agent Status** 操作,在任务完成后获取结果。
有关 Agent 功能的详细信息,请参阅 [Agent 文档](/zh/features/agent)。
### Browser Sandbox
提供一个可通过代码控制的持久浏览器会话,让你能够在单个会话中完成多步骤浏览器自动化。
**操作:**
* **创建浏览器会话** — 启动新的浏览器会话,并返回 `sessionId`
* **执行浏览器代码** — 在会话中运行 JavaScript、Python 或 bash 代码 (使用创建步骤返回的 `sessionId`)
* **列出浏览器会话** — 列出活跃或已销毁的会话
* **删除浏览器会话** — 在使用完成后销毁会话
**最适合:**
* 需要在多个页面之间保持状态的多步骤浏览器工作流
* 无法预先确定步骤数量的动态页面导航
* 使用持久浏览器配置文件,在多次运行之间保留 cookies 和 localStorage 的工作流
在 n8n 中,在 Firecrawl 节点上选择 **Browser** 资源即可访问这些操作。将创建步骤返回的 `sessionId` 传入后续每个执行或删除步骤。使用 n8n 的 **Loop Over Items** 节点遍历动态页面列表,并在同一会话中为每个页面调用 Execute。
有关 Browser Sandbox 功能的详细信息,请参见 [Browser Sandbox documentation](/zh/features/browser-sandbox)。
## 工作流模板与示例
无需从零开始,您可以直接使用预置模板。n8n 社区已创建了大量可复制并自定义的 Firecrawl 工作流。
### 精选模板
使用 Firecrawl 与 n8n 构建具备网页访问能力的 AI 聊天机器人
开箱即用的模板,覆盖获客、价格监控等场景
将页面抓取为嵌入并存储到 Supabase pgvector 中,用于 RAG
抓取公司网站并提取结构化业务信号
将页面抓取为嵌入并存储到 Pinecone 中,用于 RAG
浏览数百个基于 Firecrawl 的工作流
查看官方集成文档
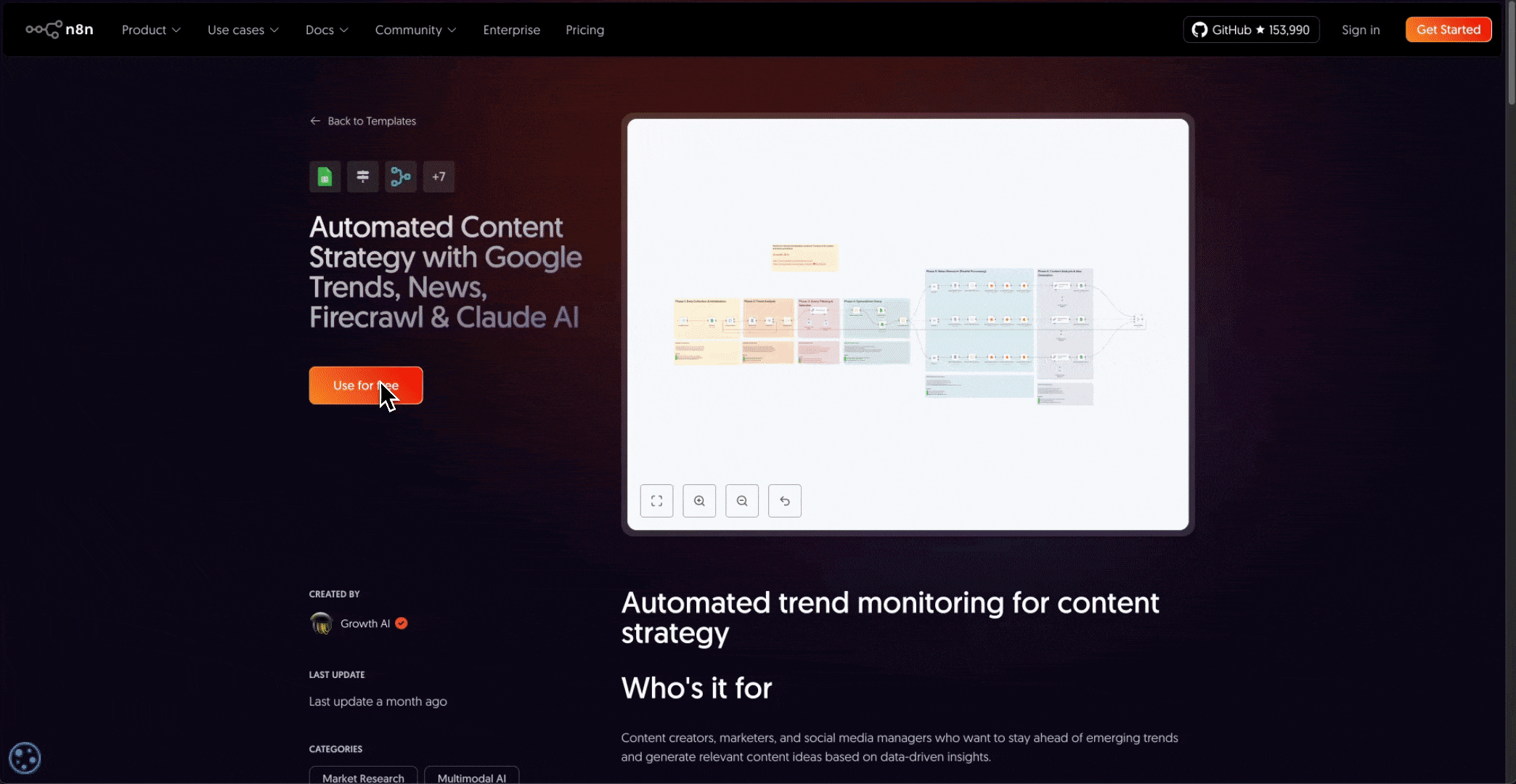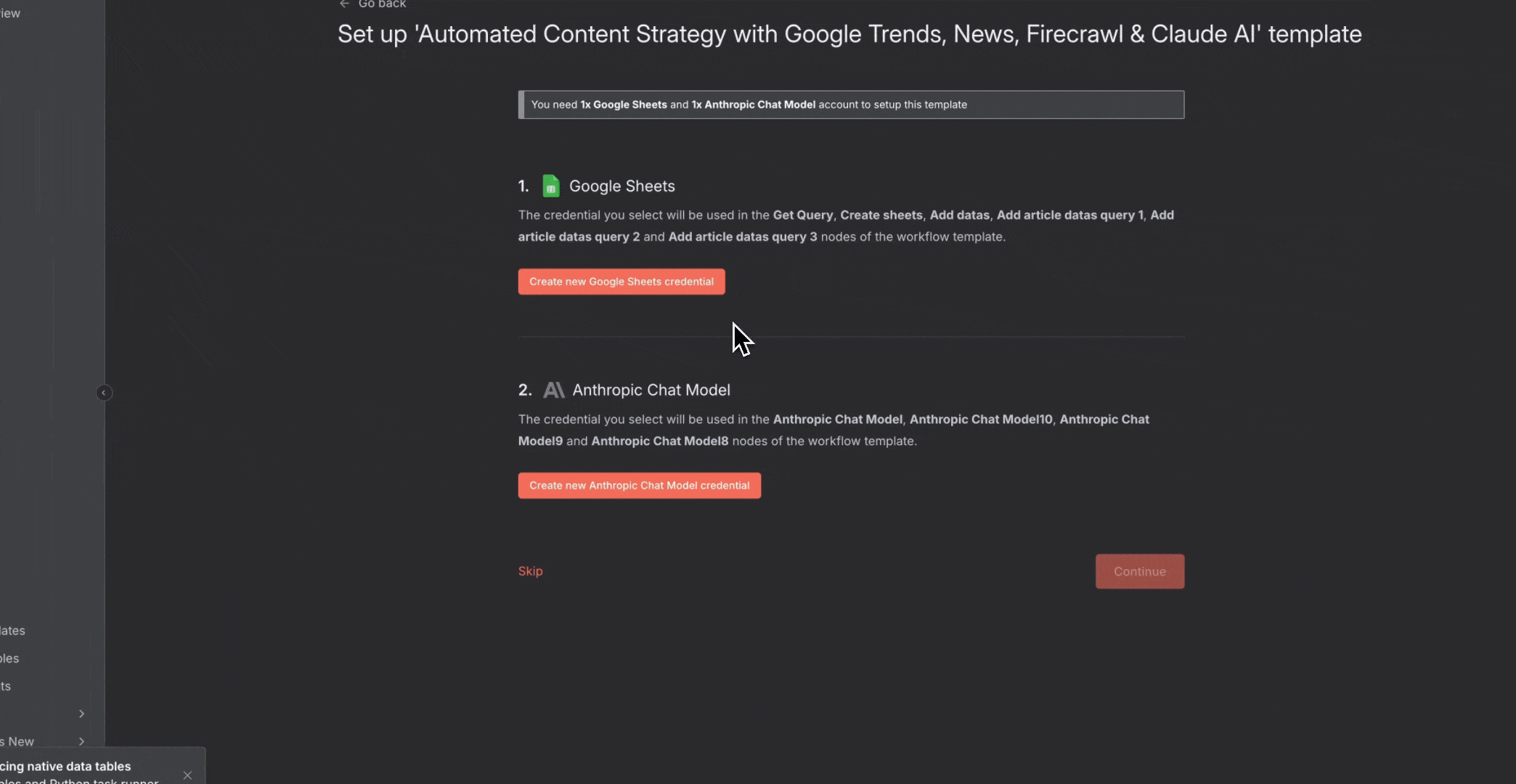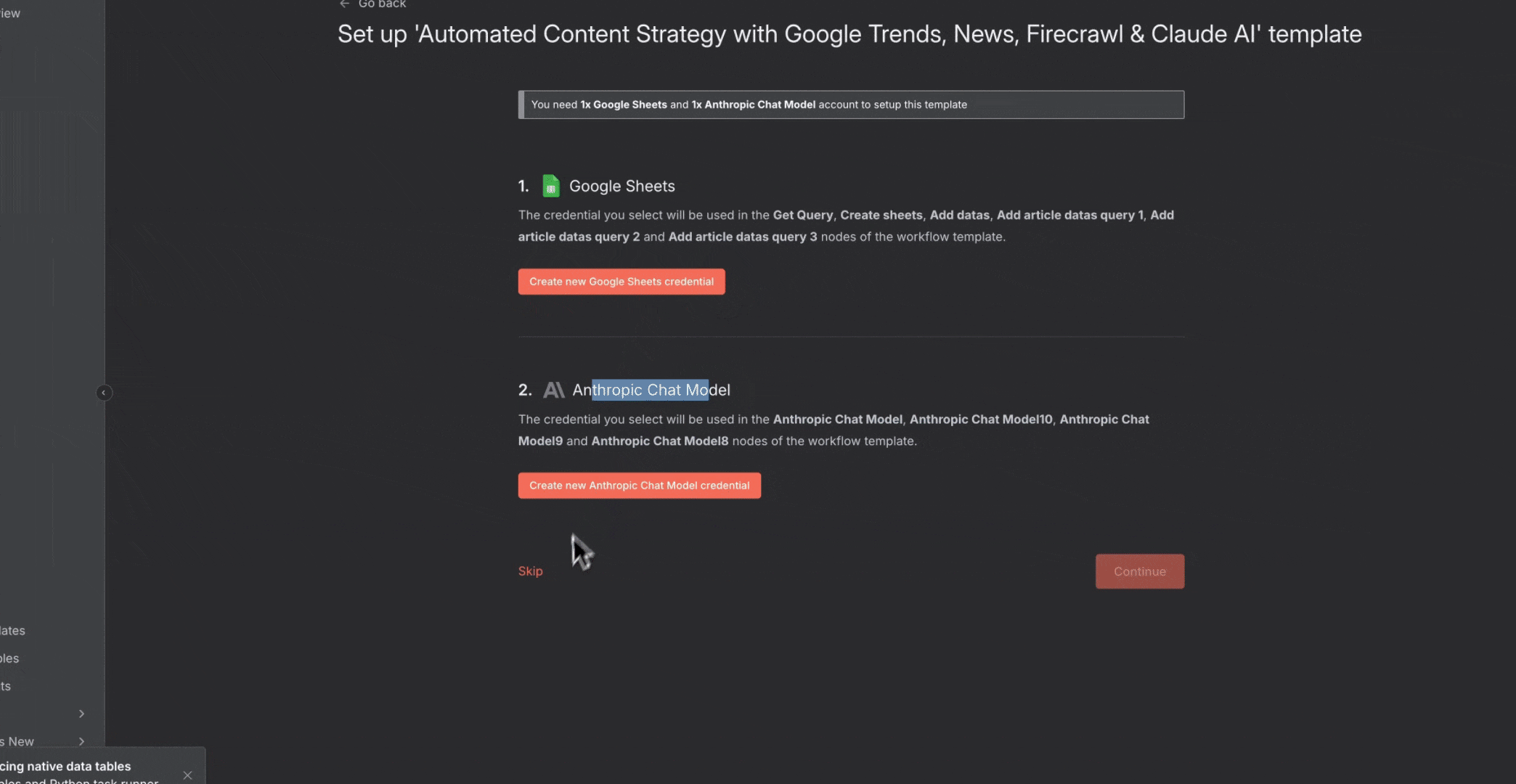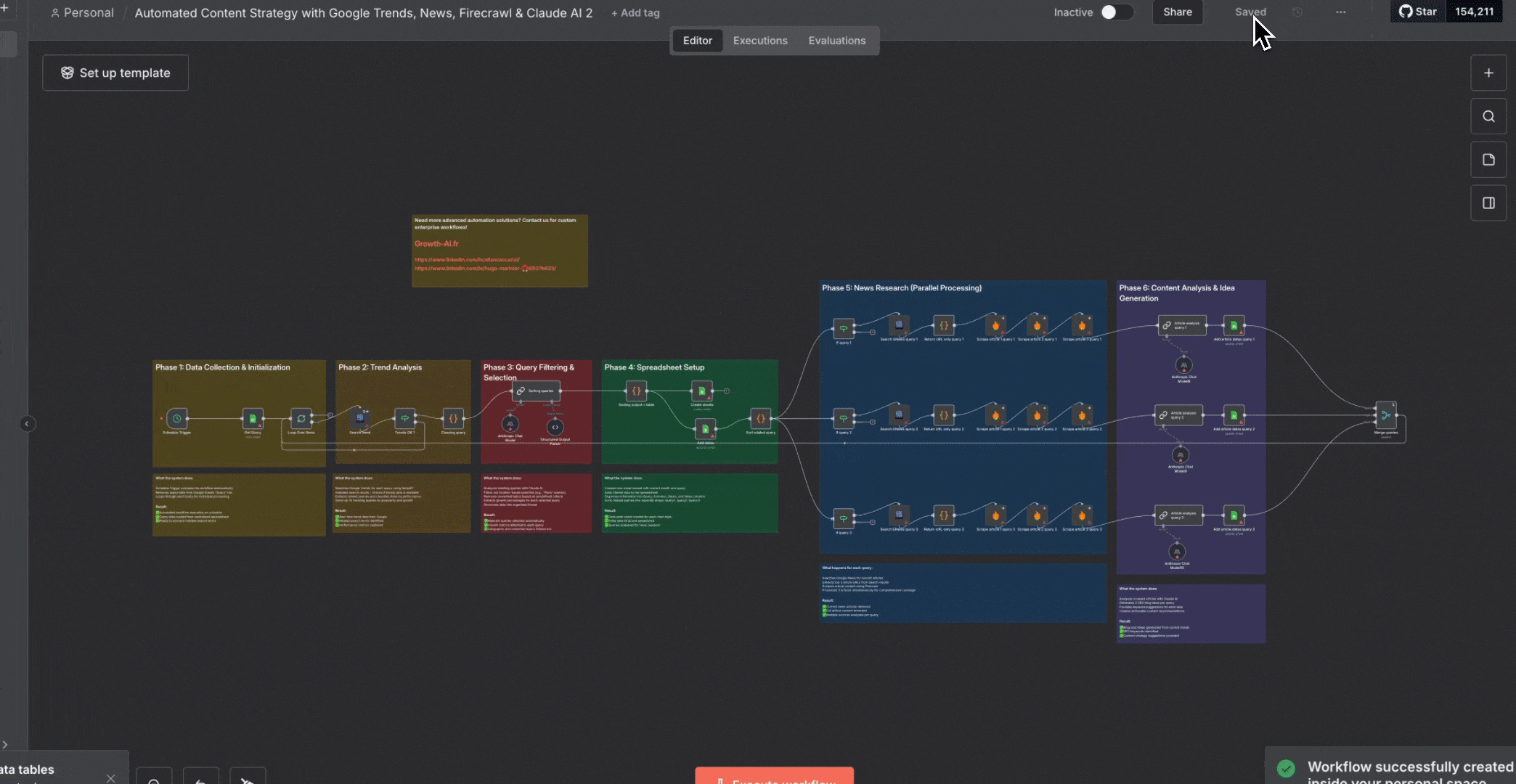
### 如何导入模板
要使用 n8n 社区的模板:
1. 点击任一工作流模板链接
2. 在模板页面点击“**Import template to localhost:5678 self-hosted instance**”按钮
3. 工作流会在你的 n8n 实例中打开
4. 为每个节点配置凭据
5. 按你的使用场景自定义设置
6. 激活该工作流
## 最佳实践
请遵循以下指南,构建可靠且高效的工作流程:
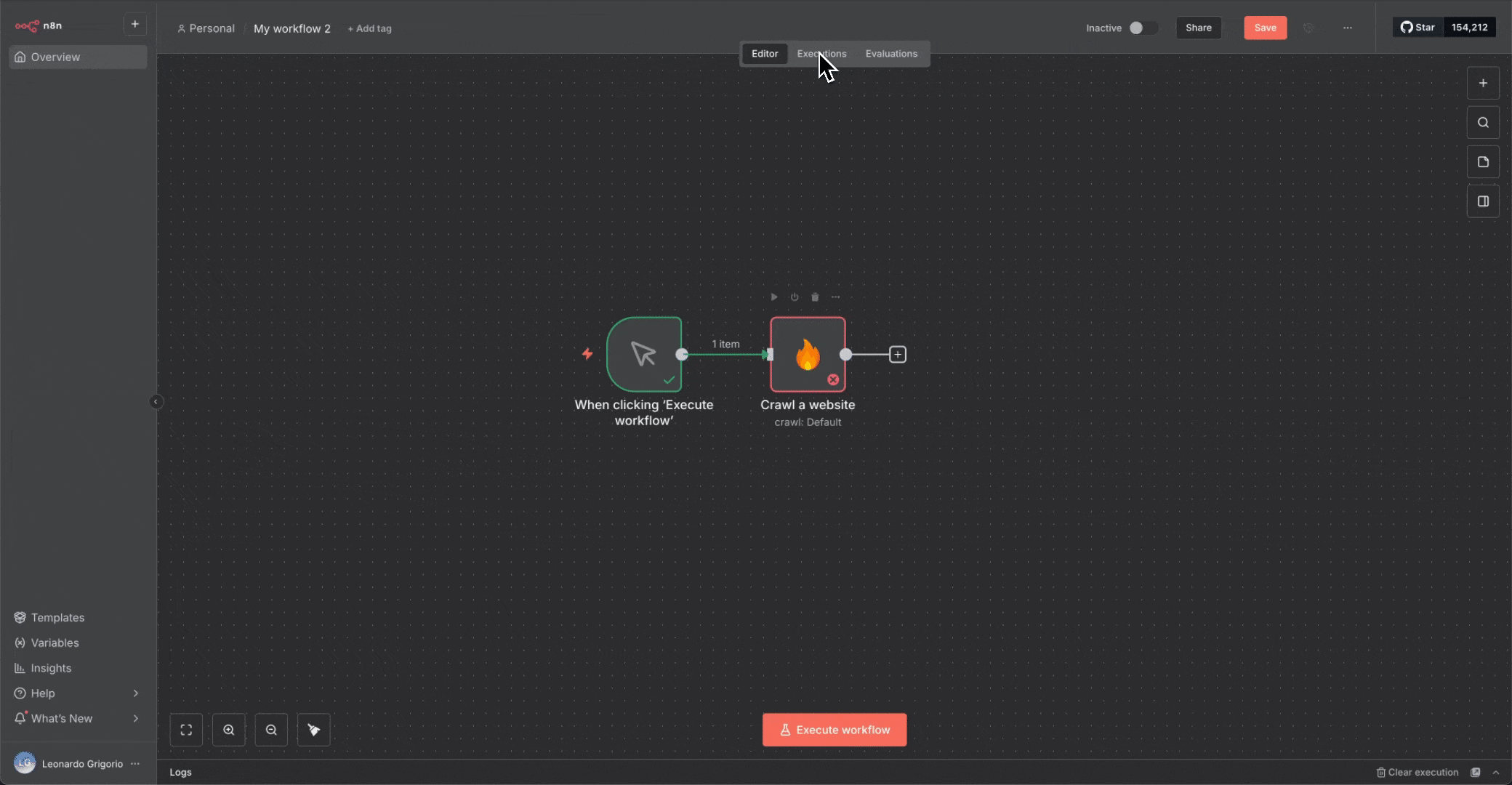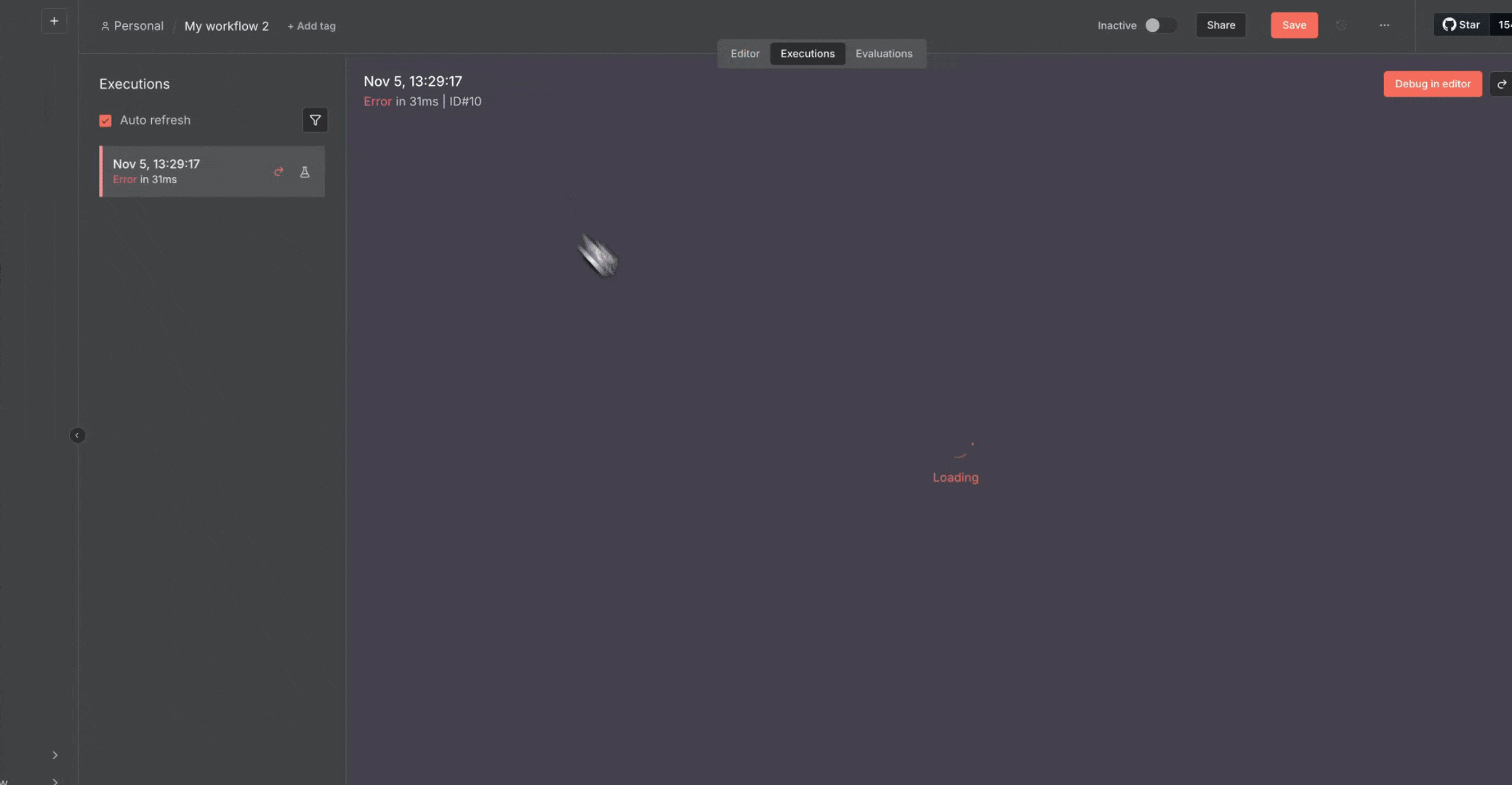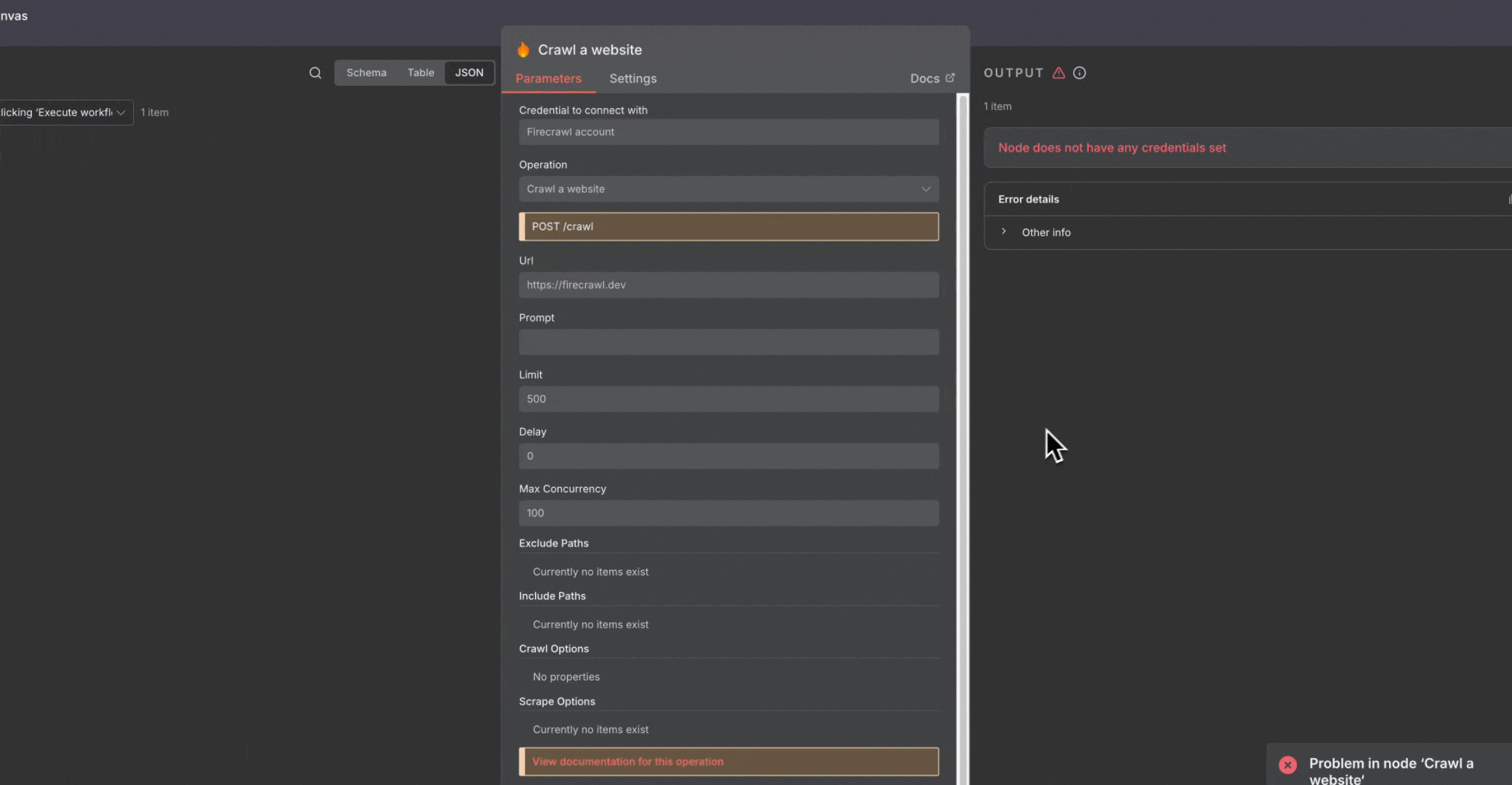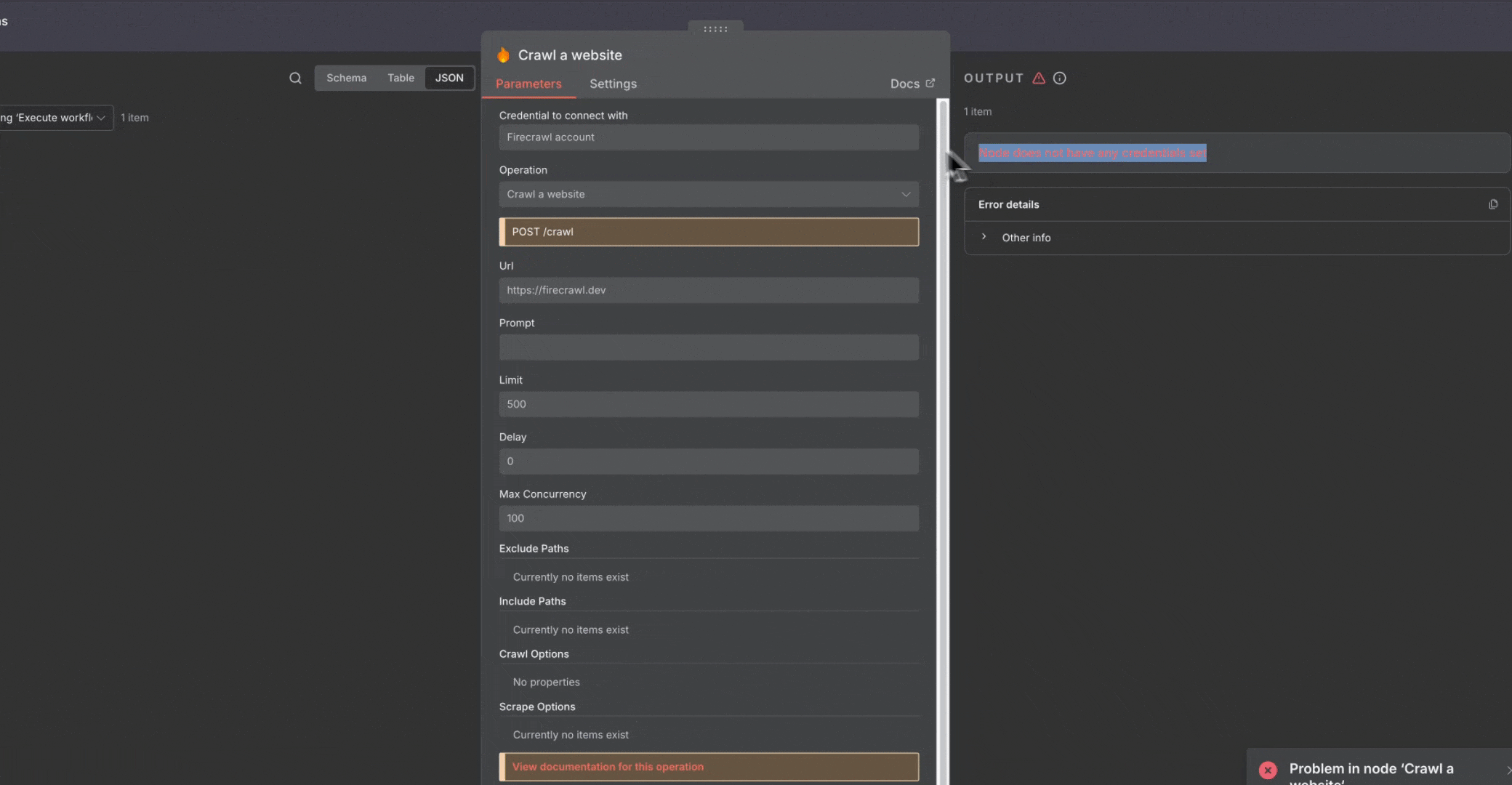
### 测试与调试
* 在启用计划任务前务必先手动测试工作流
* 使用“**Execute Workflow**”按钮测试完整流程
* 在每个节点检查输出数据以验证结果
* 使用“**Executions**”选项卡查看历史运行并排查问题
### 错误处理
* 添加 Error Trigger 节点以捕获并处理失败
* 工作流失败时设置通知
* 对非关键节点启用“**Continue On Fail**”设置
* 定期监控工作流的执行情况
### 性能优化
* 针对多个 URL 使用批量抓取 (Batch Scrape) ,避免在循环中逐一处理
* 设置合理的速率限制,避免给目标站点造成压力
* 尽可能使用缓存,减少不必要的请求
* 将高负载的工作流安排在非高峰时段
### 安全
* 切勿在工作流配置中暴露 API 密钥
* 使用 n8n 的凭证系统安全地存储认证信息
* 公开分享工作流时请谨慎
* 遵守目标网站的服务条款和 robots.txt
## 后续步骤
你现在已经具备使用 Firecrawl 和 n8n 构建网页抓取自动化的基础。接下来可按以下方式继续学习:
### 探索高级功能
* 配置并使用 webhook,实现实时数据处理
* 结合提示词与模式,尝试 AI 驱动的抽取
* 构建包含分支逻辑的复杂多步工作流
* [Firecrawl Discord](https://discord.gg/firecrawl) - 获取 Firecrawl 相关帮助并讨论网页抓取
* [n8n 社区论坛](https://community.n8n.io/) - 询问有关工作流自动化的问题
* 分享你的工作流,并向他人学习
### 推荐学习路径
1. 完成本指南中的示例工作流
2. 基于社区库的模板做修改
3. 构建一个可解决你工作中实际问题的工作流
4. 探索 Firecrawl 的高级用法
5. 贡献你的模板,帮助更多人
**需要帮助?** 如果你遇到困难或有疑问,Firecrawl 和 n8n 社区都非常活跃且乐于助人。构建自动化的过程中,欢迎随时寻求指导。
## 其他资源
* [Firecrawl API 文档](/zh/api-reference/v2-introduction)
* [n8n 文档](https://docs.n8n.io/)
* [网页抓取最佳实践](https://www.firecrawl.dev/blog)