Sync Data from Websites for Dify workflows
Firecrawl can be used inside of Dify the LLM workflow builder. This page introduces how to scrape data from a web page, parse it into Markdown, and import it into the Dify knowledge base using their Firecrawl integration.Configuring Firecrawl
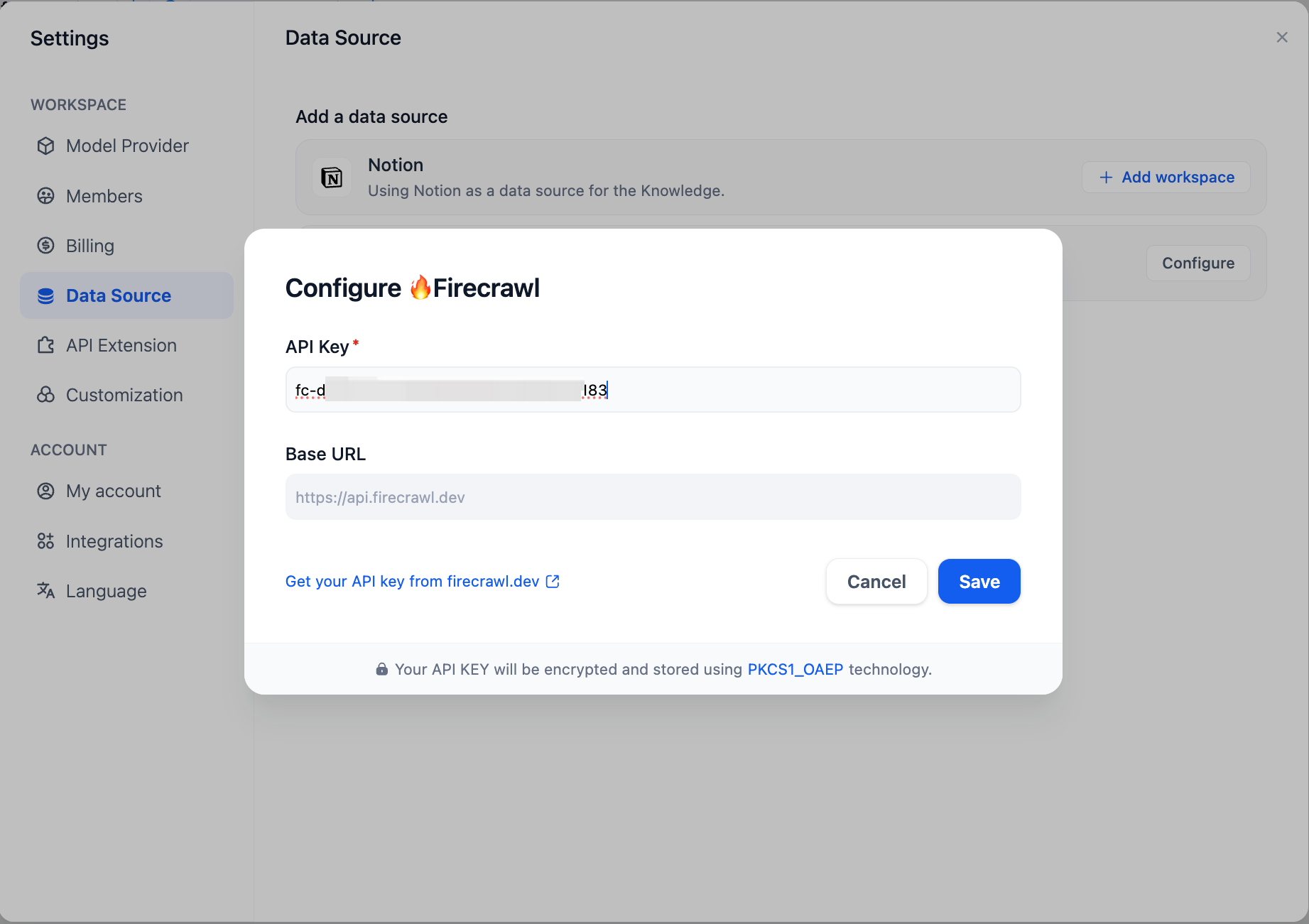
First, you need to configure Firecrawl credentials in the Data Source section of the Settings page.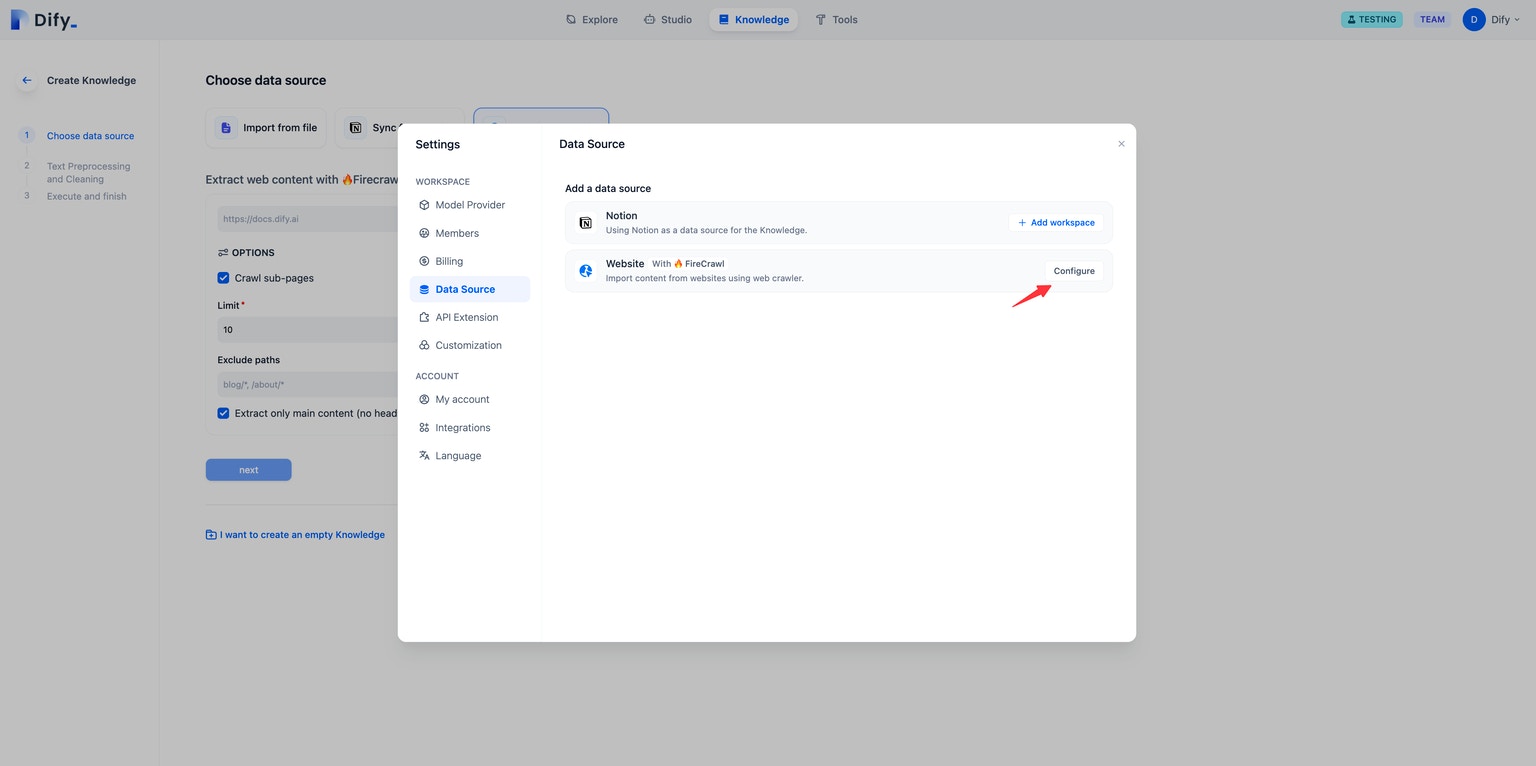
Scrape target webpage
Now comes the fun part, scraping and crawling. On the knowledge base creation page, select Sync from website and enter the URL to be scraped.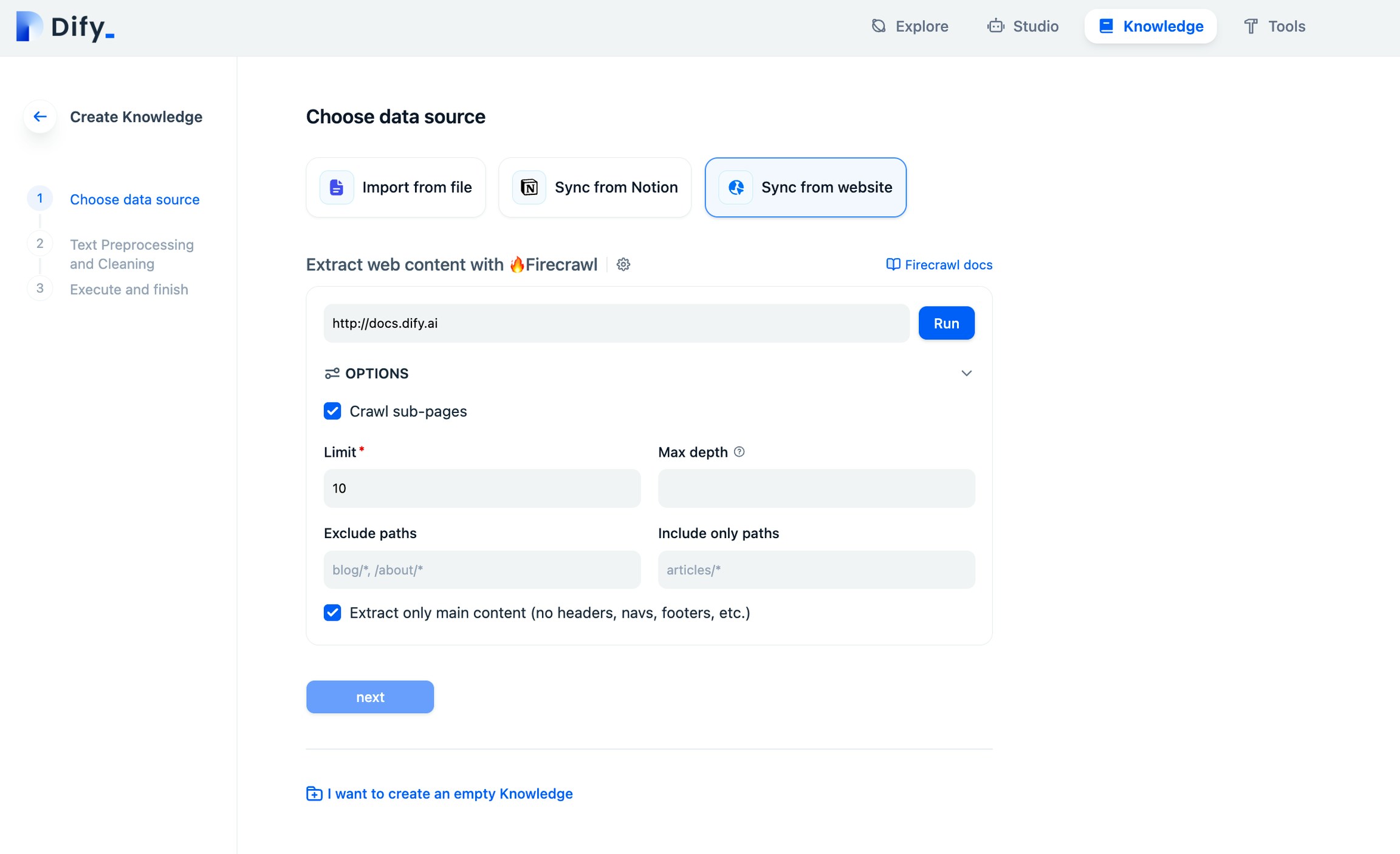
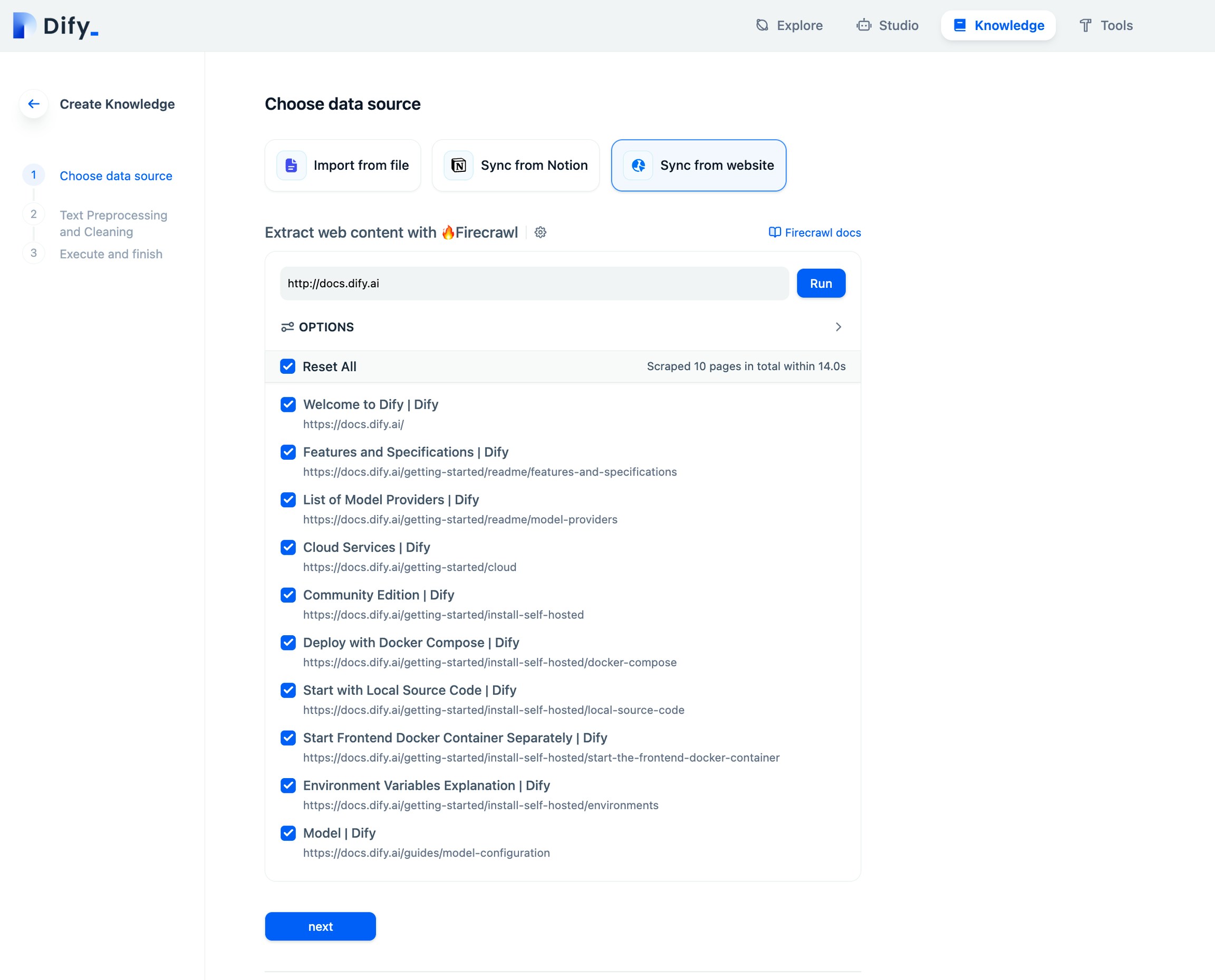
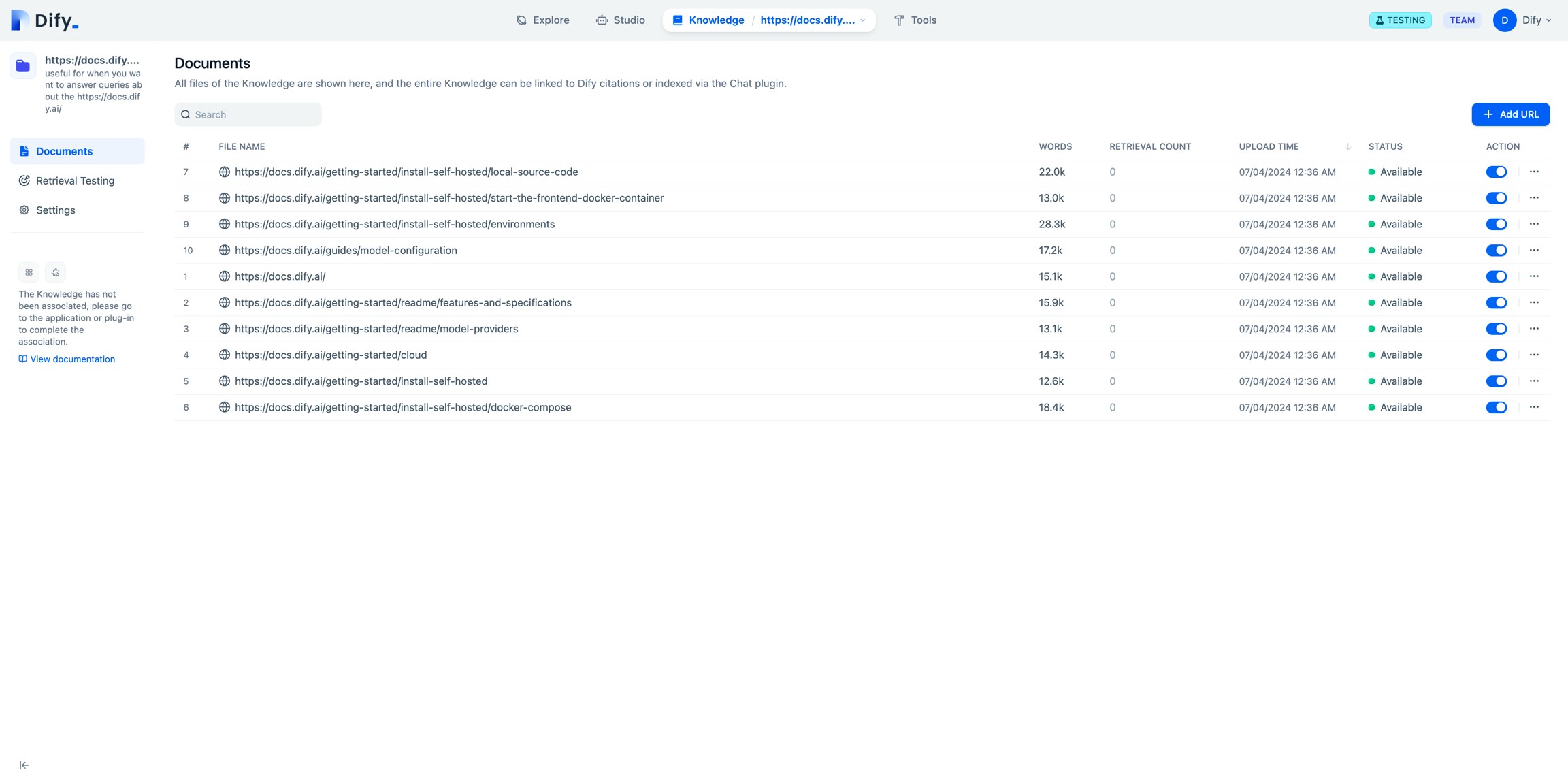
Review import results
After importing the parsed text from the webpage, it is stored in the knowledge base documents. View the import results and click Add URL to continue importing new web pages.